Transcript: WebAssembly on Kubernetes — Volume Mounts, Services & HTTP Ingress
wasmCloud Weekly Community Call — Wed, Dec 10, 2025 · 35 minutes
Transcript
Bailey Hayes 00:00
All right, hello, and welcome to the December 10 wasmCloud community call. We've got three agenda items today, but also feel free to use the end of the time here to ask questions, and ask questions as we're going through stuff. The first thing that we're going to show is from Eric. He has a walkthrough that he's added to our docs to show how to use volume mounts for workloads. Take it away, Eric.
Bailey Hayes 00:36
All right, do I have sharing powers?
Eric Gregory 00:42
All right, so hopefully y'all can see the document here. This is in a PR that is up on GitHub right now, and this is covering utilizing external file system resources via WASI file system pre-opens, and how we do that in wasmCloud v2, which is using a Kubernetes volume. So this doc is basically focused on walking you through the deployment side of that, but I want to walk through it from beginning to end to get a sense of what this looks like in practice.
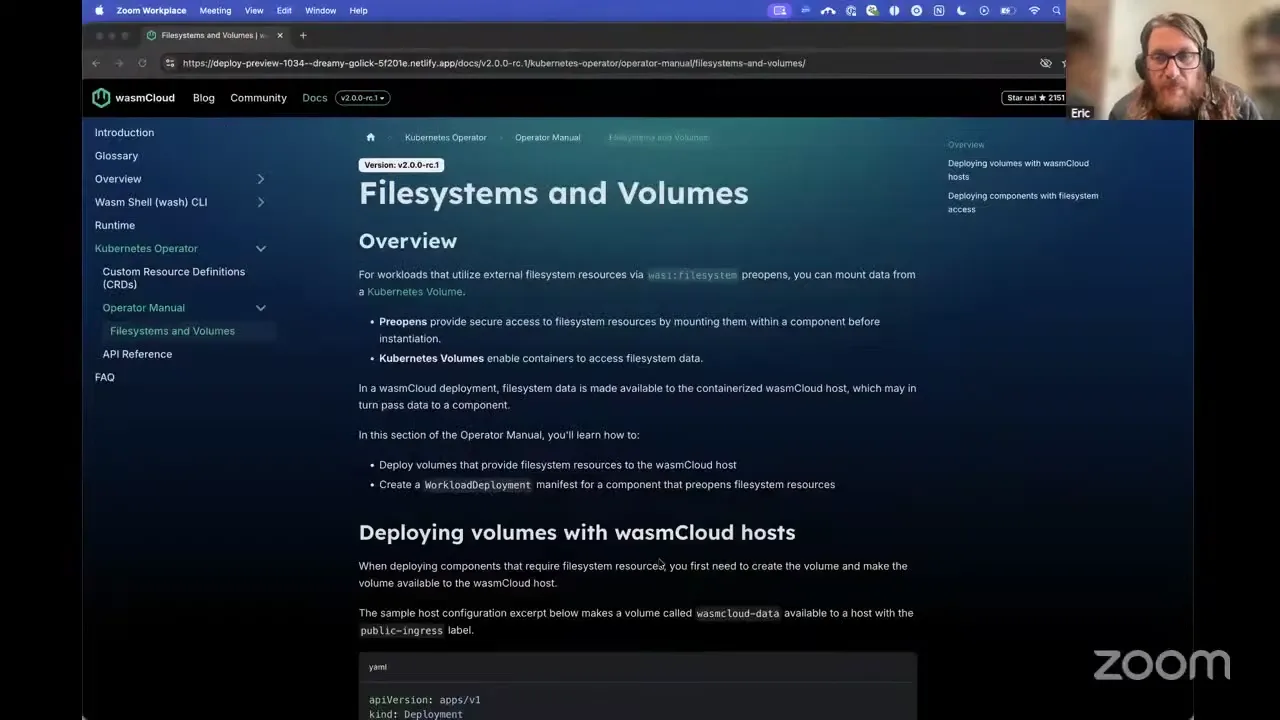
So here is a pretty simple Rust component. Thanks to Lucas for helping me out with putting this together, but this is using standard Rust libraries for file system and our standard approach for HTTP with components, and this is just going to pull in data from an external file and return that in an HTTP response — so a pretty simple component. How do we make that run with file system resources that we're using in a deployment on Kubernetes with wasmCloud?
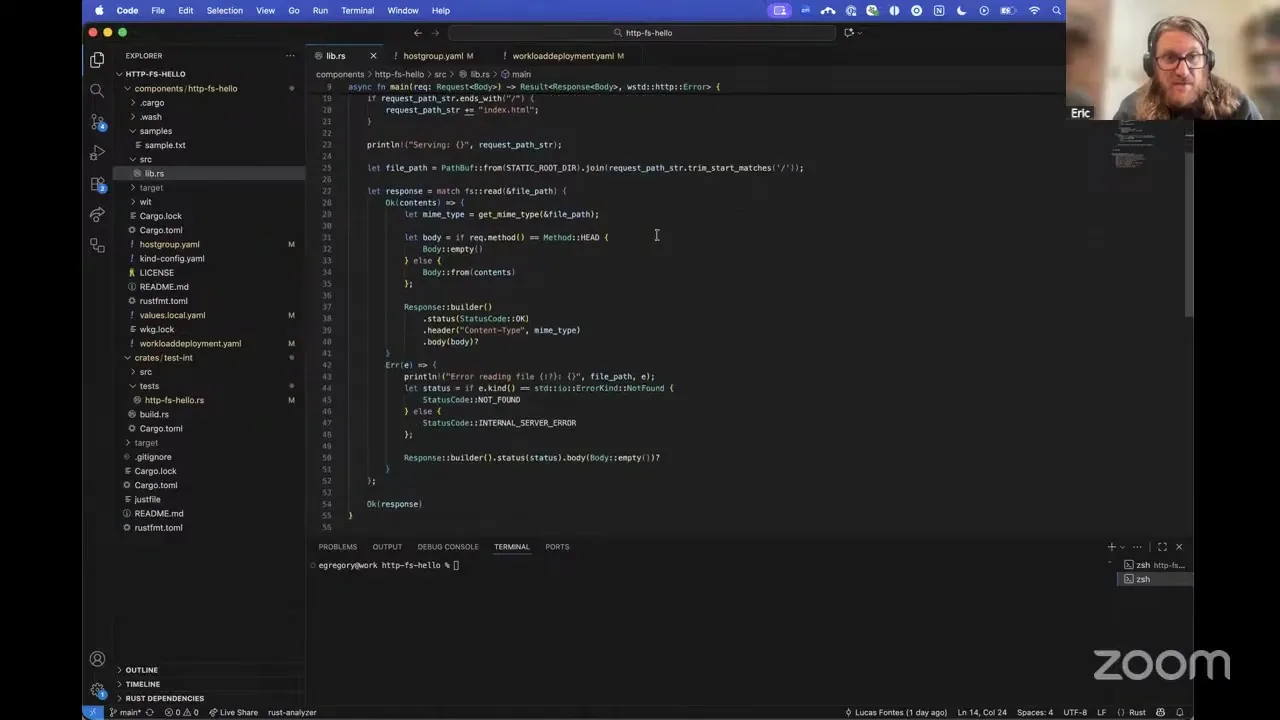
That is going to look like first naming a volume and then specifying the target path for the file or directory on the host machine. We're going to do that in our host deployment, and then in our workload deployment we'll add that volume, and we'll have a matching host path in the host deployment there for host path. And then we will add the volume mount under the local resources for a component, and here in this mount path field, we'll specify where the data is mounted inside of the component.
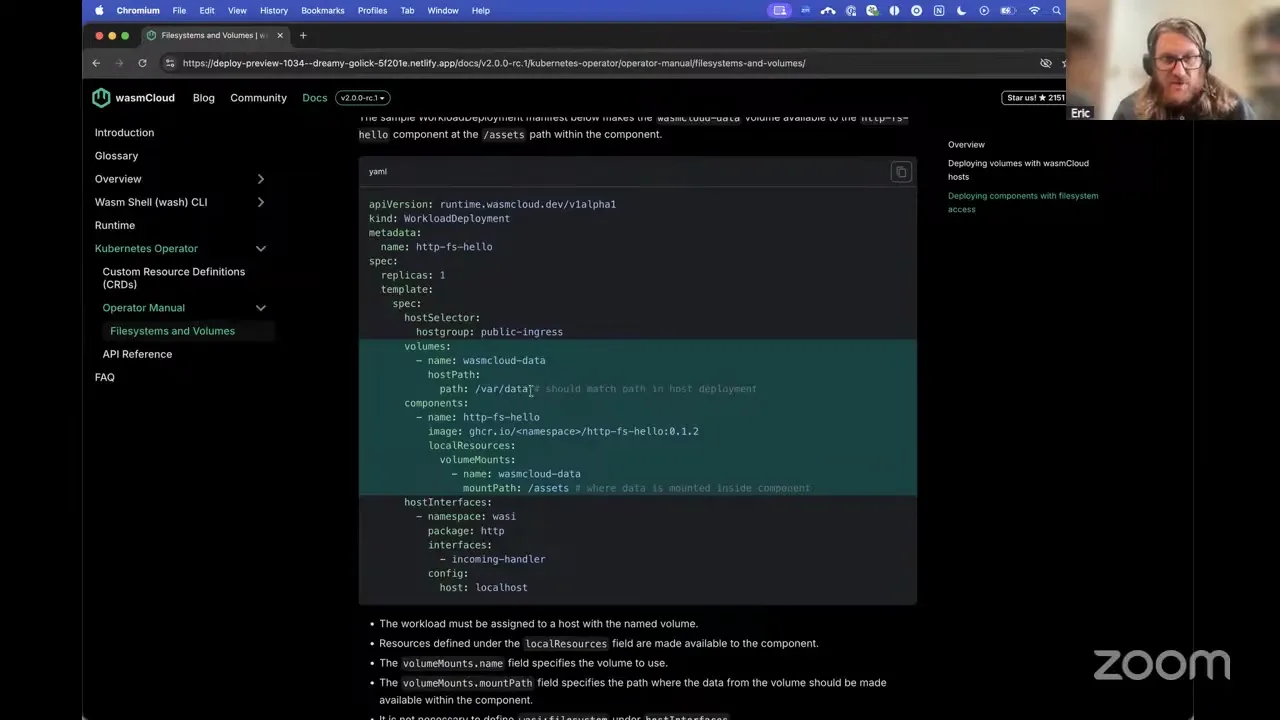
So when we deploy that — got a local kind cluster running now. Here is our component running, and if we curl that, this returns a sample.txt file that we had loaded up with the volume mount. So pretty straightforward stuff. This is intended to be just a basic proof of concept that shows you how to work with this functionality in wasmCloud v2. We'll try and get this example that we've put together up somewhere in the wasmCloud repo where you can refer to it, but for now you should see these docs coming in very soon, covering that deployment side of the story and helping you to do something similar for your own apps. Any questions?
Bailey Hayes 03:38
Awesome. Thank you, Eric — and also super good docs, actually. Can I ask you to share one more time? I also linked to your next PR, and ours, about services, and when we merged that. I also feel like that's — let's call that the doc of the week. It's under overview, workload services. You want to talk a little bit about this one, Eric?
Eric Gregory 04:09
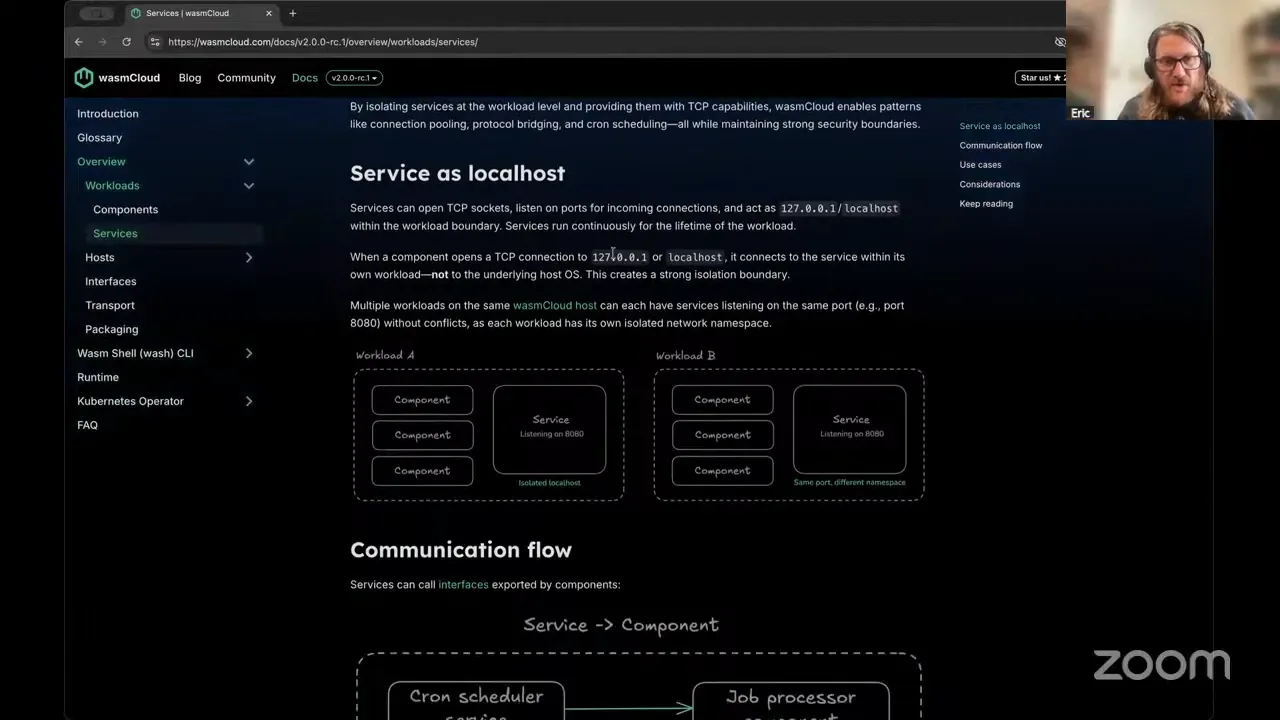
Sure thing. Ultimately, this is expanding on and trying to diagram the excellent presentation that Lucas gave the other week — if you want to refer back to that for kind of a personalized walkthrough. This is talking about services as the stateful companions to stateless components, and the way they are going to function essentially as a local host and help to provide stateful functionality and TCP service for your workloads. So this breaks down the communication flow, breaks down use cases, and attempts to give code examples and diagrams to help explain those where useful, along with some development considerations. Any questions there?
Bailey Hayes 05:10
Thank you, Eric. Yeah, I really appreciated that one, with lots of diagrams. That was probably the top request — to explain how services look and feel — and I think I almost feel like that one's complete. I know docs are never complete, but we're getting close on some of these pages where it's definitely MVP. So thank you.
Eric Gregory 05:36
We've definitely got plenty to expand on the development of services, right? And that's going to go under the wash section. But yeah, I think you're right for that overview section — we've got most of what I think we need at this stage.
Bailey Hayes 05:46
Yeah, and actually I'm gonna jump the queue ahead of you, Lucas, on that one, just because it's relevant here. What we found is that right now, the way that we've configured wash in our config — and also for wash dev — right now it's geared towards being able to develop just a single component or a single service, and we want to make that flow work for being able to develop entire workloads. I wanted to have a full issue proposal before we got into this call, but I will get one up today that includes all my thoughts there. I've done a couple different prototypes, and I've got one that I really like that will be a way for you to change wash config so that it has your full workload definition. You can have multiple components and a service in it, and you can iterate on that service — like if you're using the code example Eric showed, a cron service that maybe every second triggers a component, you can do that locally. That's the goal of that change. So that's in progress, and that's my status update on that. Lucas, are you here? You are here. Would you like to talk through HTTP ingress?
Lucas Fontes 06:56
Yes, let's do it. So today we are going to touch on a topic that has been discussed in the community a few times. The question is: how do I receive HTTP on my components? When we're dealing with local development, pretty easy stuff — single host. When we're doing development for the Kubernetes cluster setup, once again we bring up a single host, and that's fairly easy: you map a port externally to a single host, and off you go. But what happens when you have more than one wasmCloud host in your cluster? Where do you send HTTP? How does it know where to go? So that's what I want to bring up here today, because there are many pitfalls, and the answer is essentially: we don't know. There's no clear answer. There's more of a suggestion of what to do, but no clear answer. So we are looking to address that, because we feel that this ingress story for HTTP is one of the key deficiencies of the wasmCloud project right now.
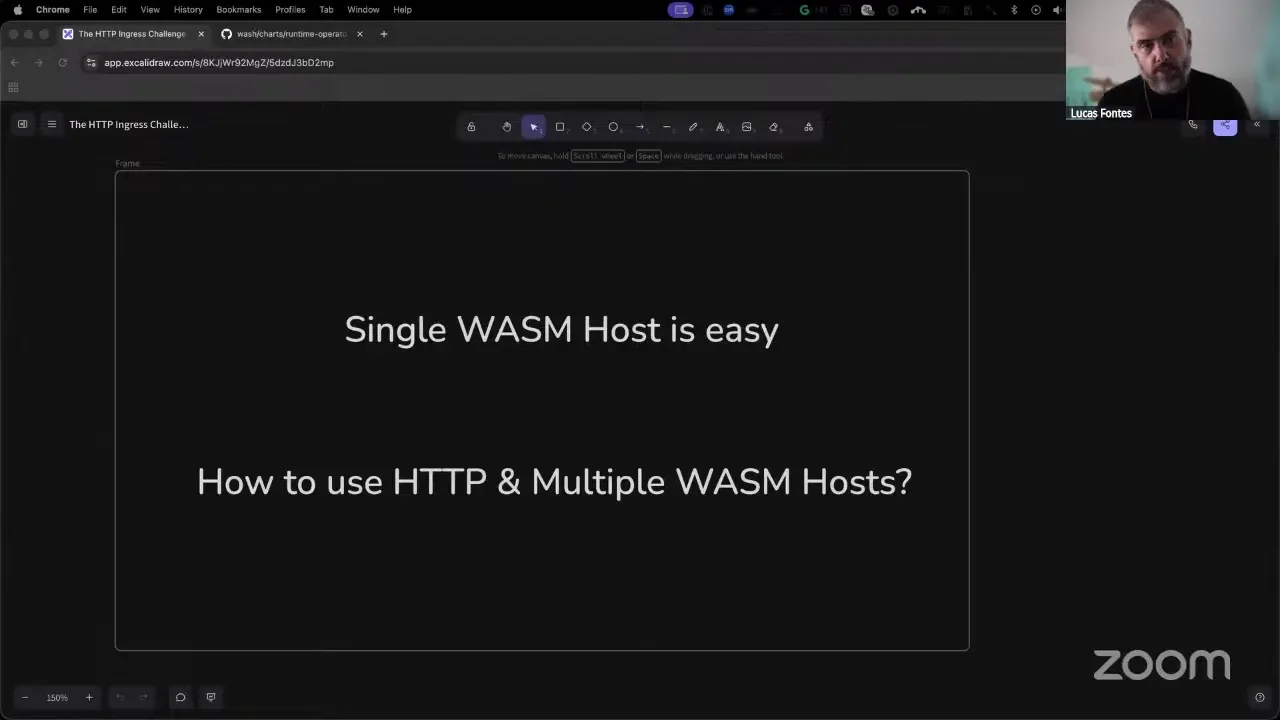
If we look at wasmCloud v2, this problem already existed there, so this is nothing new with v2. If you decide to stay in v1, you also have that problem — you just don't know it yet, because you probably don't have multiple hosts. The challenge here is: if I have an application and I want to start an HTTP provider, I submit my application to wadm. wadm will place that on a host. How do I know which host to send the HTTP request to? This means that every time I deploy the application, that host might change, meaning your HTTP will stop working. And similarly, if you have two applications that need HTTP — each one declaring an HTTP provider — what happens if they both land on the same host? Well, we know what happens: one of them is going to get ejected. So it's not clear which one is the actual owner of that TCP port at that point, because it's basically a failure in the placement. So many things might happen here: if you have two applications, they might land on different hosts, which means you're going to have two different hosts, two different TCP ports serving that application, and that's okay. However, if they land on the same host, you're going to have a problem, and every time you deploy any of these applications, you're going to have to go through that again. So it's not something that you can simply fix and move on, and the situation is pretty similar in v2.
You might have one application that is doing a rollout, going from workload A version one to workload A version two, and initially when you schedule the application, the workload landed on host one, so you started sending your HTTP requests there. As soon as you roll out to version two, the workload gets assigned to a new host. Now you have to send the HTTP to the other host. This is essentially a challenge that exists in Kubernetes and was handled using services, service endpoints, and so on, and that's a bit of what we're getting to here as a solution. There's another problem, which I think is a bit more security oriented: you might have different teams, each one in their own Kubernetes namespace, creating a workload A and workload B, and they are both requesting the host example.com. Now, in this situation — first, why are they requesting the same host name? Who should be the actual owner? The situation gets a bit more complex because the workload from this team might land on this host, the workload for this team on a different host, and now when you go to example.com, depending on the host that you are entering, you're gonna get a different workload. So it's almost like a platform administrator's nightmare.
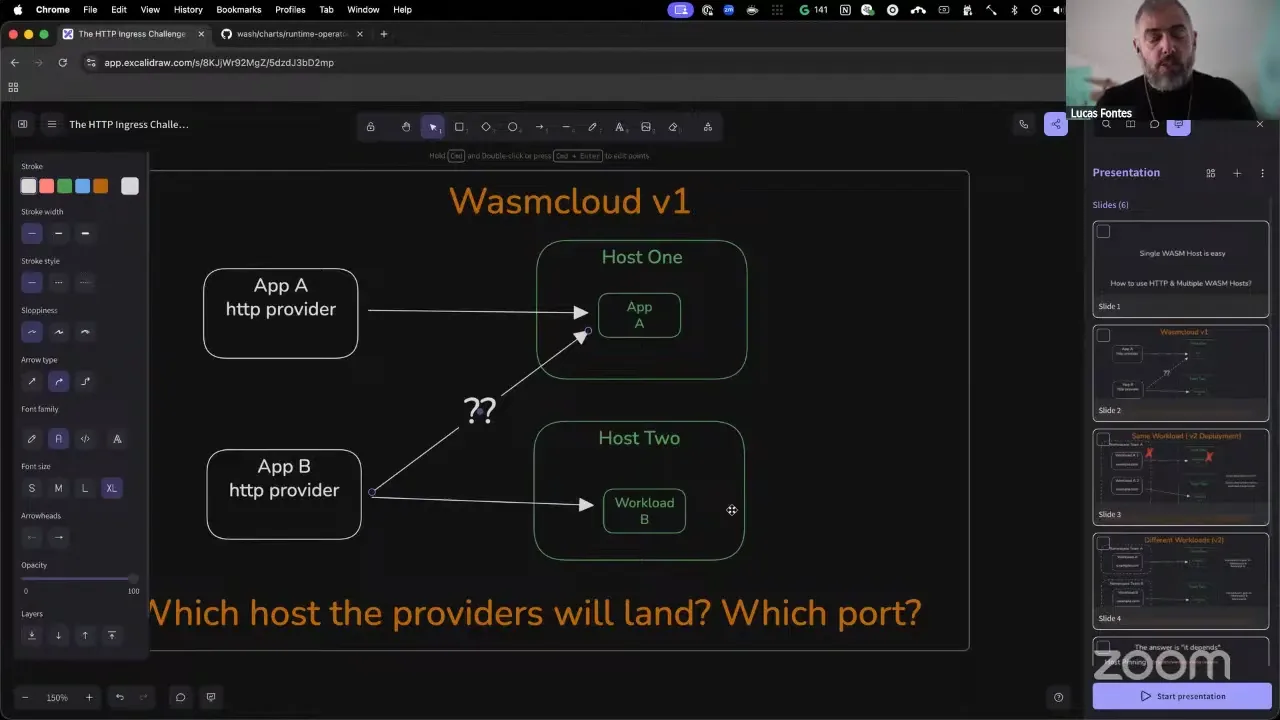
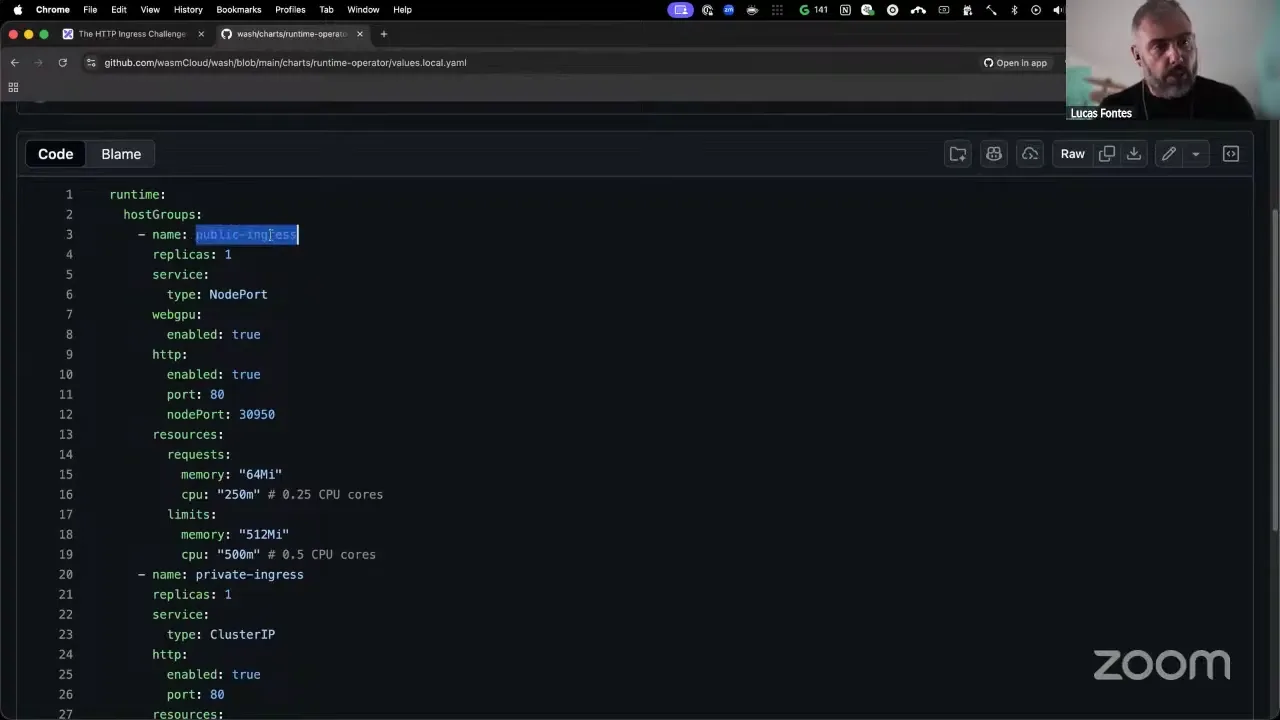
Lucas Fontes 11:00
So all of these are pretty challenging, and the answer — how do we fix this? — really depends. If we look at what the suggestion is today, how we instruct people to handle the situation in wasmCloud v1 and wasmCloud v2: if we look at the Helm chart we have in the wash repository for local development, we'll see that we declare three host groups — one called public ingress, one private ingress, and another one default. The idea with these three host groups is that if you need a component that serves HTTP, you place it in the public ingress; therefore that's the place where it's guaranteed that you can send requests and they will be fulfilled. The other two host groups: one is for internal — meaning exactly like the public, but intended to not be placed on a public load balancer — and the default host group is for those workloads that don't need HTTP ingress at all. They are not an HTTP server, so they are reacting to NATS messaging, they are processing things via key-value watchers, so they don't receive requests via HTTP.
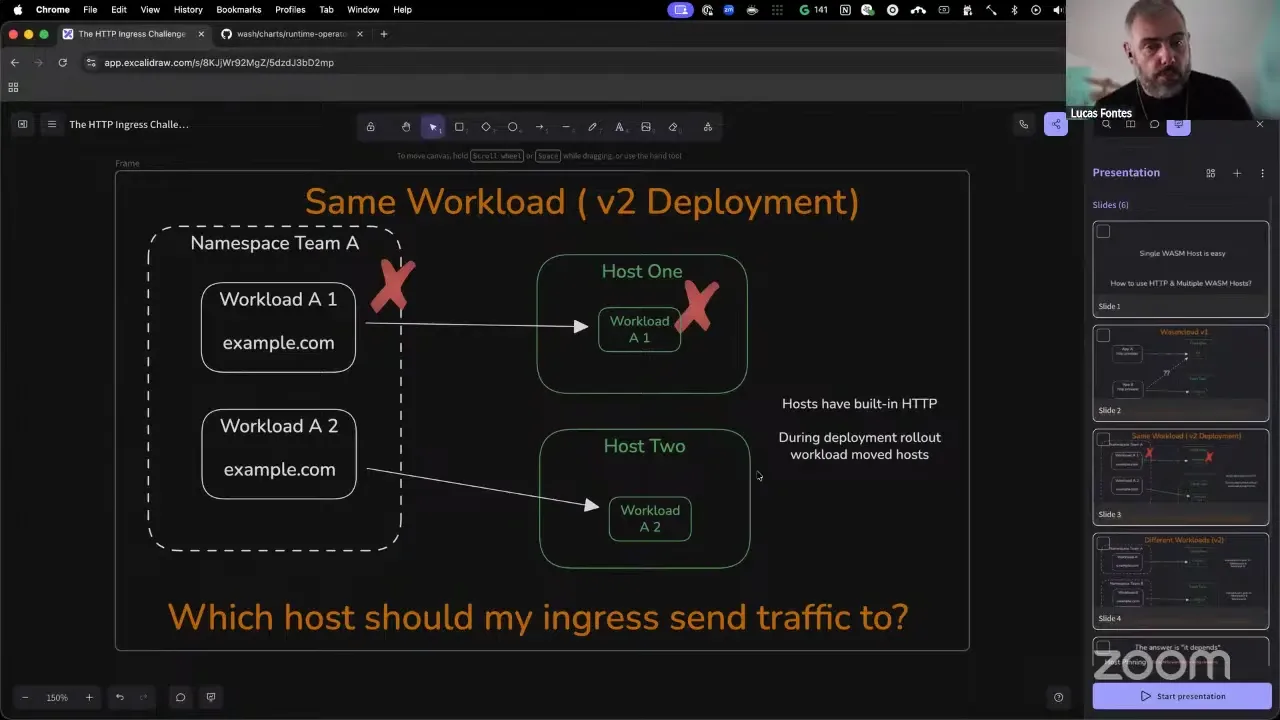
This means that you are forced to always place your components in this public ingress host group in order to have HTTP. And this works — however, it starts to become a bit expensive in terms of containers, because now we're supposed to use WebAssembly to pack more workloads on the same hardware, and here we are telling you to actually run more containers so you can do HTTP routing. So it defeats a bit of the purpose, but it works.
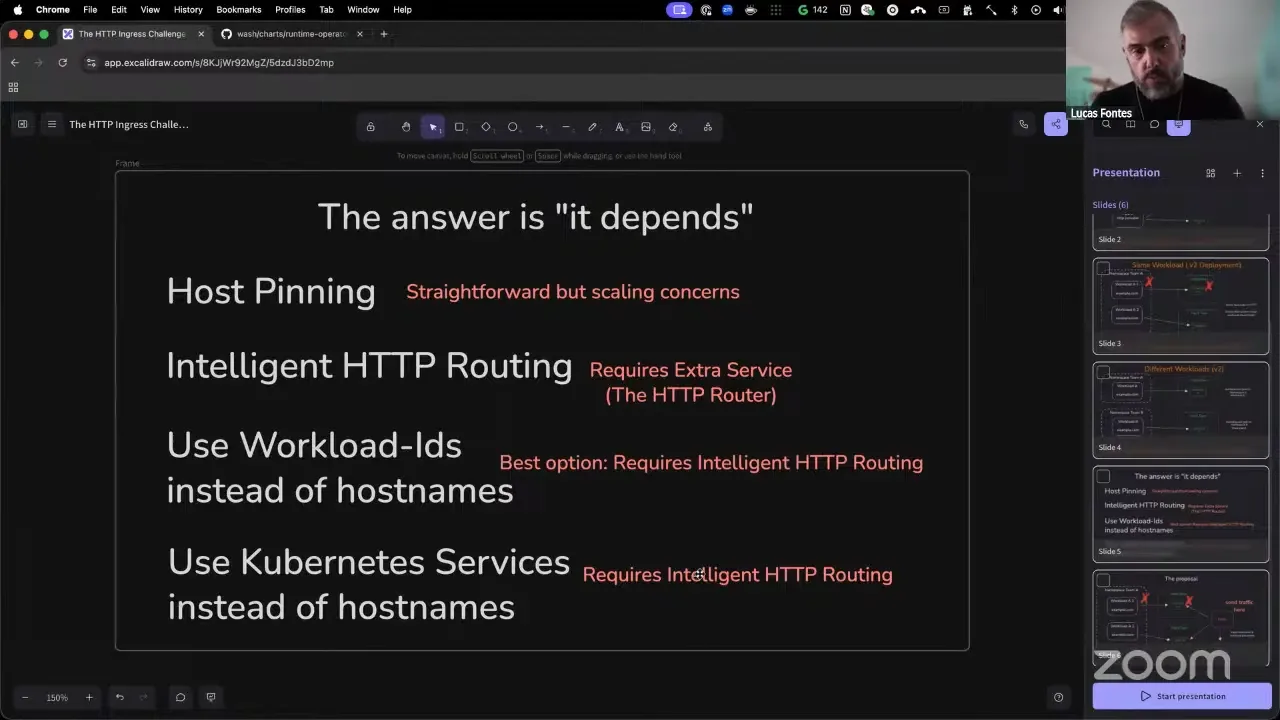
Lucas Fontes 14:30
The other angle is we can do intelligent HTTP routing, meaning we have something that receives the request for example.com, looks at the workloads we have deployed, and routes the request to those workloads appropriately. This is a good one, because the idea is essentially creating the ingress layer — you have an intelligent HTTP server in front of everything that is capable of translating the host names coming from the client side to the correct host on the wasmCloud side. This would fix the issue of knowing which host to send requests to, but we still have the issue of multiple workloads requesting the same host name. Should this be allowed? Should this not be allowed? And the answer, again, it depends. To get around that, one of the ideas is: you don't route using the host name that the workload declared, you use the workload ID, which is a unique identifier for that component inside a given wasmCloud host. By doing this, if that component goes down, you're not susceptible to sending requests to a place that is not able to respond, because that workload ID is ephemeral — as soon as the workload is removed from the host, that workload ID will never be reused.
The other point here is using Kubernetes services. This is not the best option. Using Kubernetes services would essentially, instead of giving you an intelligent HTTP router, replace the host name inside the workload with a service name in Kubernetes, and any time you add a new component, we would go to that service and add the component as a service endpoint — so essentially we're forcing Kubernetes to be part of the HTTP routing strategy. For that reason, thinking here that we really don't want to tie wasmCloud to Kubernetes, the best option is the intelligent router, and not the Kubernetes-services one.
Lucas Fontes 17:30
So the proposal here is: we're going to develop the ingress, which is an HTTP server that's going to sit in front of all wasmCloud hosts. As we see the host name declared by workloads — for example, example.com — if we see this hostname on the ingress, we have information from the Kubernetes API about the host placement. Therefore, we know we have to route this request over to host one or host two. In this example, we have a workload deployment in this namespace; the first version was deployed, landed on host one, we were sending requests there. As soon as workload revision two comes in, the Kubernetes API — which is the one holding all this state — is aware that this is not the correct placement anymore, and now we should be sending requests down to host two. This means that in terms of outages and zero downtime, the perception of rollouts from the client side is going to be totally transparent. We are never removing the workload from this host before guaranteeing that the new revision is up and healthy. Therefore there is no situation where you would get a 404 or 500 because you were in the middle of a deployment. This is a fairly hard problem to actually solve, but here, because we have all this information already available to us, it's actually not that hard.
The question here to the community is more around the need and the approach of introducing a new component to the wasmCloud cluster. With wasmCloud v1 we had wRPC providers, wadm, NATS, wasmCloud hosts; with wasmCloud v2 we have a runtime operator, NATS, and the host — so we don't have a very large number of binaries so far, and bringing in the ingress would add another service to the baseline installation. However, I think just like NATS, this is going to be made optional, because it's one of those things where you might bring your own. You might decide to look at some other information and use Istio, Envoy, you name it — but you'd have to build it yourself. So we're looking at it from the angle that if you're trying out wasmCloud, you should get all the batteries included; anything that we feel you're going to need should be there from day one, instead of forcing people to write their own ingress. And that's everything. So — not sure if anyone has ideas, but this is sort of the direction we're trying to go. Any questions or suggestions, pretty open to hear them. Frank, it's your hand up.
Frank 22:22
Yeah, so FYI, what we do in our clusters is we force all traffic to come to an ingress controller. In this case we use Contour, which is using Envoy, and I think that makes sense to me. That clears up letting the switching between the different versions happen, or even multiple routings and so forth. So I do appreciate this idea. I'm just wondering how you do the mapping between the unique ID of the deployment and the FQDN that you're going to have in front — and at some point are you going to use a DNS, or...?
Lucas Fontes 23:13
Awesome, yeah. So right now in the workload definition we have the host name that you can pass on HTTP, and we also have the workload ID. The workload ID is generated by the host, and you can find that information on the workload CRD itself. So the job of the ingress is essentially to be a Kubernetes cache, which has all the mapping of workload IDs to host names, and that is retrieved by connecting to the Kubernetes API and creating a watcher on the workload type. So this does not need to be baked into the runtime operator or anything — the information is already there. We would be consuming it from this HTTP gateway.
Frank 24:08
And from the point of view of scalability: if your preferred methodology is actually to deploy this on Kubernetes, and suppose that you want to scale up and you're going to be using different nodes — how do you see this working?
Lucas Fontes 24:25
Yeah, now we have two layers to scale. You need to scale your wasmCloud hosts, because you have more components — that's one thing. And you need to scale your HTTP gateway deployment, because now you have more HTTP requests going in and out. They are separate, so I see that we would have something like 50 wasmCloud hosts to three of these HTTP gateways. Another point you're bringing up is how this looks when you bring in an ingress when you already have, like, Contour or NGINX. How would this look to NGINX or Contour? For the Ingress API or HTTP Gateway API, this wasmCloud gateway we're talking about is going to be a target, so you can still configure all your TLS information and your path routing in those ingresses, and when you're telling the ingress where to send traffic to, it would say: send it to the wasmCloud HTTP gateway.
Frank 25:48
Which will be met by a service, right? Because from the HTTP proxy we're going to go to a service.
Lucas Fontes 26:01
Correct. The most important thing here is we could be doing this directly on Kubernetes services by manipulating service endpoints, but we are proposing going in this direction just so we don't box the wasmCloud installation into Kubernetes. Right now only the operator needs to live inside Kubernetes — the hosts can actually live anywhere, and we want to keep that property, because it's going to be really powerful for edge and IoT deployments.
Frank 26:32
No, definitely. Thanks.
Lucas Fontes 26:41
Awesome. Aditya has a question about the ratio. So the ratio here is pretty much coming from the fact that if you look at HTTP load balancer installations — even AWS, if you go to AWS and get the previous version of load balancers, you can actually see how many load balancers Amazon is running for you, just by looking at the number of IPs being returned for the host name. So we see HTTP proxying as a really CPU-intensive but very efficient thing, and the three here is like: you want more than one for failure, and not a lot, because that just becomes you creating a lot. So three felt right — eyeballing, essentially.
Lucas Fontes 27:46
And I also feel like, because this is not actually forcing any change on the existing components — this is something being added on the side here without any changes to the existing code — it's a two-way door. So we can come here next week, take a look at how this HTTP gateway looks, and if we like it, good; if we don't like it, we move it to the contrib directory.
Bailey Hayes 28:31
Lucas, I actually accidentally just muted you — my bad, that was me. But thank you for the presentation, I really appreciated it. Please talk more, but yeah, that's it for our agenda today. Do folks have other questions or other items we want to talk about?
Frank 28:49
I'm just thinking — since we have an open forum now, eventually we could actually leverage eBPF with WebAssembly in terms of all the low-level routing. So that's something to be looked into in the future.
Bailey Hayes 29:08
Yeah, there are actually several different projects that are working on that in the space. If you're interested, Euphoria, I think it's called, out of a Beijing university. I actually got to take that developer out, and she's really bright, and I know a lot of people are building on top of it now. Every once in a while, when I'm floating around in the space, I see that pop up. I know Cisco did a prototype on some of this as well, and all of this is about being able to run WebAssembly in essentially user-space code in what would have otherwise been kernel space, and that's pretty cool. Is that the type of domain you were thinking about, Frank?
Frank 30:04
Yeah.
Bailey Hayes 30:05
Yeah, that's probably the project I would tell you to look at first. Now, I know that Ben Titzer's group at Carnegie Mellon are also doing some cool research in the space. They're very interested in finding cool ways to instrument WebAssembly, even if it's running at that layer. So if you're interested, you could probably talk a bit and see what he's got cooking there. Anybody else have questions? All right — well, we have a lot to do, like cutting a release candidate right now.
Frank 30:50
Definitely waiting for them.
Bailey Hayes 30:54
There's a lot of people waiting on that one. Colon, did I see you come off mute — were you gonna say something?
Speaker 5 31:02
I don't know. I think right now most of my issues are: assuming I need to import WebGPU into the WIT, which I think I do. It's just with bindgen stuff — like, you've got the basics working, but WebGPU is a very complicated WIT, and things need to be put in the right order.
Bailey Hayes 31:20
Yeah, it's a lot. When you sent that message, I went and looked. Inside wash we have our examples, and we have a WebGPU example now — a Rust one. If you look at the WebGPU one, that's where it actually is using that specific version of bindings, so we know that version aligns with the version of what we're embedding. So you would have to go — this is where we're getting those bindings, from this crate.
Speaker 5 32:14
Right. Okay, but is that available in C++?
Bailey Hayes 32:19
Great question. I think what I would do is match what this was doing.
Speaker 5 32:27
Okay, so you don't have it in the WIT bindings? Because the bindings didn't match what the GFX thing was. So I was like, oh well, it will match if I import the WIT file so it matches — but it's just not generated in order.
Lucas Fontes 32:45
Yeah, if you go to our world — to the wash one — I think it's gonna be on the crate. The wash runtime with the world. It's not even here, because it's coming from — exactly — but it is being exported as WIT. So the graphics context, the WebGPU handle interface — I can't remember exactly, but they are there. The Rust code that we were showing before is pretty much shimming all of that, but the WIT interfaces are being exported by the host.
Speaker 5 33:40
Yeah, no, I know it's on the host side. The problem is the WIT — whatever the WIT is, even if we're not explicitly importing or exporting it, is different because the interfaces are different. So that was the issue before, and I'm using all the right versions, so it's a little — I don't know, that's my issue right now.
Lucas Fontes 34:13
I think we're gonna be able to get the release out in the next 30 minutes or so.
Speaker 5 34:18
Yeah, I'm just using Wasmtime at the moment, because I couldn't define the wash config JSON in a way that could get it running with wasmCloud — I don't know what that would be for C++. So that's it, I guess, but we'll continue on Slack once you get it out.
Frank 34:49
Lucas, for the prototype of the ingress — do you have any idea when you'll have something that we can play with?
Lucas Fontes 34:59
Soon — kind of half joking, because this is something that's been cooking for a while, and we have a pretty decent way to solve it, so we might have something by the end of the day as a pull request.
Bailey Hayes 35:27
All right, let's go do that. Thank you, everybody, for tuning in.