Transcript: wasmCloud CI Hardening, Cache Pre-Compilation & Benchmarking
wasmCloud Weekly Community Call — Wed, May 13, 2026 · 38 minutes
Full Transcript
Bailey Hayes 04:59
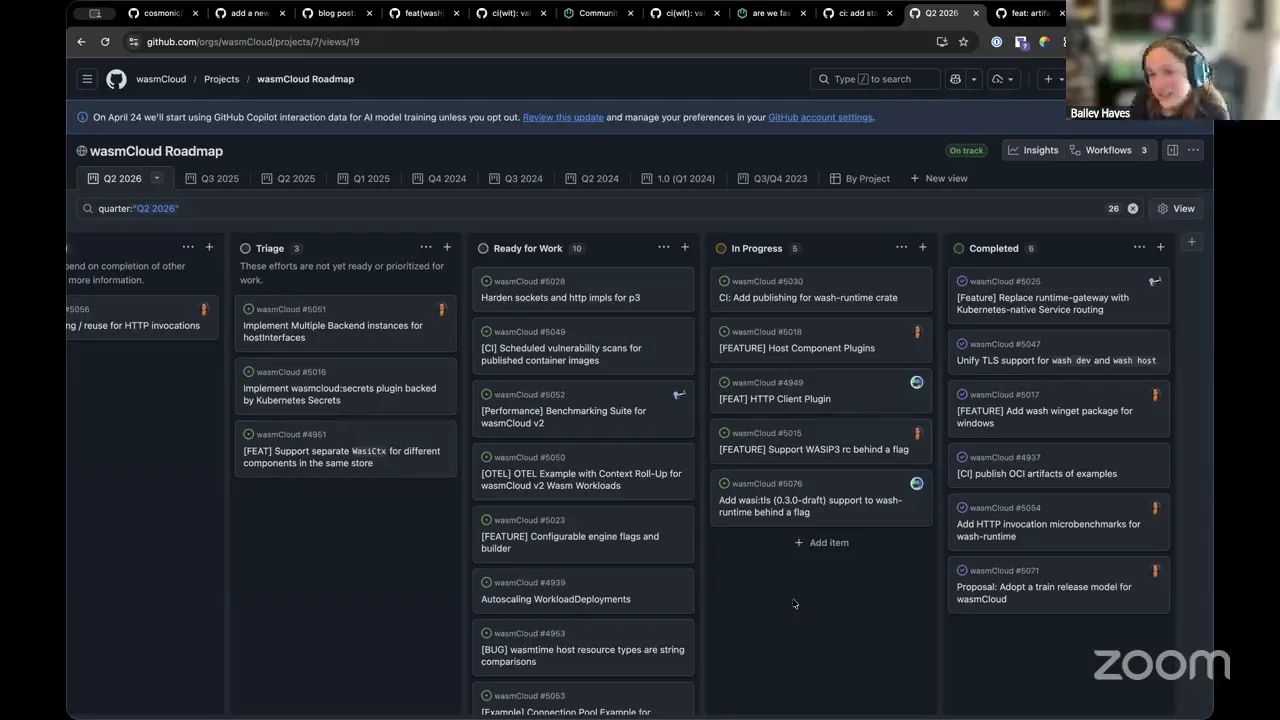
All right. Give Zoom a couple seconds to get started. Hello and welcome to our May 13 community call. We have a decent sized agenda today. I'm not going to say it's big, but it's also not small. So right now, we're going to first go through our roadmap, because we've got a bunch of things in flight, and I want to also call out a few other things that I think folks would generally be into.
So first, let's take a look at our roadmap and kind of assess where we are. And as a reminder, we've got basically half of this month and a whole other month to get this full roadmap complete. So ends on July 1 for our Q2. So far, we've landed a ton more than just what's here. This is specifically what we plan to land as part of our roadmap.
We've got our Windows packaging story completed, we have our OCI artifact example as of this week now, building and publishing. So essentially, now we have an automated process for any time we add an example and we rev its version, we'll go and publish that example to OCI — that landed this week. We've got our train release model fully automated. We've run a successful automated train release.
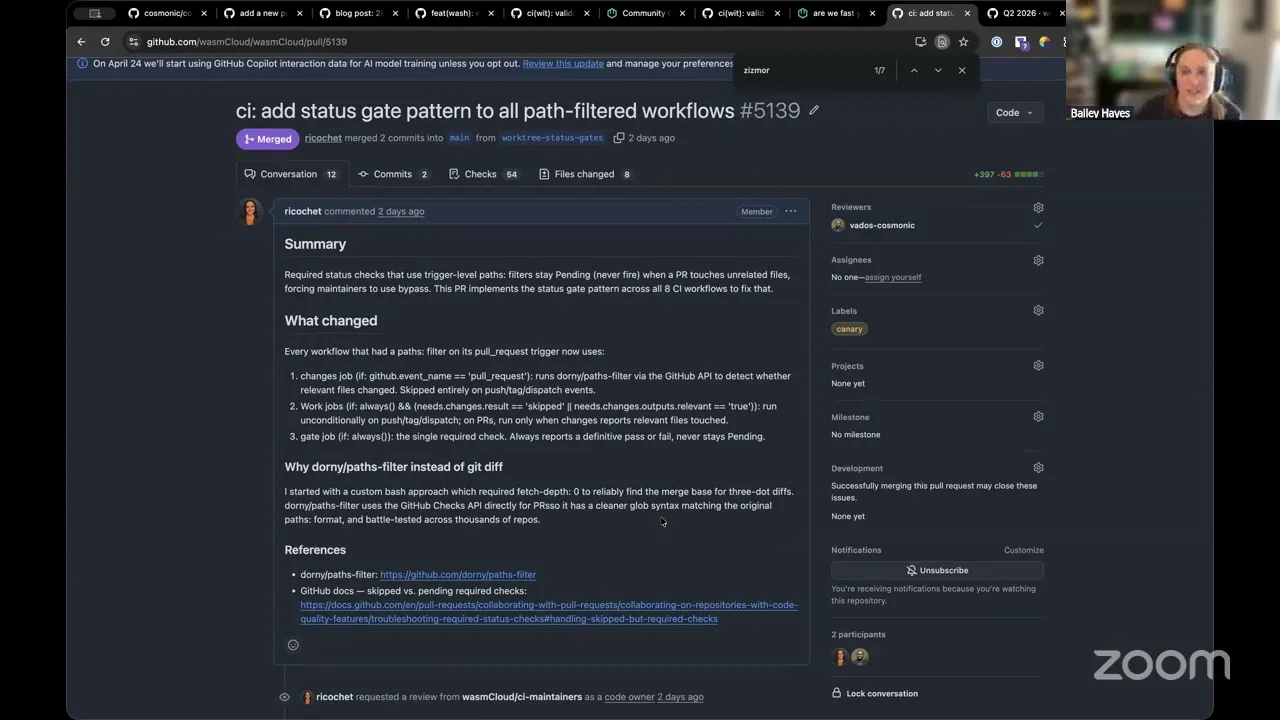
We've done a ton of work in terms of hardening our CI. I think that's probably something that's worth diving into a little bit here, but essentially we have, as of this week, I think I'm largely hands off now on doing a lot of my major CI changes. We have things like linting our workflows, both from a security perspective, but also just like from an action lint perspective, we're using this tool called zizmor. And if you aren't using this in your own workflows, I can't recommend it enough.
I don't know if folks realize that this week there was a mini SolarWinds-style attack again in the npm space. But if you were using zizmor and you fixed the errors that it tells you to fix, one of those things is called pull_request_target, which is what folks were using to do a supply chain attack. And zizmor will call that out as basically every use case of this is unsafe, and you shouldn't have it in your workflows at all. So we've gone and fixed all of our zizmor errors. And because this is in place, we'll continuously always catch that every time we update our workflows.
The other things that we've added, I guess, is making sure that we're really explicit about the permissions that we use — so in just about every workflow job. Now, whenever you look at it and pull it up, you'll see that we disable permissions by default everywhere, and then we're very explicit about what each job does for each one.
The other thing that landed this week that I think folks should be aware of is that we now use status gates for our changes. So now we're basically using a status gate pattern. So if you make any contributions to our CI, make sure that you add at the bottom of your job basically a gate. And we use that name specifically in our configuration for our CI to basically say, should we block the merging of this PR. And now, basically, if you make a PR at the end here, you can sometimes opt in to auto merge. You can do that safely with our CI now, because we have basically a gate that is validating whether or not all these checks have passed.
One of the big issues with GitHub CI, it's kind of hokey. The way that you have to work around this problem is that basically, if let's say you added a job for Rust validation, but then Jeremy went and made changes in the runtime operator, I couldn't have a status check for Rust and Go always requiring to be met before merging, because he only touched the Go side. So this is the established best practice for how to work around that, and we have it in place now, which is nice.
We have cryptographic attestations for all artifacts. Initially we had it just for the wash binaries. Now we also have it for all the OCI artifacts that we're publishing. Oh yeah, we added cargo audit. We added OpenSSF Scorecard. We've got Dependabot back on. And yeah, so I think from the CI side, we're appropriately hardened, and so I wasn't too stressed when I saw the mini SolarWinds pop up, because I knew that we were already protected. But I know a lot of other folks had to do quite a bit of scramble early in this week.
So one of the things that we are missing right now is publishing our wash runtime crate. We're not able to do that until all of its dependencies are published to crates.io and right now we have a dependency on WebGPU, and that one's not yet published. So once that is published, we can start publishing the wash runtime crate. And then I want to hand this off to Aditya, because he has two changes that are basically about ready to be merged, and so we should land them this week.

Aditya 11:56
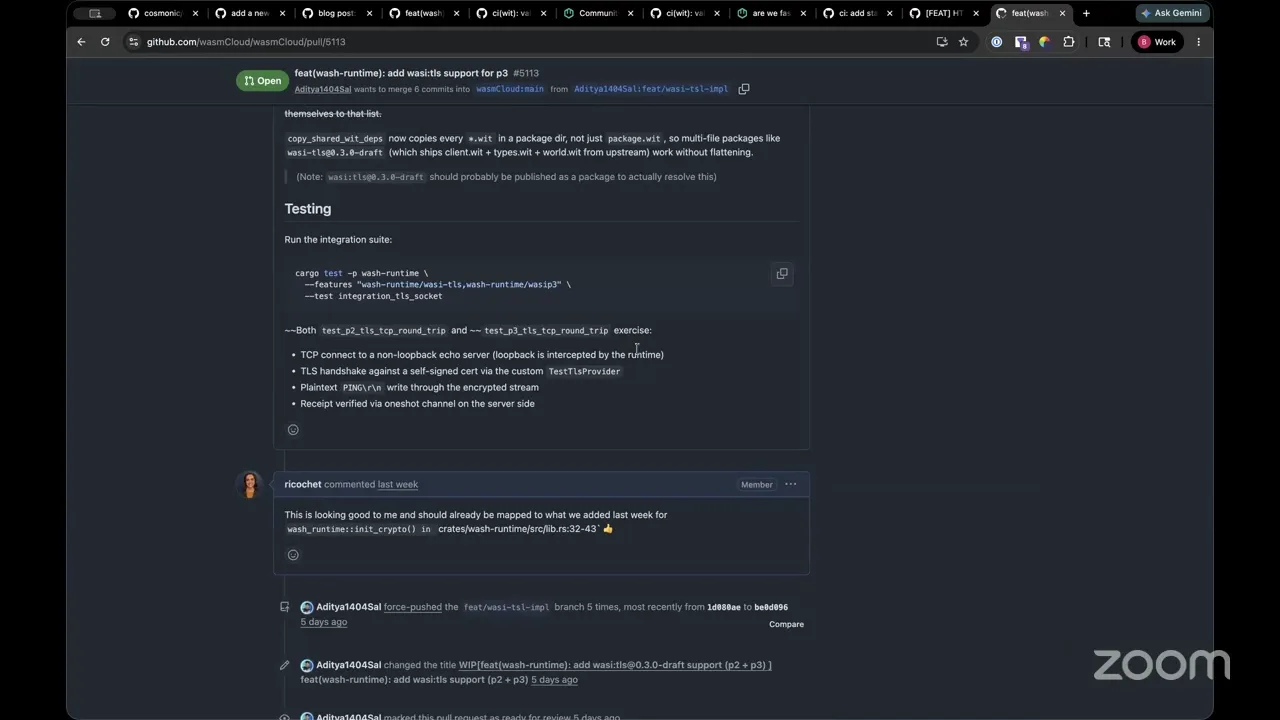
Hey guys, so I've been working on adding an outgoing handler trait implementation that is essentially going to allow anyone to implement their own custom outgoing handler in the HTTP client. And this is because there's been a few cases where people need their own custom implementation for their own CA certs and custom TLS implementations. And this is basically going to allow your P2 as well as P3 interfaces to interact — get those outgoing requests in your own custom outgoing handler.
And the next one is the WASI TLS implementation that is still experimental, at least in the WASI P3 headspace. It's going to allow your components to create TLS wrappers for your TCP socket connections, which will hopefully allow your components to act as clients and interact with external TLS servers without the need of going to the host HTTP handler. So those are the two things that I've been working on, and hopefully they'll be merged within this week. And hand it back to Bailey, because I don't have anything else to say.
Bailey Hayes 13:39
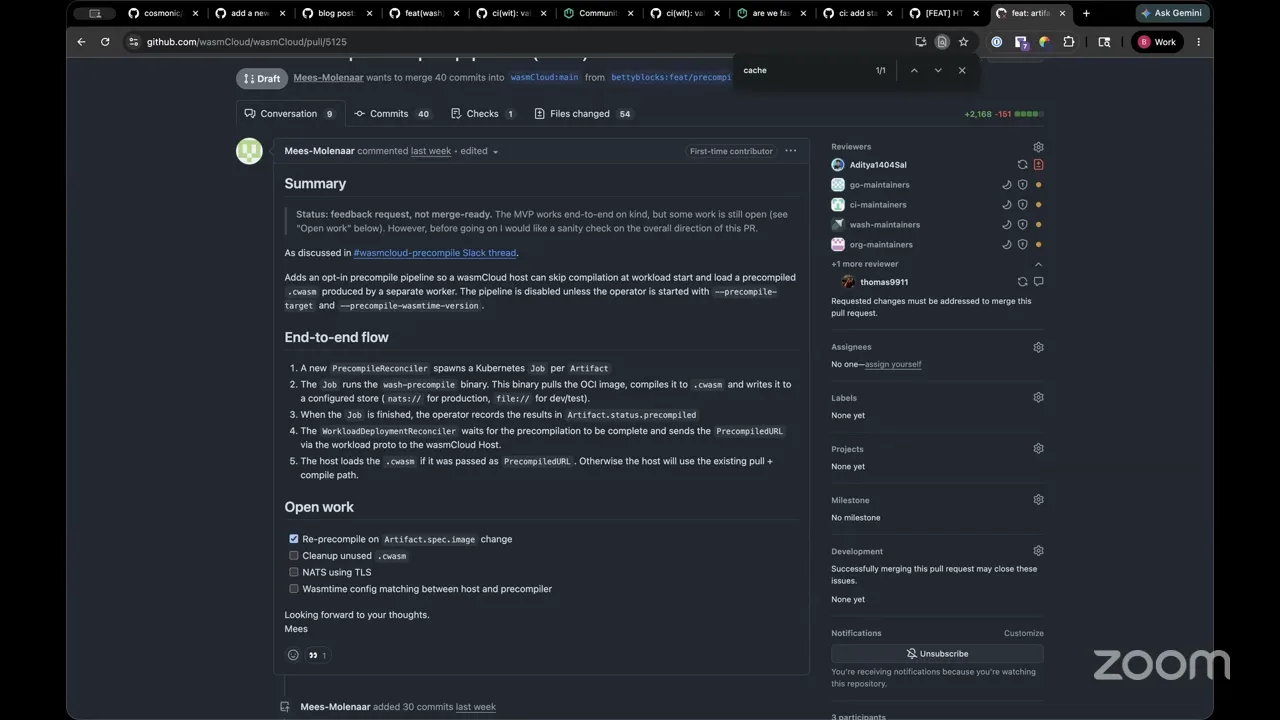
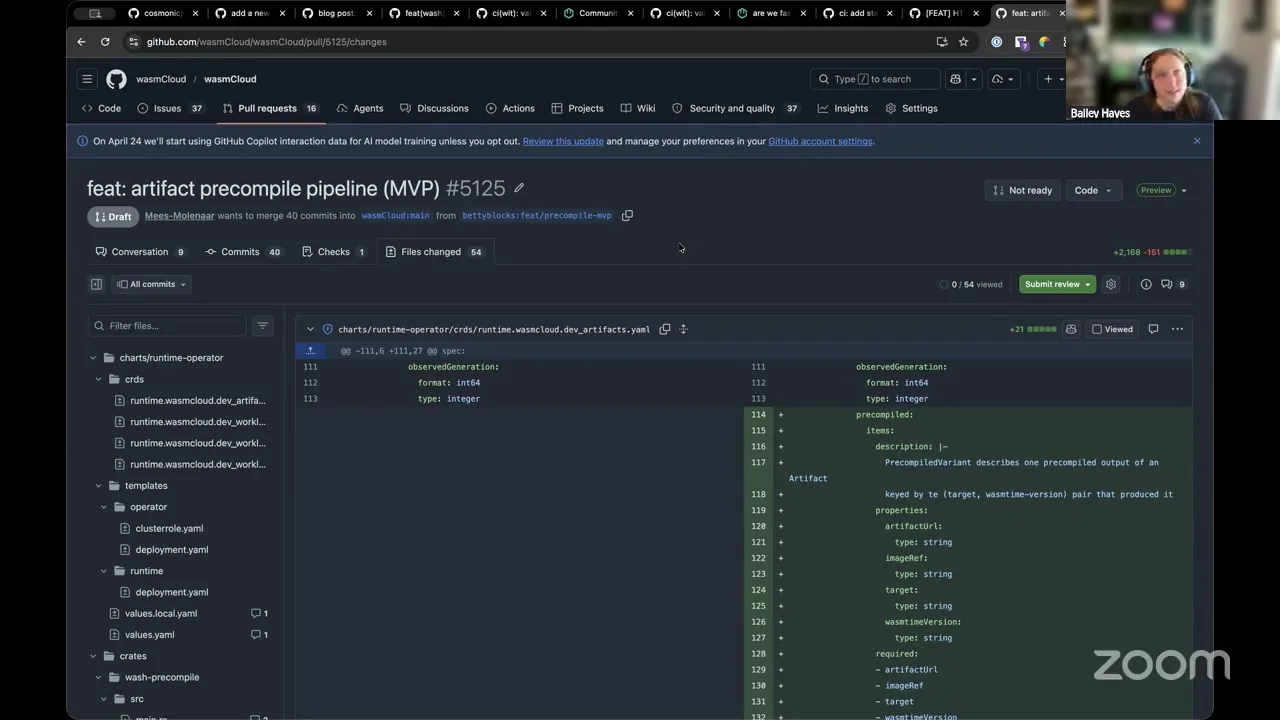
Yeah, I think for both of these, expect them to be merged this week, and which means they'll be included in our release, on our automated release next week on Tuesday. And yeah, I'm excited about them. I think, for the TLS one, if you start using this in your production environments, please let me know. We'll use that as a supporting reason to advance to phase three for WASI TLS. So big shout out on that one. I think there's actually another big one we wanted to talk through, Aditya, which was the cache artifact pre-compile pipeline. You want to give an overview on this one?
Aditya 14:20
Yes. So right now the host, when a component first lands on a host, Wasmtime compiles it in process on the same host, and it converts it into cwasm. This compile step is quite CPU intensive, and the resulting native code lives in anonymous mmap, both of which can impact co-located workloads. So this is basically an experiment that allows a process to run a dedicated pre-compiler instance whose only job is to take Wasm bytes and basically run the Wasmtime component serialize and take those cwasm bytes and store them in a shared store, a cache, and the workload host would only need to deserialize those cwasm bytes into the final workload state, which would dramatically decrease the post-processing time and make things quite fast. I don't think I can go that much in deep about this, but if anyone can care to take a look at the issue and the pull request, please feel free to do so.
Bailey Hayes 15:49
Yeah, this one — this one's a very, very significant feature, so I would appreciate extra eyes on this one. And I'm looking at Jeremy specifically right now on the crate side, making sure that we've got the right abstractions here. But essentially, one thing I want to highlight about cwasm is that it is effectively machine code, and that it's tied to the version of Wasmtime that we built with and the host architecture that we built with.
Aditya 16:25
Yeah. I believe it's also tied to the engine config. So it's a whole lot complicated, but there is a way to validate if the cwasm can be compiled. I think it's an engine hash. You get a compile, get pre-compiled hash of the engine, and you just compare it to the engine state that you currently have on the host. It matches — voila, it's gonna run. But, yeah, still pretty cool.
Bailey Hayes 16:56
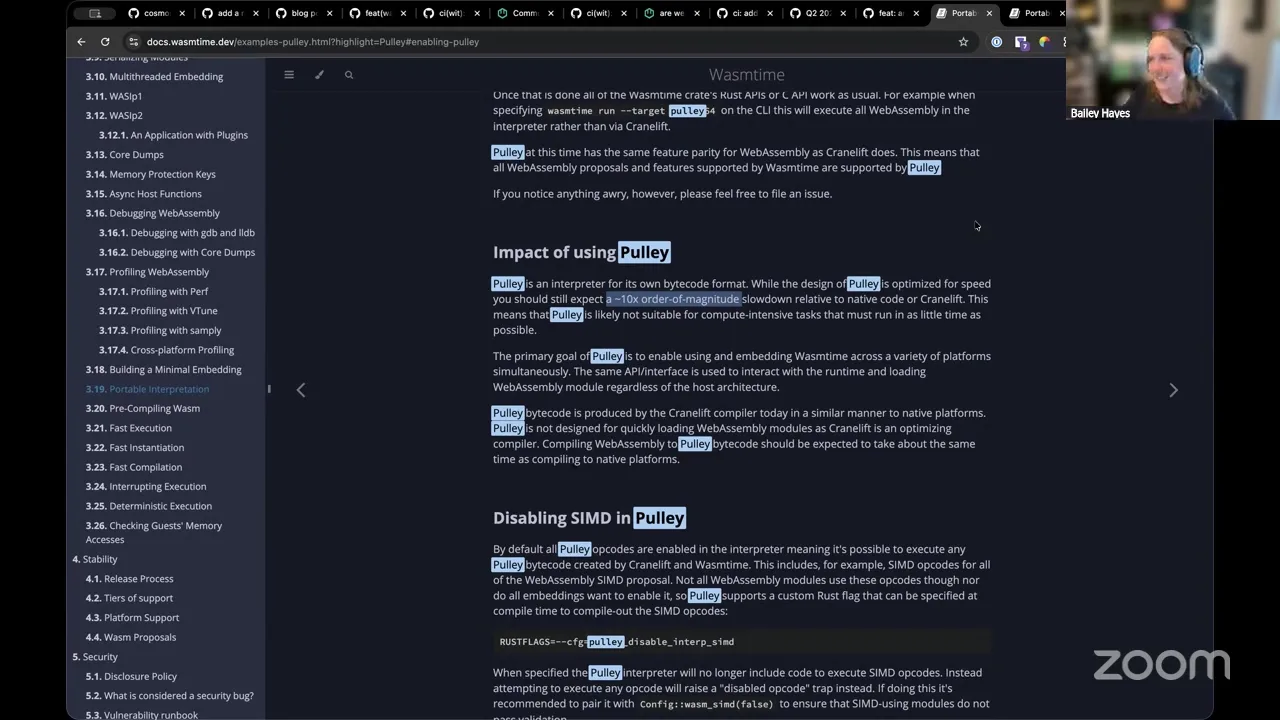
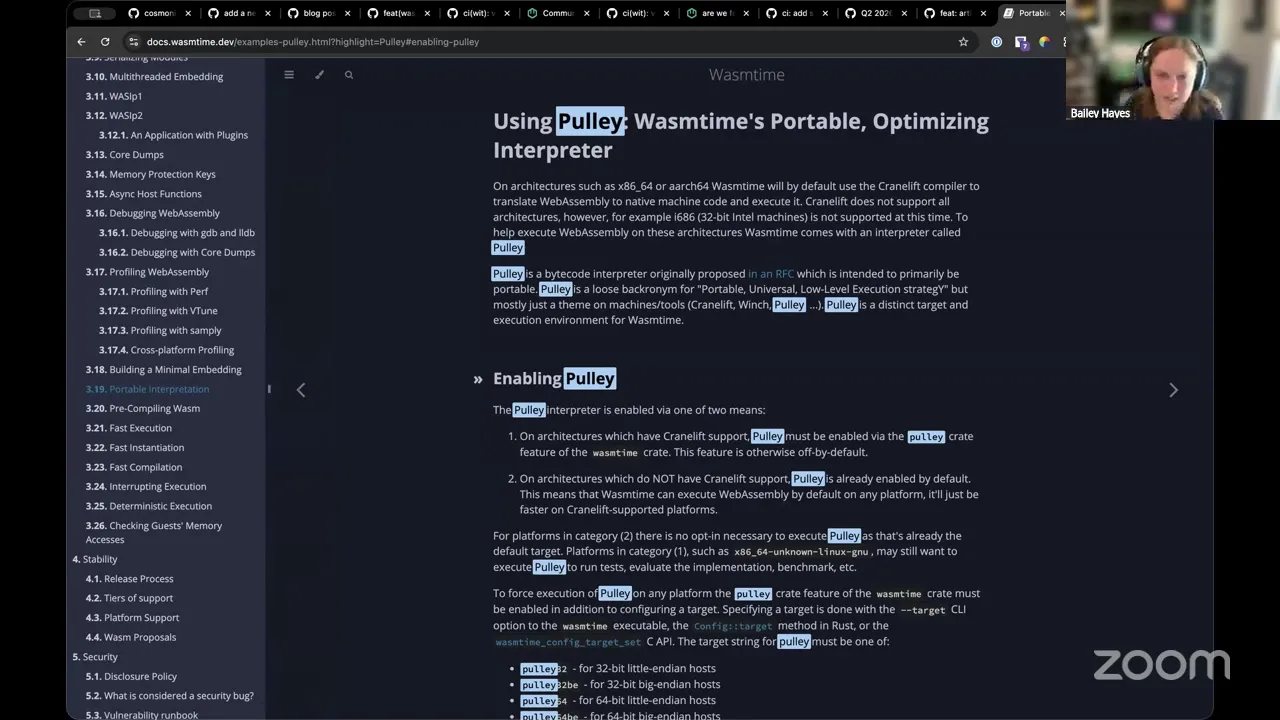
And Liam's evaluating this to make sure we have in our minds that we're going to make a couple other types of hosts. So right now, the reason why this is CPU intensive is that we default to Cranelift as our compiler backend doing an AOT compilation that gives us the best bang for our buck in terms of performance when you're executing the same WebAssembly component over and over again, like as essentially a serverless handler. But for some of the more edge hosts that we want to create, we're going to want to change that to likely the interpreter and have that run — probably wouldn't use a cached version cwasm specifically for Cranelift anyways — but there's Winch and Pulley.
So there's a baseline compiler, which is pretty interesting for a lot of use cases — is actually what Shopify uses for their functions. But I think for us, in a lot of cases, we'll probably use Pulley, which is the interpreter, which will let us hit a lot of other architectures, specifically tiny devices, which is pretty interesting too. So just knowing that we need to make it compatible with all those scenarios as well, but it's super exciting to see. All right, yeah, Frank,
Frank Schaffa 18:17
Do we have an idea what's the different performance between the interpreted and the compiled one?
Bailey Hayes 18:26
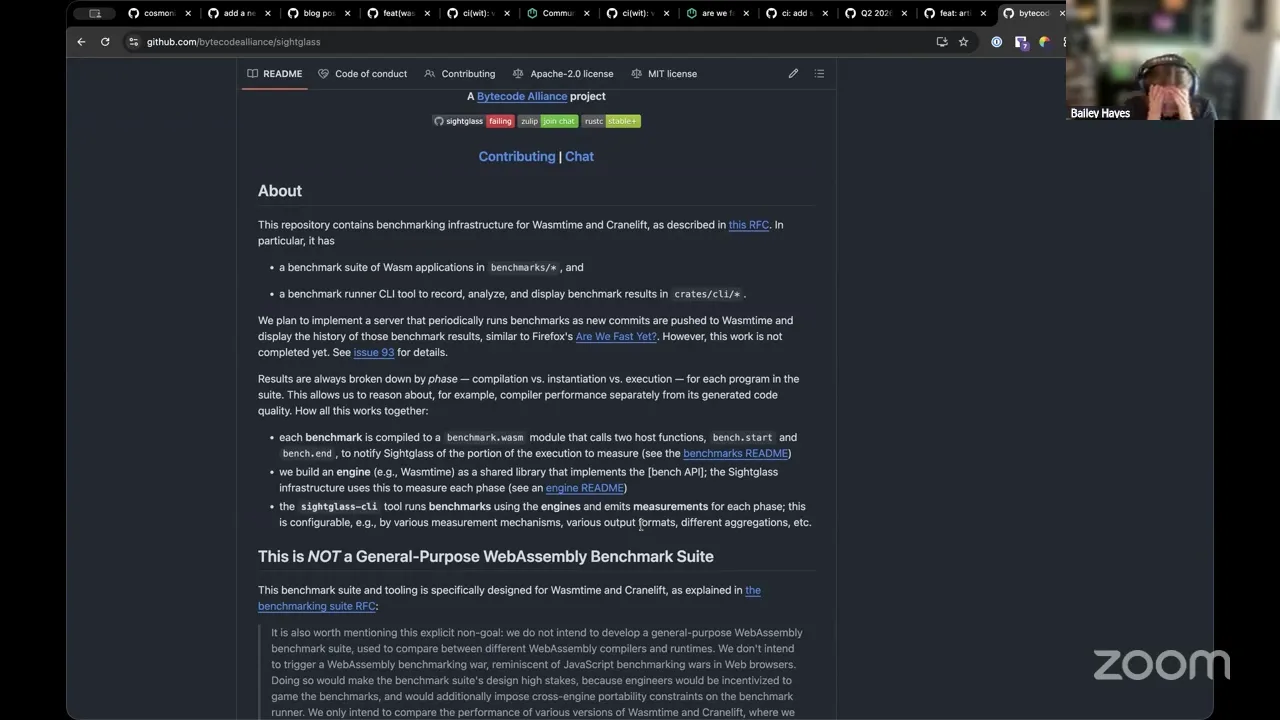
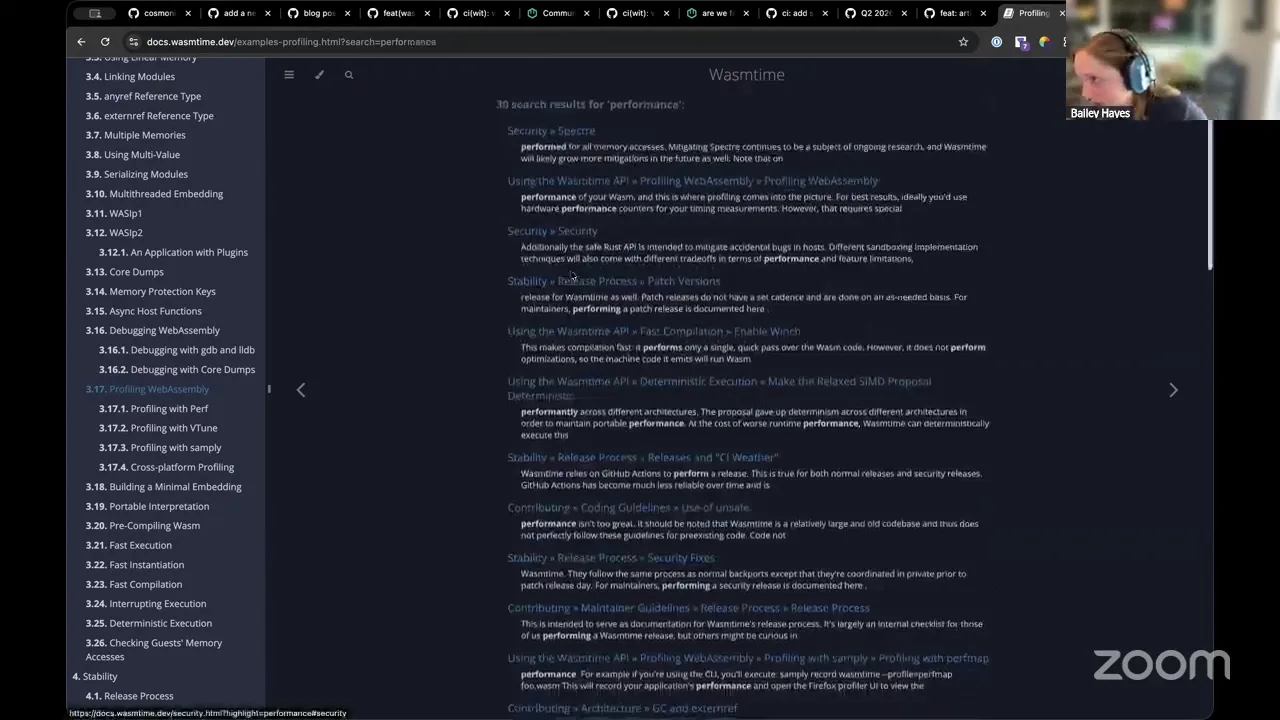
Yes, there's quite a bit of benchmarking around it, both micro and macro benchmarks. The place to follow a lot of that, and you can kind of see past runs, is over in the Bytecode Alliance — there's Sightglass, and this is basically all the tooling around Wasmtime and Cranelift. He also has actually a really excellent guide that's worth bringing up. This is the best thing to look at. So if you go to Wasmtime and you look for performance, there's three articles that are worth highlighting.
There's the one on basically diving in on how you should actually profile your WebAssembly. But the one that you're asking for is on the host configuration side. So if you are interested in fast compilation, this walks you through how to do it specifically just for that — obviously, this is giving a highlight on the compilation cache, which we were just talking about as a feature that we're adding to wasmCloud. And then in terms of instantiation, this is effectively what we have. This is the default for wasmCloud host today — everything in this article is what we're doing. But I was expecting to see Pulley in here. I did not see Pulley. I think this one's probably a big part of it.
Bailey Hayes 20:20
There you go. I knew I saw this fly by — so 10x, which honestly for an interpreter, when you compare native code to other scripting languages like JavaScript and Python, the rule of thumb between those two is 60x-ish. So 10x for an interpreter compared to an AOT compilation, that's pretty darn good. And to give you all those other environments, and to have such a low memory footprint, which is one of the big highlighting features of Pulley — now it's not something I've run more than once, I haven't done it actually any more than that, but it is something that I really, really, really want to get to and start messing around with more. But yeah, that's the canonical place where I would say, go take a look at it. Sebastien,
Sebastien Guillemot 21:19
Yeah, we've been looking into Pulley recently as well. One of the issues you run into is it can't run async functions at the moment. So this is something we're looking — there's a way to, like, unblock ourselves on.
Bailey Hayes 21:30
Yeah, there is actually another good talk that I totally recommend. I think it's up now. It's from Mikhail, from Mimic. But oh, hey, thanks, Victor. He dropped it in the chat here. I'll pull this one up. I know that they've been working in environments, more isolated environments, where they went in deep on this. I know, at least for the case that F5 had, and why Nick Fitzgerald built Pulley was largely where they're in a scenario where they need to be fully deterministic, and so they explicitly don't want async in their scenario. So that does make sense that it isn't there right now. Yeah, and a lot of these microcontroller type environments, they actually don't support that for their architectures. But that's not my area of expertise. I would definitely point you at Nick for those.
All right, so going back to the roadmap here, I think we hit basically all the main things in flight. One shout out — Victor is going to give an update on where JCO is as the second reference implementation for WASI P3 tomorrow in the WASI subgroup. So if you're part of the WASI subgroup, please, please join us. And we're gonna also have a little open discussion, talking to folks who've been deploying with WASI P3, if there's any concerns or anything — just kind of that last little flush out before we hold the vote.
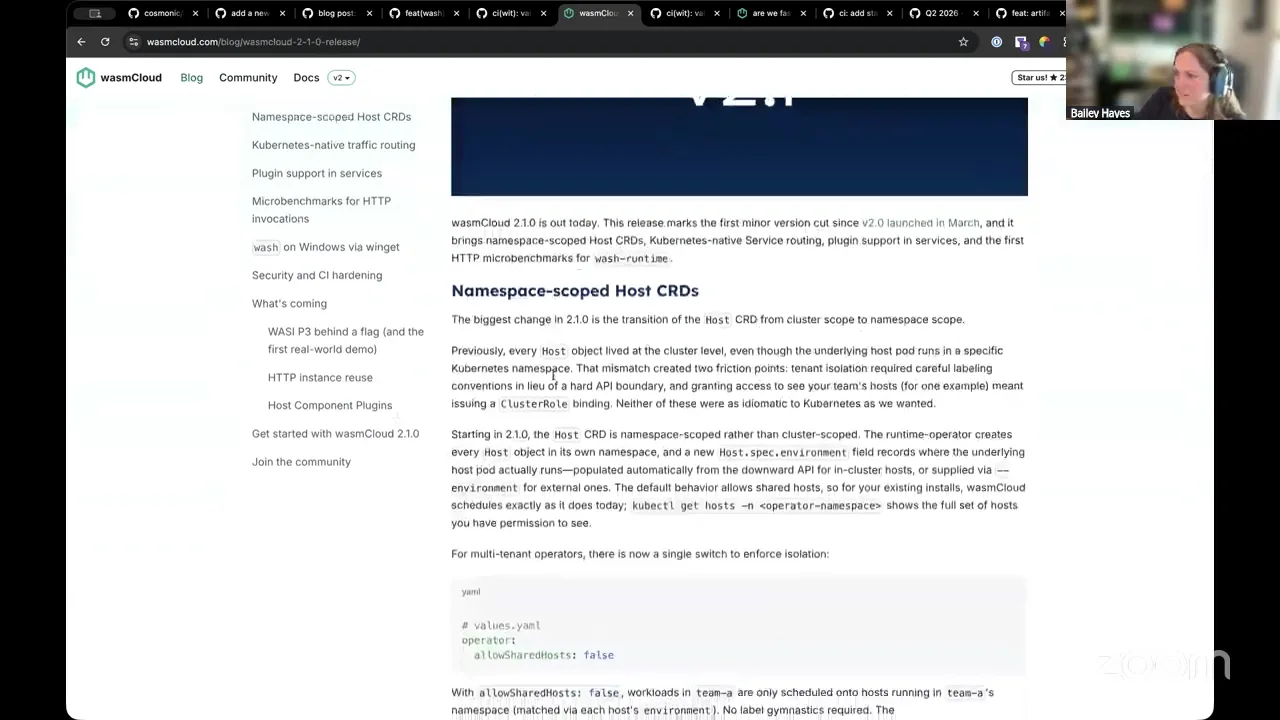
Now going back to our agenda, I'm going to go ahead and skip over this one for a second and just highlight that we did publish a blog post — if you haven't read it, last week we published 2.1 and it kind of gives a big overview of basically everything that we've done up to this point. And turns out it's a lot of stuff. So if you haven't been following along super close, I do recommend checking this out.
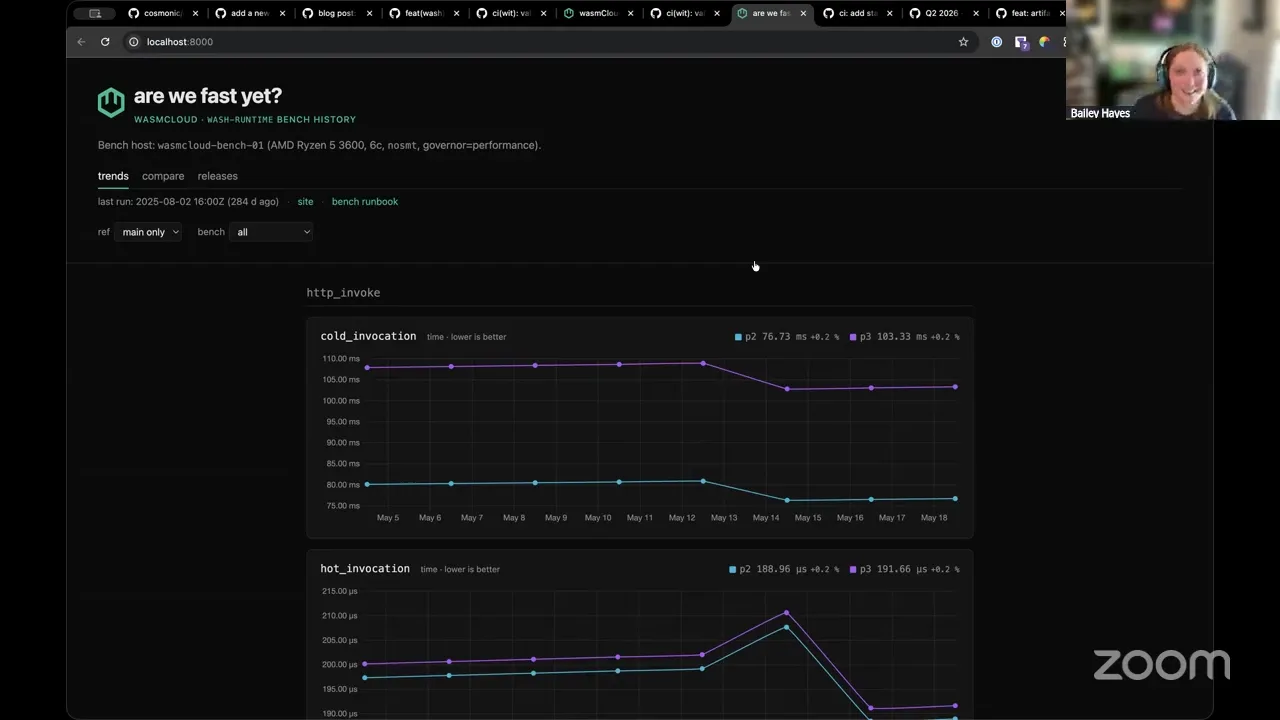
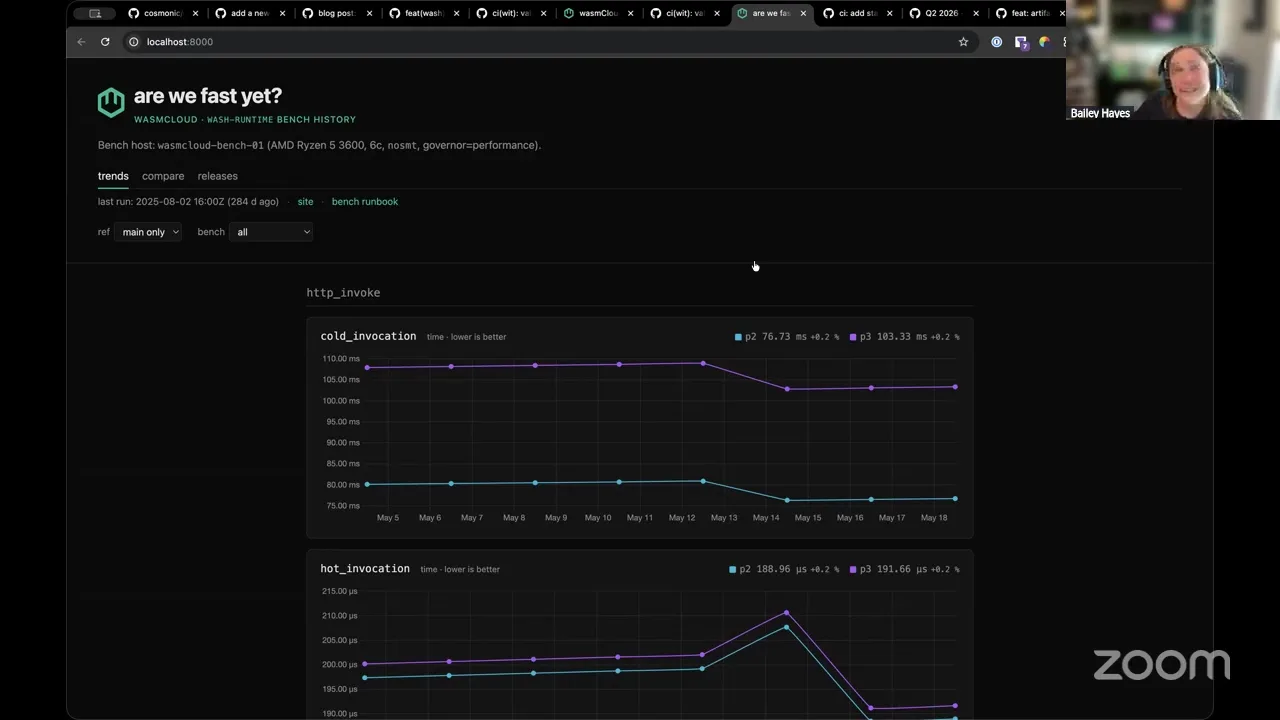
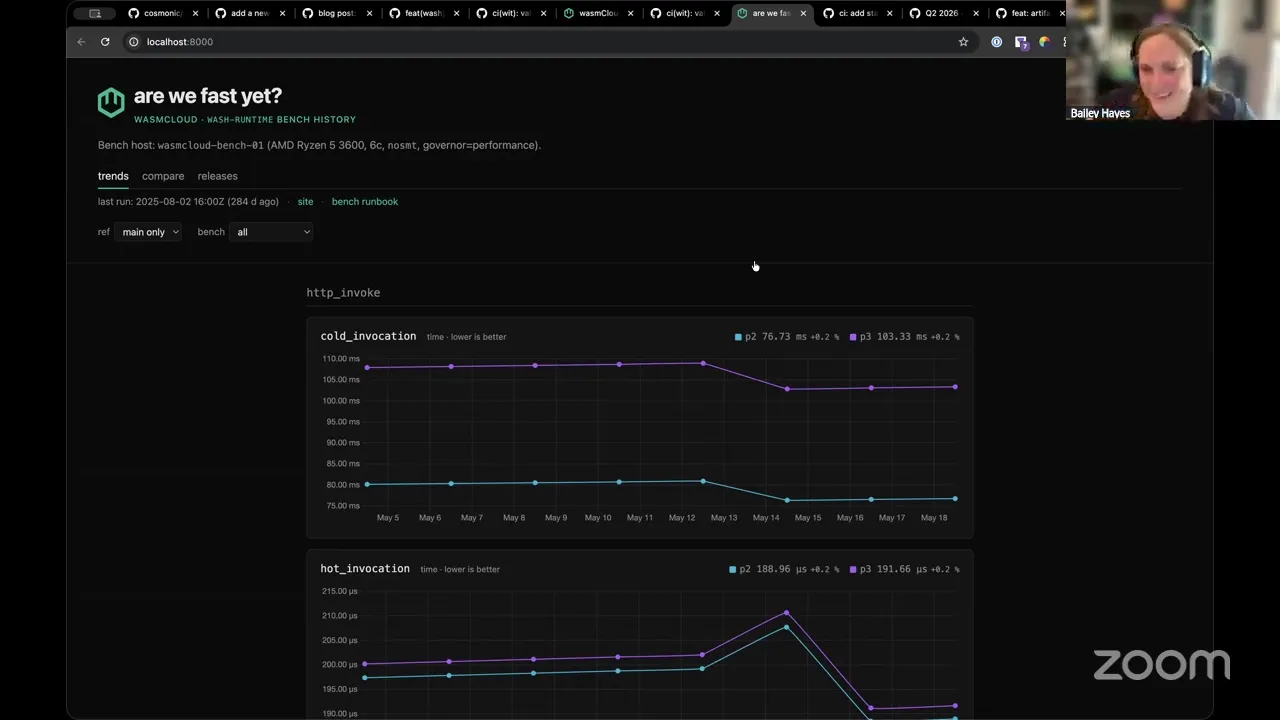
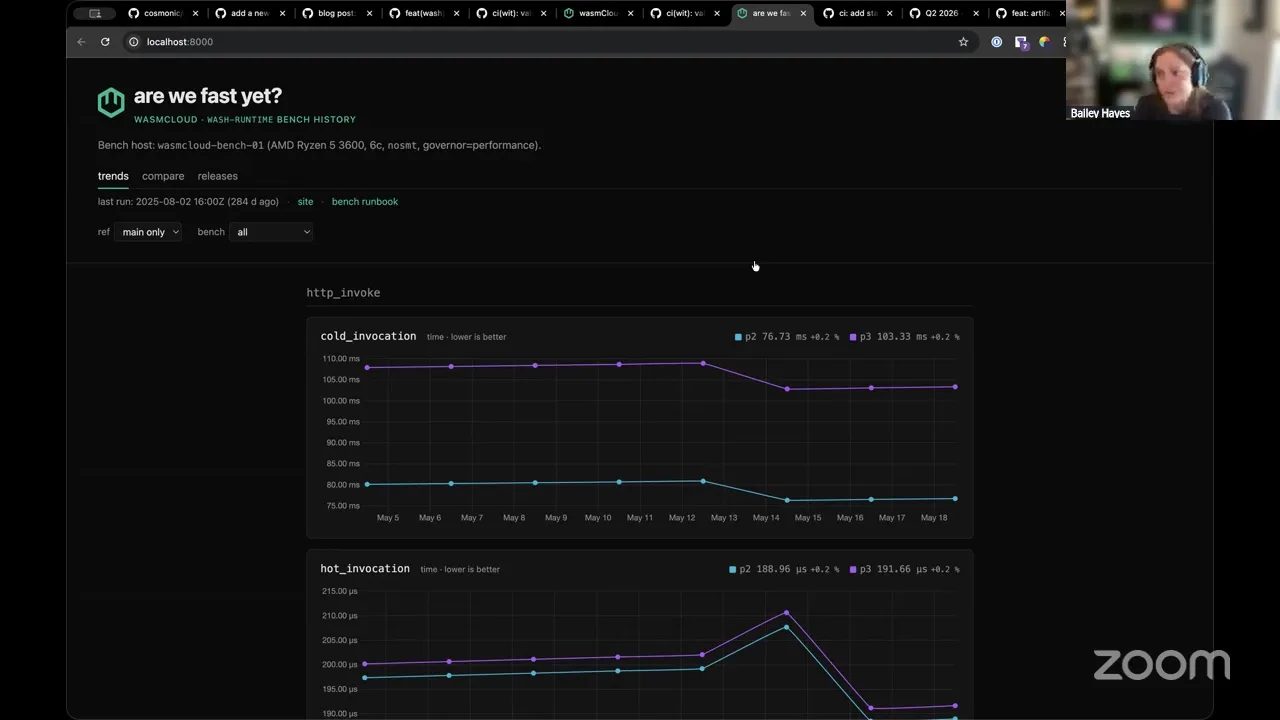
So you ready for something cool? This is what I've been working on. I'm not — I haven't quite finished it yet, but I'm making us our own "Are We Fast Yet?" So "Are We Fast Yet?" is something that I credit first to Mozilla, they made their own "Are We Fast Yet?" site, but then it's been co-opted by lots of other folks who have gone and made their own versions of these "Are We Fast Yet?" dashboards.
Basically, what happens when folks do benchmarking is that they make a pile of JSON, HTML, CSV, etc., and they're often just like, hidden away on the benchmarking box. Maybe they're pushed to a Postgres database. But usually what happens after that is things kind of fall off where the developer finds the benchmark regression, they go fix it, and all of that is not very visible to other people. And so one of the cool things that the Mozilla folks learned is that if you make a dashboard for it, things will get faster and better, because people can see and have transparency around where they are.
I wanted something like that for us, and I have a handful of performance-sensitive changes that I have in draft that I really wanted a chance to first get full benchmarking infrastructure in place for us before I start making those types of changes, just so that everybody can kind of have the information they need to really give me a good review on those changes.
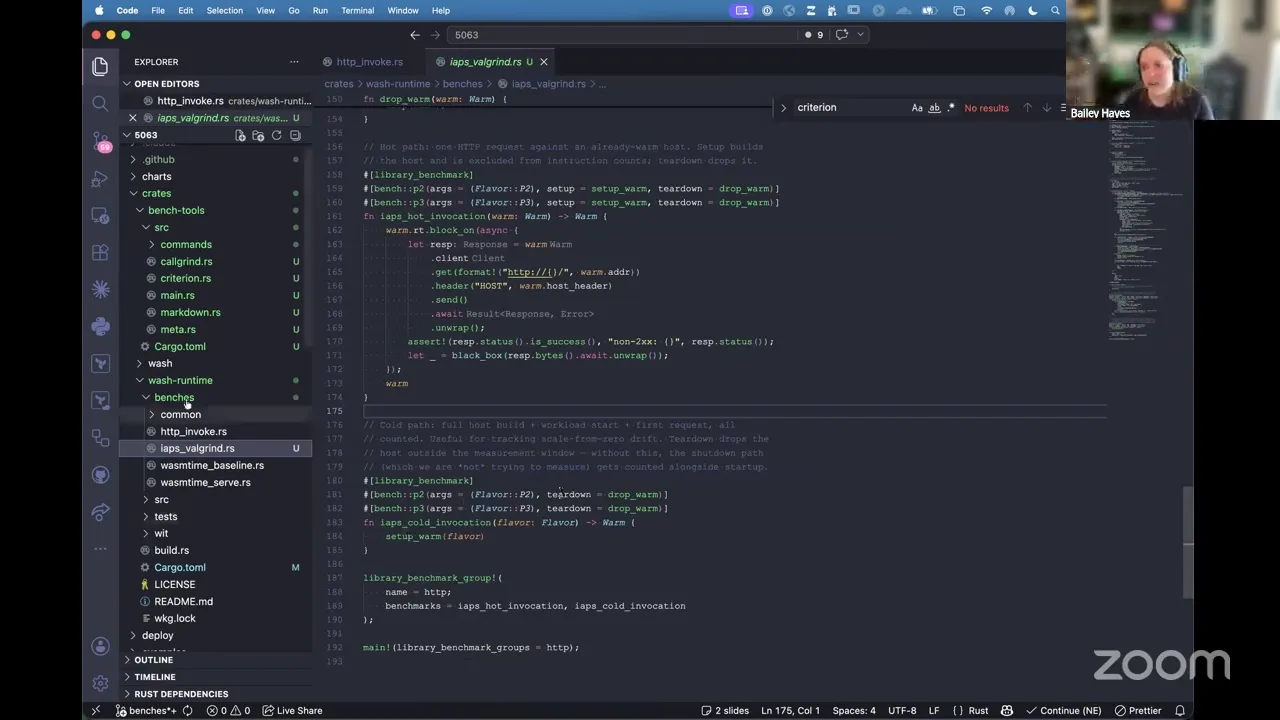
So the first one that I've already landed on main is our invoke benchmark, which I gave a demo of a couple weeks back. This is actually sample data — it is built from runs that I did, but the runs aren't real. But I recently just added another one, which is IOPS Valgrind. So essentially, underneath this, it uses a tool called Cachegrind. But basically this is doing instruction counting effectively, so I get way less variance with this version versus something that's measuring on wall time like I'm getting with Criterion's benchmark.
And so I set it up so that we've got basically dashboards for either one, and it's really easy for me to keep extending and adding more dashboards. But the important part is the next thing that I've been working on — I have provisioned with my own Cosmonic resources. So Cosmonic is going to donate this to wasmCloud — it's on Hetzner. I got an AMD Ryzen 5 box. I've staged it with basically all the recommended performance settings — I basically riffed off of what the Rust infra team does, essentially, and they do the same thing with how they also have a Hetzner box, so I've got it staged very much for performance.
And then all of this stuff is actually backed by basically CloudFront for our CDN. And then I am putting, every time we run this stuff, I'm uploading to basically S3 so that I can get historical data, and I can easily do this kind of snapshotting across each one. And I'm also intending to run it against every release that we make, and make it part of our automated release rollout.
Speaker 1 28:47
Super cool. I love this.
Bailey Hayes 28:51
Thank you. It's gonna be fun. It's one of those things where it's a pain in the butt to set up, but once you have it, everybody leans into it. I've seen it happen at multiple teams. Now, hey Frank,
Frank Schaffa 29:06
Yeah, this is wonderful. Are you using your tail, or what — how are you collecting the data?
Bailey Hayes 29:13
Oh, yeah, that's a good call. Okay, so there's a lot. So for the data collection side, there's basically a Rust tool. Essentially, I've got all of this described out in a README so that you guys could — I mean, a benchmark is totally useless unless you can reproduce the results, right? So all that information is here. I've scrubbed things like the actual host IP address, and you can only log into the box if you have the SSH key.
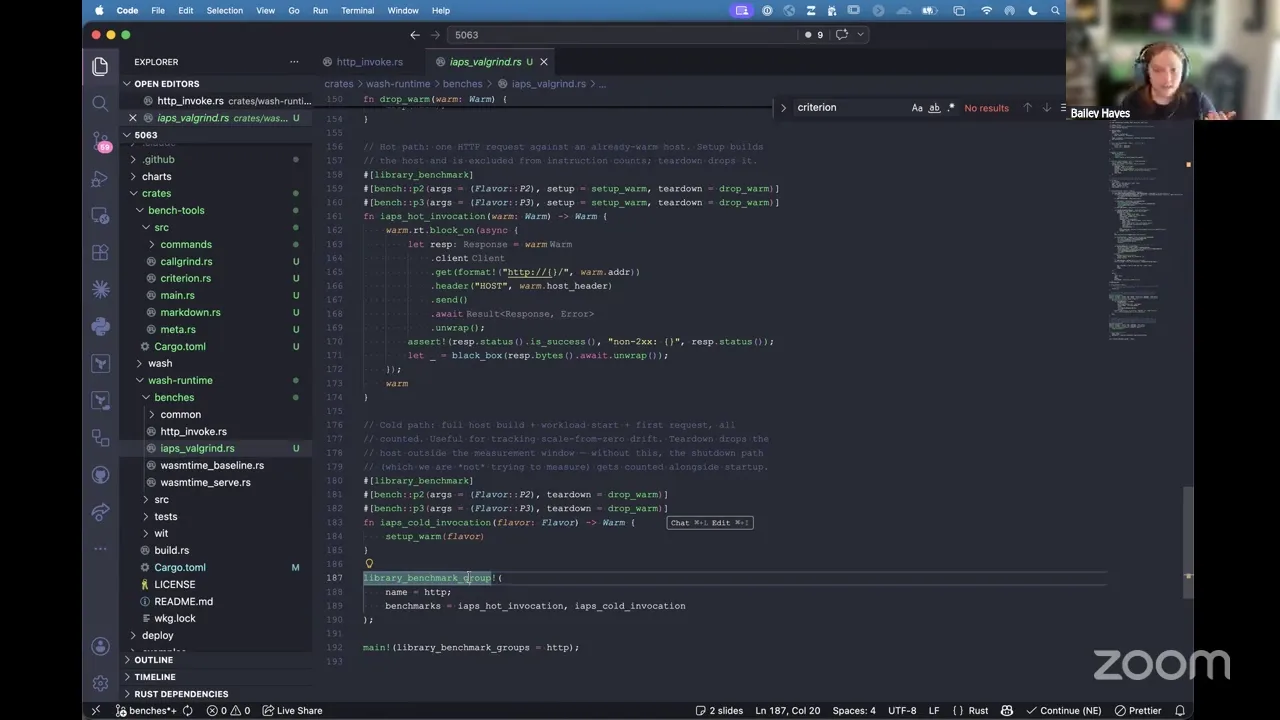
But to answer your question, Frank, basically all of this is done via a tool that we have going here. And so this is basically a driver for all of us that we upload, and essentially, if you add Criterion or Callgrind-style benchmarks — so those are micro benchmarks that are driven via — let me show you an example. So Criterion is specifically the way that it's getting the wall-time instructions. And so it basically is the thing that orchestrates the actual benchmark for how long you run this thing. Valgrind kind of has the exact same thing. And then I have these bench tools for basically getting it in a common format and uploading it to S3. And so the combination of basically these is how we get our data, and you can see how it has warming and all that kind of stuff.
Frank Schaffa 31:29
Right? So just the equivalent of about k6 and that kind of potential for Rust?
Bailey Hayes 31:37
Yeah. So these are specifically micro benchmarks, which is what I needed for being able to measure basically, if I do component composition inside our host versus doing Wasmtime linking inside our host and comparing those two things, I need a Rust-based micro benchmark basically to do that easily. I could do it on the outside with Valgrind, but it doesn't have the same level of fidelity that I wanted.
Now for using something like k6, which we definitely want, that's definitely on the roadmap — that I consider a macro benchmark, right? Because you're introducing things like networking and all that kind of stuff into the mix. It should be very straightforward for us to be able to add a link to that. I think I still prefer with k6, using their built-in Grafana dashboard stuff that a lot of people build with, and linking to basically another dashboard that's specific to k6, but it should also be easy to export that data and make that visible in "Are We Fast Yet?" as well.
Frank Schaffa 32:43
It's wonderful.
Bailey Hayes 32:50
Cool. Well, that's all I have for today. Anybody have other topics they want to talk through?
Colin Murphy 33:06
I almost had a pretty cool demo, but I didn't — I couldn't get — I had to rebuild everything, and it was too slow. It's still building. But next time, next time, cool demo.
Bailey Hayes 33:19
Let me know. I will put it on the agenda. Yeah,
Colin Murphy 33:21
No, yeah. I gotta be good. I want to be a good citizen here. Put it on the agenda.
Bailey Hayes 33:27
One heads up — Mindy is working on updating the WebGPU API to be P3. You know, WebGPU is designed to be async, so it's a very natural fit to take advantage of a lot of the async APIs that exist, or the async ABI inside the new WASI P3 version. So I don't expect that to happen — and then, I mean it might, maybe in a week, that would be pretty baller, but we'll be revving all of those things everywhere with that. Yeah, you probably saw the cooperative thread stuff moving quite a bit this week. I know you're watching.
Colin Murphy 34:07
Yeah, I'm always watching that. First thing I do in the morning, I check that. Get mad if nothing happened for 10 days. Yeah,
Bailey Hayes 34:15
Well, I don't know. I'm super hopeful that it's gonna land this —
Colin Murphy 34:19
week. Yeah, seemingly, yeah. I mean, it's gonna be great. It's gonna be great.
Bailey Hayes 34:25
That's bait. We'll have a new WASI SDK with that. And then we'll start rocking and rolling in a lot of different language toolchains.
Colin Murphy 34:33
Including Rust. And then we'll have Rust be a P3 something you can download.
Bailey Hayes 34:39
Yeah, I was going to hustle on the C side specifically, mainly because I think I'm going to re-rev the abseil change that I put in, instead of being like "atomics don't exist" — down like "atomics fully exist," and it just natively works. And I can remove all the WASI-specific isms here, actually. So that'll be much easier for them to swallow, I think, to merge. Then I have to touch every single thing, just what I wouldn't like about it.
Colin Murphy 35:11
What do we need for hyper? Sorry, is this still recorded? So to get hyper —
Bailey Hayes 35:15
working.
Colin Murphy 35:17
All right, what we have — WASI TLS, because somebody asked that in Cloud Slack. And I was like, I think we still need WASI TLS to work fully for reqwest. I used to know everything. I used to remember, but now I don't know off the top of —
Bailey Hayes 35:32
my head. I'm all up in the sauce, and I never — the problem is, you have too much historical knowledge, right? And you can't ever suss out, what's the actual latest versus what was the direction? Well, I know that there are multiple reqwest forks that exist. I don't know, I can't, off the top of my head, say which one's the freshest, but most of the things that would flip for reqwest were actually a lot of it was in the Tokio space.
Colin Murphy 36:01
Right?
Bailey Hayes 36:02
And all of those landed.
Colin Murphy 36:05
So I know, yeah, I think it's just, I think it's the TLS thing. Unless that's done? Is that done? It wasn't done a month ago. Is that?
Bailey Hayes 36:15
I don't think so.
Colin Murphy 36:17
I think it's that, because I think reqwest needs that kind of thing for ureq. It was the socket stuff.
Frank Schaffa 36:24
Yep.
Bailey Hayes 36:25
That landed.
Colin Murphy 36:27
Okay, so maybe we can get ureq on. All right.
Bailey Hayes 36:31
Yeah, it's —
Colin Murphy 36:32
Good stuff, although we might want atomics there. Maybe not. I don't know. I forget.
Bailey Hayes 36:39
No, we were — so with the socket change that I landed it was specifically P2 with pollable. So I made it async, and I used the trick for saying basically not P1 but yes for anything after this. So in theory, it'll just work with P3.
Colin Murphy 37:02
Ureq, we talking —
Bailey Hayes 37:04
Just sockets, sockets too, which was —
Colin Murphy 37:08
Just general sockets. Okay, you're gonna redo sockets for P3, or is —
Bailey Hayes 37:14
I technically don't have to, though, because it will work. It will compile with P3 without changes.
Colin Murphy 37:22
Well, we just have — okay, all right, and then P3 time zones is, that's ready last —
Bailey Hayes 37:28
time I —
Colin Murphy 37:29
looked, which I should probably be looking more often on that.
Bailey Hayes 37:32
Yeah, that's you.
Bailey Hayes 37:33
I know. I know.
Colin Murphy 37:34
It's me, but just last time I looked, there wasn't anything new coming.
Bailey Hayes 37:37
Yeah, yeah. It's just solid. It's just there.
Colin Murphy 37:39
All right, all right, good.
Bailey Hayes 37:45
Yeah, so I'm expecting tomorrow's WASI subgroup to be more of this basically.
Colin Murphy 37:50
Yeah, where are we? Who did that? What do we need? Not that bad. It's not that bad. It's just doing a million things right now.
Bailey Hayes 37:59
Yep, yep. All right, well, if anybody has any other questions, if not, I'm going to get back to benchmarking and hopefully get this PR up today.
Bailey Hayes 38:15
Awesome. Have a good week, everybody.
Bailey Hayes 38:19
Thank you. Have a good week. Bye, bye.