Transcript: C++ Wasm Components, gRPC & the Wasm Component Model in wasmCloud v2
wasmCloud Weekly Community Call — Wed, Nov 26, 2025 · 36 minutes
Transcript
Bailey Hayes 06:17
It always has this — I never know when it actually starts. Hello and welcome to wasmCloud's version of turkey day, before Thanksgiving in the US. It's November 26 and I'm excited to have everybody here. We have a very lightweight agenda, although I actually realized I do have a demo to show, which I'll run through. But before I do that, I wanted to show our Doc of the Week change, made by Eric. I'm just going to share my whole desktop.
This is for wasmCloud v2. Note we agreed last week to do a .x version here — I haven't made that change in the docs yet, because we're technically on RC2, about to cut RC3, but we're going to only keep one version of the next version of the docs. Eric created this overview section, which includes a lot of the new types we're talking about, the goals of v2, how plugins work, what the interfaces are, how transports work, and how you use wash to do your OCI packages. And probably something a lot of people were asking about in our last community call as a request — Eric put together a section on how to migrate from v1 to v2. So there's a lot of good information here.
Now, notice that I'm doing this off of a preview — it's in review right now. Eric is already on holiday, but we'll look to get this merged when we get back. The pull request is this one, so if folks want to comment or ask for more things they want to see, please jump on there and give us feedback. Any questions on that topic?
Okay, so I want to show you something else that we got together over the past little bit. It's now hosted at the Bytecode Alliance — I initially started it in my own personal repo and moved it over yesterday. It's a sample for building with wasi:http and doing C++ style bindings — not just C-style, but actual bindings that use modern C++, and you can make something really ergonomic and nice with it.
Let me show you what that looks like. server.cpp is basically our main function here, and it has a top-level handle method. It takes in that query, parses it — we're using auto and basically all the good things you want to see with modern C++ — and we're doing it via streams, then sending our response back. There's a little bit here where you've got to set it up the right way for doing exports building with WebAssembly, but I think it's pretty clean. I ran make release and I print out the size here: it's 67 kilobytes, which is pretty tiny. I like seeing WebAssembly that's just in kilobytes.
If I want to actually serve it, I'll do make serve. If I do hello, it gives me a Hello World response. If I do echo and say "echo something" or "hey wasmCloud," it'll echo back. So it's pretty simple. The reason it's cool and new and worth showing off is that this is all only available starting in release 48.1. I took all of Christophe Pettit's awesome foundation for being able to support C++, then expanded it out to support basically every case, and now it's feature-complete.
I'll give you some more details too. In the WebAssembly space, usually all my recitations — a lot of people on the call are mostly Rustaceans — fall asleep on me when I talk about C and C++, but C and C++ have had amazing support for WebAssembly for a long time, and there are some pretty cool enhancements coming down the pipe right now. There were a number of WIT use cases that weren't handled when I started working on this, and now they're all handled. The only things still missing after 48.1 was released are the WASI P3 bits. So I haven't taken on implementing WASI P3, but WASI P2 is now feature-complete — you just have to use the latest version of wit-bindgen to take advantage of that.
For P3 I did come up with a sketch for how I think it should work, and I've been hashing it out with Christophe Pettit, who runs a lot of the wasi C project, and also with Cy Brand, who's a pretty awesome engineer in the C++ space. I'm really excited they're working on WebAssembly. There's wasi-libc now, and we actually rely on a library they created for us to be able to do expected. We were able to back-port even some things from C++23, so we've now all decided our baseline is C++20 — very beautiful, modern C++ — and what that gives you is coroutine support. Coroutines have this really great alignment with a new feature coming down from the component model called cooperative threads, which will basically mean I can do real P-thread-style threading once Cy — who's working on this — and wasi-libc are ready. Let me show you a little bit of this.
Bailey Hayes 12:51
I bet I could, Frank — I bet I could get envoy compiling. I'm getting pretty far, and it's something I've tried before. I was able to get something running in a browser back in the day, about six or seven years ago, with Emscripten. Now I'm slowly unwrapping this whole big onion that is how all the SDKs come together.
The WASI SDK is obviously designed more for WASI. There's this other SDK called Emscripten, which started by targeting C and C++ projects for web environments, so it adds a lot of JavaScript glue to make things just work in a web world. They've got their own emulator for P-threads that uses web workers, and an in-memory file system they implement stuff on top of. It's actually great — a ton of sites are built on top of it (Autodesk, Adobe, basically everybody), and it's largely maintained by Googlers now, but it originally started at Mozilla, which I think is a fun fact.
So wasi-libc here is the guts of how we support a lot of things — even the Rust side of the world actually depends on this project. It's bundled into the WASI SDK now, and wasi-libc has been growing rapidly so we can support some of these new component model features. In the next version of the component model we'll have cooperative threads, which will allow us to do both threading and this type of green threading and coroutines — go-routines, if you're in Go — essentially a more modern way of creating lightweight threads on top of this cooperative thread model. So coroutines are going to be a lot more lightweight, probably a much better interface for bindings. Inside the component, when I compile something like envoy, I'd use threads on the inside of the component, but the boundary for what I hand to other people I want to be this lightweight async thing, where they can call out and call back into me.
So I'm getting really excited about the C work happening here. I think the top three big-ticket items about to land are: threading (maybe a month and a half away, which is really soon), cooperative threads, and exception handling. We've landed exception handling fully inside Wasmtime now — it's about getting the producer toolchain inside wasi-libc to support exception handling out of the box for C++ exceptions and setjmp/longjmp.
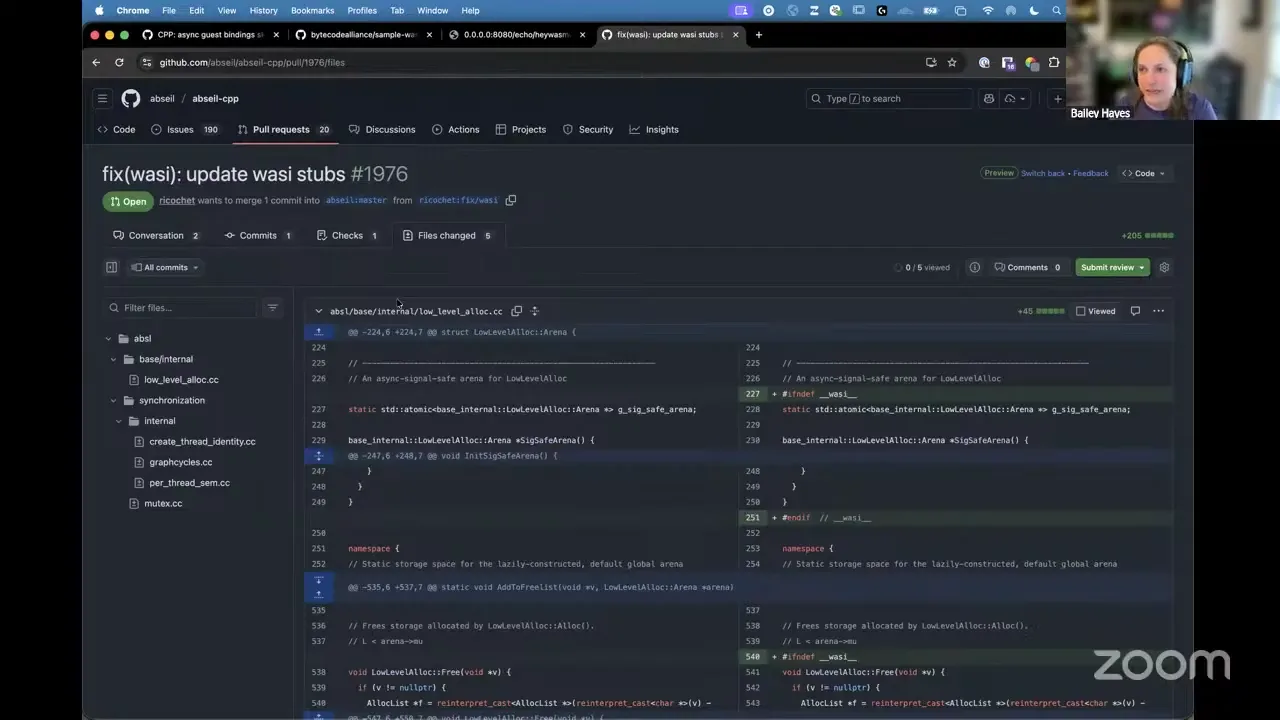
Now, something else I did that might be interesting: I also got abseil building out of the box with the latest and greatest. I've got wasi-libc, which would allow me to build WASI out of the box today without waiting on cooperative threads. If you don't know about abseil, that's okay — if you're familiar with boost, it's basically modern boost. There's a ton of projects you can build on top of it, including protobuf.
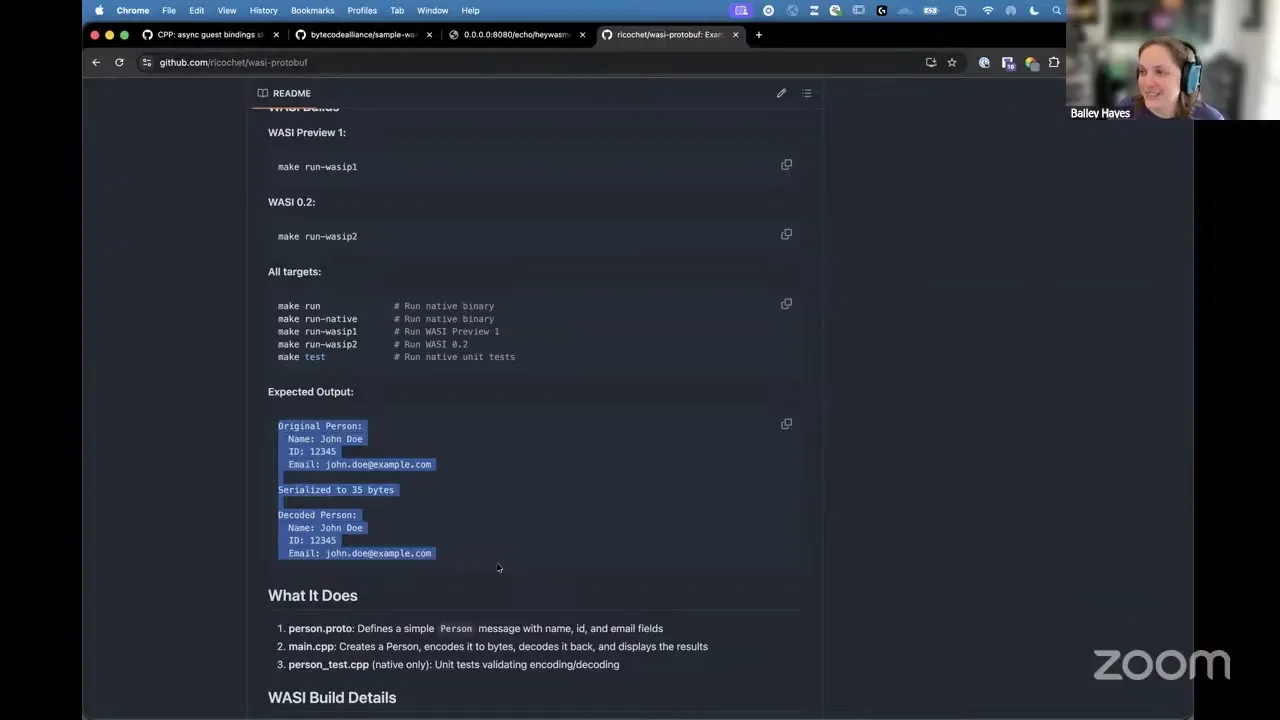
So once I updated abseil-cpp, I was actually able to build protobuf fully. Let me pull that one up. I ran a little command — you can make for both WASI P1 and WASI P2 — and protobuf is basically working, outputting a serialized and deserialized version of protobuf. That was a project where before, people had to come up with a lot of different weird custom build hacks, and now we've been landing changes all the way upstream so people can just take it and compile out of the box.
So I see your challenge, Frank, for getting envoy compiling to Wasm, and I think it's possible. Certainly the best time to try it would be right after we get cooperative threads and exception handling — most things in C++ will just build, and that is really stinking cool. So that's my demo.
Liam Randall 17:34
That was an incredible demo. I think this is the best time you've ever connected all the dots between the work around C++ coroutines and cooperative threads — that was the most salient and simple explanation we've ever done, so thank you for that. Talk to me a little more about the protobuf piece. gRPC is such a key piece of the ecosystem. What are the steps to really get all of this working across components and around the ecosystem? I assume other people on the call are thumbs-upping — that's what's on their mind too.
Bailey Hayes 18:18
So a lot of people pair gRPC and protobuf together, because obviously protobufs are the types you're sending over the wire, but gRPC itself is its own networking protocol for sending those messages. It's important to decouple those, because they're different layers I have to get implemented.
For the protobuf side, there are only a few things most people are already familiar with — like running the protoc command locally to generate your code. Then inside your application code you compile something that knows how to serialize or deserialize those types, and that's what this project does. Specifically, just protobuf types, serialization and deserialization. If you look at the source code, both native WASI P1 and WASI P2 work with this project, so if you wanted to grab it, just try it — it'll work. I ran protoc, I got my little stubs for what a person is on my person type, I'm able to set ID and email for that person, and then I print it out at the end. Dead simple, but it proves that part of the ecosystem compiled and is working.
Now, what you could imagine is taking what I have here and putting it behind a handler. In server.cpp, instead of a Hello World handler inside my handle, I'd want a gRPC handler. But there's something else that has to change: I have to handle the way I'm doing my HTTP calls to actually do gRPC instead, including the body format.
Bailey Hayes 20:41
Some people have proposed ideas — note this isn't implemented or a real thing — like, "why don't we just have something that literally says its exact protocol and behavior as part of the definition?" This didn't go forward, and nobody builds on this type of thing, because you don't have to.
What's important about wasi:http is that it's actually designed to be protocol-agnostic, so you should be able to pass in the appropriate headers and body format and give enough information to your wasi:http server implementation to know what type of protocol it's supposed to be providing. Today, most people do gRPC with HTTP/2, which means if I pass in a header that says I'm doing HTTP-style streaming — the TE header — and pass that through my HTTP server implementation, it should know that's the protocol it needs to connect and set up. So for the most part, all of that is not in your guest code. You do the serve side of the business logic with wasi:http, but it's basically just wasi:http streaming. The actual interesting implementation happens outside this code — in the runtime and the HTTP server side.
Liam Randall 22:20
This is awesome, and it feels like a pretty important milestone for us and WebAssembly. So thank you for all the hard work grinding on the details here, and all the collaboration.
Bailey Hayes 22:42
And note, Aditya has also been innovating in this space. Aditya, you did the Rust version of this — do you want to talk about that? If you don't want to talk on the call, that's okay too.
Aditya 22:55
Yeah, sure. I haven't prepared anything — it's going to be ad hoc. So what I built was to basically make use of wasi:http and, as you said, just add the application/grpc header while making the gRPC call, and that should pretty much be it. Tonic takes care of the protobuf bindings, and we're basically calling a tower service to override the default service that Tonic uses and call the wasi:http outgoing handle. So in a way, it ad-hocs its way over to our HTTP server, where I've also implemented gRPC client support directly into wasmCloud.
Bailey Hayes 24:10
Yeah. So we're still working on landing a number of things. Last week, Lucas demoed our ingressing story for HTTP inside the wasmCloud host, and we rejiggered a lot of that. Now we're ready to start adding a lot of these enhancements on top. I think probably before the end of the year we'll have really great gRPC support built into wasmCloud — thanks to Aditya and Lucas on that work. Any questions, y'all? We're a little light, as Turkey Day's tomorrow.
ossfellow 25:01
I have a quick question — not about C++ or gRPC, though it's kind of related. It's about version two, and the fact that Kubernetes is the default scheduler. My question is about workload identities. In version one we talked about workload identities for a while — Joonas did that implementation at the time. So in version two, because of the closer relationship with the Kubernetes environment now, would we consider workload identity to be a core feature, or a customization we apply to our own hosts when we customize them?
Bailey Hayes 26:20
I see it as an external feature. We handle ingressing into components, but a lot of people have their system set up in a way that already defines their workload identity. So instead of us creating our own isolated island of how everything has to work — and then other people have to match us, which was one of the problems with our original POC, where it really leaned into NATS-style auth and made it incompatible with what people were already doing with mTLS, workload identity, and service meshes — the short answer is you do exactly what your service mesh does, and that's what gives you workload identity. From our perspective, we're agnostic about how it gets implemented.
Bailey Hayes 27:33
Lucas, do you want to say that comment out loud? Or I could say it out loud.
Lucas Fontes 27:38
Sure thing. In v2, workloads carry the name and the namespace from their original request — whoever wanted to start a workload. So the key inside each host: we keep all workloads keyed on namespace and workload name together, and each workload has a workload ID. From a scheduler's perspective, you tell it something like "namespace default, workload HTTP server, and I want my identity to be X." Now the scheduler has the opportunity to go to all the hosts that will have to deal with that identity and prime that identity — essentially tell it, "hey, get ready, you're about to receive the workload default HTTP server." After that happens, we send the workload there. So identity now becomes part of the scheduling operation; even if we know that identity cannot be assumed or impersonated in a given host, we don't even send the workload there. Whereas in v1, workload identity was tacked on top — the host participated a lot in creating the identity for the component it was about to schedule. This means the integration for identity in workload v2 is going to be way simpler, and when we enable it, we're enabling it for components, not for the host. The identity of the host isn't really interesting to have. Does that make sense?
ossfellow 29:50
Yeah, it does. In v1 it was really an identity-delegation kind of scheme.
Lucas Fontes 30:04
Exactly, right. So now we're moving away from delegation to a real assignment. The host doesn't need to participate in the identity of the component.
ossfellow 30:19
And that's something I wanted to ask you, Lucas. When you say "workload," because workload right now in v2 is a loaded term — in this context, are you talking about the individual components, or what we define as a workload?
Lucas Fontes 30:41
What we define as a workload. The boundary we're drawing for v2 — you can think of it as the application within the YAML. That entire YAML gets the same boundary, so if we tell it has a specific permission, the permission is for all the components within that boundary. The idea is that what you're composing with a workload is now more analogous to fulfilling a WIT world: you carry your entire world, and as you need to communicate with other components or other pieces of your infrastructure, you use RPC and you're explicit about those RPC calls. The interesting part is, as workload identity comes in, it'll be part of this RPC communication across workloads — because if you use wasmCloud messaging, we know the identity of your components, we know the identity of the component you're trying to reach, and we can essentially provide ACLs at the scheduling layer. So you can imagine creating a YAML inside Kubernetes, or any other scheduler, that looks a lot like an RBAC rule, where you say, "I want to allow component workload HTTP server to talk to my payment API, which is internal."
Frank Schaffa 32:20
Understood, thanks. So this begs the question — because we're getting to RBAC security and so forth — can somebody then take over some identity and use it for other things? What's the control there?
Lucas Fontes 32:41
So the control here is the scheduling operation. As we tell the host "please start this workload," everything happening in that request pertains only to that workload. Whereas before, the identity was part of the host, and the host was delegating to components — meaning if you schedule a component with the same name on the same lattice, it's doing workload identity takeover. That was the challenge with v1: we had no way to prevent components from taking over each other's names and identities; there was no unique ID involved. Now we've introduced a unique workload ID for every single component. So even if your component is named "HTTP server," when it goes to the host it gets assigned a unique ID — and this can happen many times.
Bailey Hayes 33:49
I think one of the key points Lucas is making is that this isn't part of the host authority — the host doesn't make any of these calls. All of those decisions happen before it gets to the host. So if you have something like SPIFFE/SPIRE set up and you're doing cert termination, you're doing that at the ingress layer before it gets to the host — at your proxy. If you're using something like envoy, it handles multiple different certs, and you're able to do the unique identifier for the workload at the ingress layer. Then in terms of RBAC, what Lucas was talking about doesn't have to be Kubernetes RBAC — it could be abstracted — but essentially with Kubernetes RBAC we've got these workload types, we know exactly what they are once they're resolved, where we want to deploy them, and what makes them unique.
Frank Schaffa 34:52
I'm still digesting this, but just from a semantic point of view — would it make sense to call this a unique identifier instead of unique identity? Because "identity" is a very loaded term.
Bailey Hayes 35:21
Yeah, I agree. All these terms are so loaded, aren't they? Even "component" — to us, "component" obviously means a WebAssembly component, but to the outside world that's not a given. Any more discussion items on that one?
All right, well, I think that's all, folks. I hope you have a really good rest of your week, and if you're celebrating Thanksgiving, enjoy lots and lots of turkey.