Transcript: CI Hardening, Continuous Fuzzing & Cross-Component Streams
wasmCloud Weekly Community Call — Wed, May 20, 2026 · 47 minutes
Transcript
Liam Randall 05:14
Yeah, sure. Happy wasmCloud Wednesday, everyone, for May 20, 2026. We've got a couple items to run through on today's agenda. We're going to start with an overview of our new community meeting notes, and then I think we're going to have a demo and discussion with Aditya today. Aditya, I'm happy to start with my demo of the new community notes — or do you want to start with your demo?
Aditya 05:40
I think I'll require a bit more time, so you can go ahead.
Liam Randall 05:44
Sure. One of the things we've been thinking about doing with wasmCloud is making the community meetings a little bit more accessible. We've been running wasmCloud Wednesday meetings for quite some time — I want to say it's now five years of meetings, or somewhere near there — and we took an opportunity to start generating AI summaries of the meetings.
So now there are two documents that are automatically created for each meeting. The first is an AI-generated summary that summarizes all the key takeaways and gives you hot-links to the various points of the discussions, the demos, and the videos. We hope this makes the discoverability of the discussions better — honestly, some of the best discussions we have around not just CNCF wasmCloud but also WebAssembly are in these calls, so there's a lot of great information that should be a lot more available. And then for each meeting there's also a transcript that's linked. I'd love any feedback on this. We've completed all the meetings through 2026; in the next week or so I'll get 2025 across the line, and then we'll make a decision around 2022, 2023, and 2024 — we may cut a couple of these, because there have been so many architectural evolutions in wasmCloud that we want to make sure we're putting the latest and most accurate information out there. Any questions or discussions on the new landing pages for past meetings?
Frank Schaffa 07:42
I think this is great. And what you mentioned about not going back in time makes sense, because things have changed so much. If you want to have the history, you can do that on your own. I think this is a good addition.
Liam Randall 08:09
Yeah, I'll be honest, I've found myself using this even after I made it. I was working on a few demonstrations getting ready to release — demonstrating some of the GPU features and other things — and it was very powerful to be able to come in and click right through the TensorFlow.js demo with Mendy. So, not to be too recursive pulling up wasmCloud Wednesday on wasmCloud Wednesday, but it's just been very helpful to rediscover the information so much faster.
Aditya, just let me know when you're ready. I'll fill some time to give you a little more. We're getting ready to cut wasmCloud 2.2. If you've been following along, the rate of pull requests has climbed pretty dramatically in 2026, as well as the rate of features. Bailey just finished some huge spikes around CI hardening, many of which were discussed in last week's meeting — which you can find on wasmcloud.com/community really easily now. And this week there were some additional changes in CI as we evaluated feedback on how we were going to release wasmCloud 2.2. Bailey, any comments about wasmCloud 2.2?
Bailey Hayes 10:01
Maybe I flew too close to the sun making lots and lots of CI changes. Last week I landed staging gates, which broke my release flow — the staging gate said, "oh hey, you didn't change this code, so I'm going to be really smart and skip this," but we actually needed it for our release. So I've been working on improving the release pipeline, because we have an automated release pipeline that basically regressed from the staging gates. I should have all that fixed in the next hour, and then 2.2 will go out.
In terms of CI hardening, we have a lot of sweet stuff. We threw it up to CodeQL and got some metrics reported, but we weren't getting all of them. A couple of interesting things I learned: in our Rust codebase, because we have so many examples and templates, about 50% of our code is Rust macro expansions, and without a pre-warmed cache before CodeQL runs, it can't inspect that code — so we were getting low-quality metrics for our Rust code. We were at 49%; hilariously, if we'd been 1% further it wouldn't have flagged that, but because it got flagged, I figured I'd fix it.
So I've been iterating through CodeQL and the stuff flagged by the OpenSSF Scorecard. When we first added it, there were something like 60 things flagged, and now we're down to about 11, and I'm whittling away at that. One of the things flagged is that we don't have continuous fuzzing, so I started working on our fuzzing story. There's a PR up right now for fuzzing our runtime controller. If you look at Istio, cert-manager, Crossplane, and a handful of other operators or controllers in the Kubernetes space, they use Go fuzzing to test the places where they interact with JSON or do merging of specs, because that stuff can be tricky and cause panics at runtime. So I focused our fuzz testing around host interfaces specifically, because that's where things get the most interesting.
I ran it overnight. It found a few different kinds of bugs, but none of them were actually from the fuzz tests — it was the authoring of those tests where I found bugs; the tests themselves ran fine and clean. To complete our fuzz-testing story, I think it should look more like reusing what Wasmtime does and reusing some of that corpus against our host. For the most part we're covered, because Wasmtime does this robustly and continuously, but we have a layer above where we take those bytes, parse them, look at the interfaces, and feed them down — so we should be fuzzing specifically that layer, and we should be able to reuse a lot of the existing testing infrastructure and map it over for wasmCloud's host story.
Colin Murphy 14:06
I had this story with wasmCloud 1.0 — I went through it and ended up either fuzzing NATS or Wasmtime. But I can see now that we have Kubernetes stuff, that actually makes a lot of sense as what you'd want to fuzz.
Bailey Hayes 14:22
I think it's that layer, and also in wash runtime's layer for the workload scheduling, where we look at the graph of the workload — that's the equivalent layer in wadm. So I think it's worthwhile to hit that layer. It's lower priority than some of the other features, especially given that the sandbox itself we don't mutate or change — that's fully Wasmtime, so we know that's well fuzzed. Sorry, that was a bit of a ramble.
Liam Randall 15:04
Bailey, in thinking out loud there, is it your assessment that we should onboard into Google OSS-Fuzz? Or do you think there's another solution that will solve it in a more simple way?
Bailey Hayes 15:19
OSS-Fuzz is amazing. When I ran all night and didn't find anything, that's not enough, right? The thing with continuous fuzzing is that you continuously do it, and as you make changes, new code introduces new problems and new panics. But I'm also pretty confident it wouldn't find anything, so the priority of getting us added to OSS-Fuzz is pretty low. These Go fuzz tests run in our CI, so they're continuously tested — just run make test for the runtime operator and you'll get it. We could add it to OSS-Fuzz, because Go's fuzz format is the same, and technically you'd get stronger control. But most people who go through the trouble are folks like cert-manager doing it in security-critical contexts. So for us, yes, we can do it — it's now in a place where we could — but do I think it's the most important thing? Probably not.
Liam Randall 16:37
I was looking at CVEs the other day, and it's amazing — you can see this huge spike in 2016 when projects started to onboard into OSS-Fuzz, and the types of vulnerabilities that were discovered. The next big spike on the chart for these systematically critical products is the recent Mythos reviews. I recently posted a blog about Wasmtime's use of some unnamed LLM model to do discovery of some vulnerabilities, and it was shocking that — even though they do everything possible: OSS-Fuzz, cargo audit, all the steps you'd take in the best world — they were still able to discover some very interesting vulnerabilities. I think us retroactively going into that would be a great idea, but I also understand it's not the current peak priority.
Bailey Hayes 18:05
Yeah, the things I effectively ended up fuzz testing are the same things other people are already actively fuzz testing — it's almost identical to some of the Istio fuzz tests, because I based it on how they were fuzzing for a CVE they had discovered. So effectively they're fuzzing the same thing continuously. I'm not saying I'd be against it — if somebody wants to do the work, they're welcome to.
Liam Randall 18:34
I also think you made a great point that we get to inherit a lot of the security configuration and testing from Wasmtime. When you think about the most dangerous part, it's where we run other people's code — the untrusted code. That's a very good observation. But the TL;DR, as the Notorious B.I.G. song goes, is no code, no problems. Now I'll never be invited back to host again.
Colin Murphy 19:08
Sorry — which post was that, where they did that with Wasmtime?
Bailey Hayes 19:13
If you read on the Bytecode Alliance org news, it's like the second most recent news article. That one was really great — Pat Hickey wrote it. We also did an analysis and a hotter take of it, if you want to read it on the Cosmonic site; that's our most recent blog post.
Colin Murphy 19:32
Oh, I see. So it's the April 9, 2026 advisories.
Bailey Hayes 19:36
Yeah. And I will say, you don't need Mythos to let an LLM rip and find vulnerabilities. I've done my share of running Claude in a lot of different places, and I've run it on wasmCloud as well. I welcome other people to try it — it's pretty easy. You can really find stuff with 4.6, 4.7. The only difference is a jailbroken model is a little more willing to do evil things, but you can still say "I'm a security researcher" and 99% of the time you get around it. Anyway, that's it for that.
Bailey Hayes 20:20
There were four-ish CVEs that were medium, basically — they weren't huge, they were in more esoteric configurations and edge cases. For a lot of the other projects out there they're pretty big. The other thing I know is that at Pwn2Own, which I think was last week, Firefox participated and there was one finding, but it was one that had already been fixed. If you're into this, you should read Bobby Holley's blog post on the Mozilla org, where he argues that these vulnerabilities are finite — you can find them and fix them all. It is possible.
Liam Randall 21:16
I've linked these in the chat. And it seems like Aditya, you're ready for your demo — so if you're ready, we'll hand off to you.
Aditya 21:41
Thank you. I'm not sure how many of you are following our weekly community meetings, but there's one particular pull request I've been working on that allows your service component — or any component — to essentially tunnel its way out to your host OS port, through explicit port definitions. So what's changing if this gets integrated: there's going to be a new definition space for sockets where we create individual rules for the sandbox port. Essentially, any socket attempting to connect to, say, port 5432 is going to get redirected and connect to a different port; but if it's a plain sandbox-port mapping pointed at, let's say, 3306, it's going to allow it to reach your own host's network space and connect there. Earlier this wasn't possible, because the TCP sockets were being looped through a virtual network space.
So I did some tinkering with Claude and our Cosmonic skills, which have all the beautiful color combinations available — check it out and make some good stuff — which essentially turns into a to-do list platform. Instead of just showing you, I'm going to demo this real quick. Can you all see this?
Liam Randall 24:15
We see your VS Code window.
Aditya 24:17
Yep. I'm going to go through a bit of code. We're in the SQLx socket — this SQLx is a fork I'm working on that composed its transport layer to use WASI sockets instead of Tokio. I have a config.yaml that has this rule set allowing it to connect to port 3306, and I have an HTTP component that starts a WASI HTTP server and lets you call stuff and connect to a service-lead component, which does the connection pooling to your database URL. In this case I have my database running on port 3306 with a pretty plain password. This is a function that runs once and initializes — completing the table setup — and after that there's a handler that keeps the service component alive and listens to various components.
So once you have this running, it's on localhost. I had some to-do list items made in advance, but we can add what needs doing — "take some me time," that's fun, because I'm sure we all need some me time — and that gets added here, and even on a refresh it's still there. If you mark it done, it marks that permanently as true, even if you refresh. So that works. I also have a bunch of filters — it does a table join and returns these results. And I've got a pretty cool view of the live table, which refreshes every three seconds. That's pretty much it. Any questions?
Bailey Hayes 27:12
It looks really nice, Aditya.
Liam Randall 27:18
I think it looks great. Will that be submitted to the wasmCloud demos as an example? Is that the plan?
Aditya 27:27
Yeah, that's absolutely the plan. I have it in a draft pull request — I'm going to make it ready. Hopefully Brooks can help us out if he's watching.
Liam Randall 27:41
Yeah, Brooks dropped in the other day and let us know he's coming back from his little break and is going to look for a couple of good first issues. We all miss Brooks. It's great to see the excitement and enthusiasm in the wasmCloud ecosystem these last few months — a ton of people have all come to the same conclusion that AI-generated code is already the reality, and they have to leverage it to go fast, but they don't necessarily trust the outputs. So they're looking for runtimes that finally solve the problems around ambient authority and principle of least authority, and are secure by default. We've seen a pretty rapid influx of folks picking up and using wasmCloud, and I think it should continue to scale nicely through the rest of the year. Welcome to any new users and watchers at home — always feel free to join us at slack.wasmcloud.com or participate in the community meetings linked right off wasmcloud.com, every Wednesday at 1 o'clock. Eric, do we have a doc of the week? I feel like you publish nonstop.
Eric Gregory 29:04
We've been landing a lot of stuff, but much of it has been focused on the community page and the SEO improvements lately. Maybe we'll come back next week and highlight a few more operational docs that folks can take advantage of.
Liam Randall 29:21
Great. And hopefully no one's been too inconvenienced, but we've been making a lot of updates to wasmcloud.com to improve the overall structure, make things more discoverable, deprioritize older content, and raise the priority on newer content — some maintenance, like converting a lot of the old large images to WebP format, and making sure all the social graph tags are configured on the website. You can follow along in the pull request history; we've been tagging them as SEO, and there have been some pretty large PRs. Eric, we're so grateful for you triaging all of those ideas and making sure it lands in a way that's still easy to navigate. Open call — is there anyone else who wanted to share on the community today? Going once, going twice. Go ahead, Aditya.
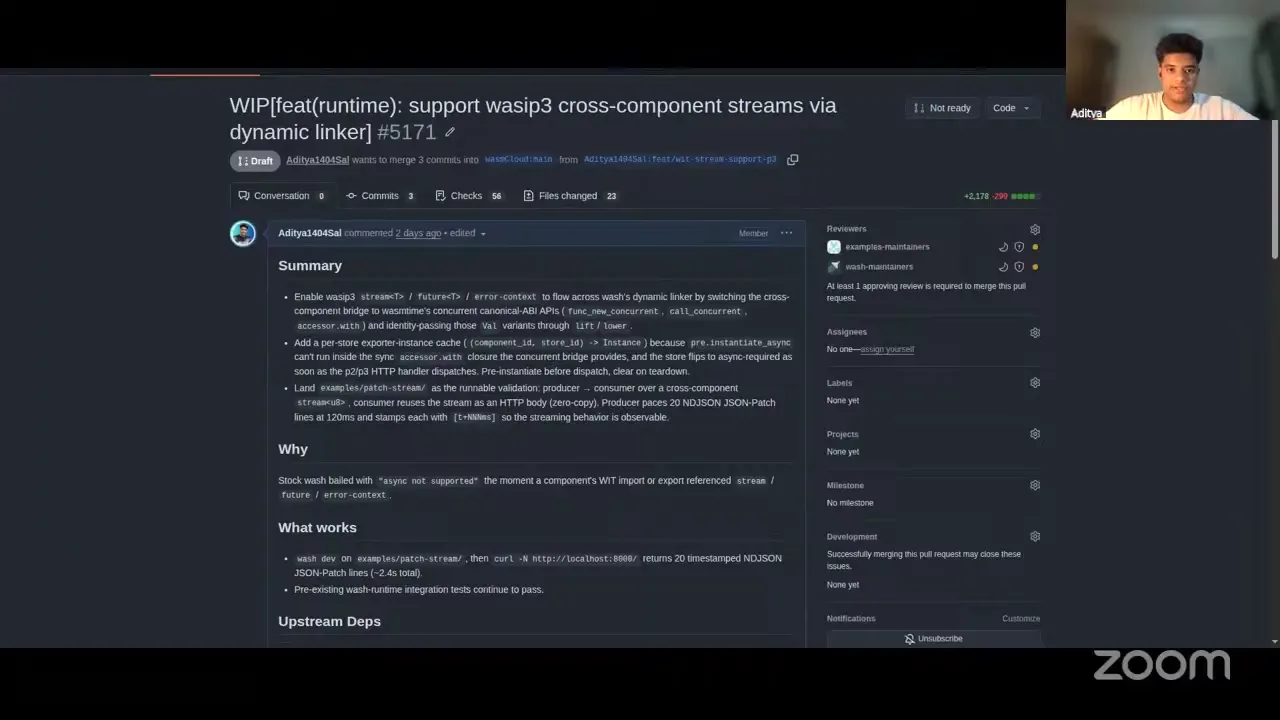
Aditya 30:34
This is related to streams and futures — I'll share my screen. If you try to create a component setup where you create your own stream and communicate between two components — for example, you create a stream from an exporter component and get the result back to your initiator component — that didn't work in wasmCloud, because stream, future, and error-context are not supported by Wasmtime's dynamic linker in the lower sections of the store context. This PR is seeking to add that support so there can be cross-component stream communication between two components. I'd love for people to give their initial opinions. There's also an upstream pull request I created on Wasmtime, but essentially we just want to add async compatibility with streams and futures to our wasmCloud P3 space.
Bailey Hayes 32:29
A lot of that comes from the linker in Wasmtime. The way we work right now: we have a workload definition with one service, which you can think of as the front door to the workload. If you want to use it as your router to the other components, you can; if you want it as the primary egress point for WASI socket connection pooling, you can use it for that. But you can also not have one and have the host route straight to a single component. If you have a workload with multiple stateless components — reactors, serverless components — those components can also talk to each other today, so you could have one that's good at operating on one resource and another for a different resource and link them. The intention of that feature is to make it easy for people to do that.
I have another crazy change I haven't shown off yet. The original architecture design intends that components potentially have different lifetimes — a request comes in from a service, hits component A, and component B doesn't do anything. But reality doesn't quite match that, because if component A needs an import from component B, both A and B have to be instantiated. The other reason we wanted this architecture is that in the future there's going to be a component-model feature called runtime instantiation, where our service acts as the root component and the whole thing is composed together, but I only instantiate what I need when I need it.
So the thing I'm thinking about for what you ran into, Aditya: what if we just compose the components instead of using the Wasmtime linker API and the val type? If we said, "thanks for that workload, let me smoosh it for you," now you get a composed component and all of that goes away. Not only that — part of the reason I've been on my benchmarking hobby horse is that I found it improves performance by 5x. So that problem goes away, because the composed component obviously knows how to pass these async streams, and if you're on P3 it composes and wires it all up correctly. You don't need wash runtime to say "I've got this val type and I'm going to do a link over here and this one's async, let's wire up the stream" — you don't have to, because it's built into the component model.
Aditya 35:57
But would that support, let's say, I create a resource and I also want to stream that resource — will I be able to do that if I compose the components?
Bailey Hayes 36:07
Yes. Where it wouldn't work is between the components in the workload and the service, because what I'm proposing is composing all the components in the components field, but not composing them with the service — the service still needs to be long-lived and stateful, with a different lifetime. I see Chris's question in the chat: how would composing impact scaling? Great question. It means components in a workload now scale together. The diabolical case is: I have 50 components that have nothing to do with each other, but I put them all in the same workload and treat them as one tenant, and now I'd be coercing them into a single component without much benefit. I think we could handle that edge case separately — are they talking to each other? No? Then we don't compose. It makes the logic more complex, but for somebody in that diabolical case, I'd recommend they create separate workload deployments, and it would have zero impact on their scaling. Honestly, if you swallow the full vision — that one day we'll have runtime instantiation and a workload deployment is a component — it's more semantically correct to have them be separate workload deployments anyway.
Aditya 38:32
So if we do separate workload deployments, wouldn't that be a transfer over TCP?
Bailey Hayes 38:43
If they're not talking to each other, in that diabolical case, then they still aren't talking over anything. If you're talking about the scenario where all your components talk to each other over a virtualized socket, then maybe, yeah, probably. But I have another idea: if they're all talking over, say, HTTP, we could do virtualized host routing — I filed an issue for this. We keep an in-memory map of all workloads deployed on the same host, and if they're all on the same host and you've opted in, we say, "I'm not going to drop out to the network for this; workload A is talking to workload B, let's just call that handler." There are downsides — if your reverse proxy is doing extra work like passing the right headers — but if you're counting on it all being in the same workload, you don't need to bounce out to the proxy. So the answer is: make sure we have enough picks and shovels for people to build the right platform, with a lot of customization options depending on how they run their workloads.
Aditya 40:22
Yeah. And even without composing, I ran into a problem where we're only able to transmit u8 bytes and no other complex types, because that doesn't work in Wasmtime — I believe it's the resource tables that don't agree with each other.
Bailey Hayes 40:47
If they're on different stores, that can be tricky, but the way we cheated is we put them on the same store. So in theory I think we can make that work — and that is more code. So, what if we had no code, and it was five times faster? That might be better.
Bailey Hayes 41:13
I want my "Are We Fast Yet?" update. I was waiting to get 2.2 out so I can land the benchmark — I've got the reviews on it, we're ready to land. I do expect an iteration loop, because with GitHub Actions you have to pay the tax: you introduce a new workflow and now you must run it 30 more times before it works. So I'll put in my tax this week, and we should have it next week. Right now it's just a GitHub page — you can get to it at wasmcloud.github.io/arewefastyet, but it doesn't matter because it doesn't have data yet. Once we land it and start running it, I can do the host component plugin change, the HTTP routing change, and the HTTP instance reuse change for P3 — I just don't want to make these sweeping architectural changes without really good performance benchmarking and metrics around it.
Liam Randall 43:11
Thank you so much, Bailey. That's the kind of discussion I'm so glad we're going to surface better in the wasmCloud Wednesday notes. With that, maybe a final call for any more topics today. Going once, twice. A final reminder: KubeCon submissions are due May 31, so you've got 11 days left. As always, if anybody's interested in collaborating or wants feedback on their submission as it pertains to CNCF wasmCloud, we're always excited to help get talks across the line. Aditya, what's up?
Aditya 43:50
So I'm going to be attending KubeCon India, which is happening June 18. I'm game if there's any opportunity to represent wasmCloud.
Liam Randall 44:03
We've had the project pavilion booth at EU and US. I don't know that we've ever had one at KubeCon India — maybe offline on the wasmCloud channel I'll pick that up and see if we can get one organized. It's a lot of fun; you get to sit and spread the gospel, and we've got a couple decks we've used there.
Bailey Hayes 44:24
I was going to tell Aditya: careful what you ask for. You ready for some booth duty? It's a really good time.
Liam Randall 44:32
The CNCF prints off wasmCloud stickers, and in the past we've brought small boxes of multicolored shiny stickers and some hard-copy literature. I don't know what it costs to ship a box to you, but I'll check. I think it's still George who owns that — I'll ping George on the CNCF Slack and see if it's not too late for us to get some representation there, since I believe we might have missed the call to action.
Bailey Hayes 45:32
Are you speaking, Aditya?
Aditya 45:35
I am, unfortunately, not. I didn't want to apply because I had my exams right on that weekend, but they got moved up, so I'm free now.
Liam Randall 45:47
Well, that's exciting. I'll loop you in after I talk to George. I'm not sure if we've gotten you a wasmCloud shirt — let me see what shipping would be, and if not, I can send you the design files so you can have one printed locally.
Bailey Hayes 46:34
We should also look into the maintainer track for Aditya. They have some free-time stuff we could probably sneak into.
Liam Randall 46:44
Awesome. So it sounds like we had a couple things to do — let's pick this up on wasmCloud Slack and run it down from there. All right, thank you, everybody. Have a great Wednesday. See you next week. Bye bye.