Transcript: WebAssembly on Kubernetes: v2 Helm Operator, wash HTTP & WASI P3
wasmCloud Weekly Community Call — Wed, Nov 19, 2025 · 62 minutes
Transcript
Bailey Hayes 05:16
Okay, hitting the button. Alrighty — hello and welcome to our community call for Wednesday, November. We've got a number of community updates, and we're going to start with basically our doc of the week, but also a cool demo of the week, starting with Eric. Take it away.
Eric Gregory 05:34
All right, hey everyone. So we just put up — I think it went live today — documentation for installing the v2.0 release-candidate-one runtime operator. Is that working now? Success. Love it. So over here are the v2.0 RC1 docs. We've got a few pages we're really trying to build out, and that's just going to keep moving quickly over the next weeks and months. But our big new thing here is on the Kubernetes operator page: we have a breakdown of the pieces that constitute the wasmCloud platform on Kubernetes — an explanation of how, in addition to our wasmCloud operator custom resource definitions, we use wasmCloud hosts, and that's with JetStream. And then instructions for getting started.
So we'll just walk through it live. First, a local Kubernetes environment — and we're going to use kind, because that gives us a really smooth experience for ingress and local development. This curl command here is a one-liner that's going to download this kind config, start the kind cluster using that config. And there we go, we've got our cluster.
So now we're going to use Helm to install the wasmCloud operator from an OCI chart image. In this case, we're going to use values for local installation that are hosted over at the wasmCloud runtime operator repository. So again, a nice little one-liner here using Helm. And it might be worth having a look at those values to get a sense of what we're doing. We've got a couple of named host groups that we're going to install: public ingress, which gives us ingress we can access from outside the cluster using node port; private ingress, which uses cluster IP, so that's for our workloads talking to one another within the cluster; and a simple default host group. So now we've got wasmCloud running on our cluster, and we can check — we've got those three host groups, we've got NATS, we've got the runtime operator, and that's all running.
So now we can deploy a Wasm component, and we're going to do that with the workload deployment manifest. Here's what that manifest looks like — pretty straightforward. We're going to be using this Hello World image, using the HTTP interface, and a little bit of config. We're calling our host "localhost." So we can apply the manifest from where we have it hosted remotely on GitHub. Our Hello World is created there, and we can go ahead and check on the workload — looks good. Let's give it a curl. We're just curling localhost with the -i flag to show headers, and there we are: "Hello from wasmCloud." So, quick end to end — just three or four commands, really fast to get up and running. We'd love for you all to give this a try. Kick the tires on RC1, point out the rough edges so we can keep making it better.
Bailey Hayes 10:02
That's awesome, thank you, Eric. One thing, though: I haven't gone and updated the docs — we're actually on RC3 now. It was mostly all just small patch fixes between RC1, two, and three. Oh, well, there was one not-so-small thing, which was updating to support WASI WebGPU, which Mindy and Colin showed off at WasmCon. That was one feature that got landed; otherwise it's bug fixes. We could update the doc, or — I might suggest we be prudent here and just update the doc to say "RC dot plus," so it'll just be the rolling latest that we have. Okay. Any questions, folks? That was awesome. Eric, you're so smooth, man. You know who else is smooth? Lucas. Lucas, you want to tell us about HTTP implementation?
Lucas Fontes 11:33
All right, thanks. Let me put things on the side here. Nod your head or make some noise if you see my screen — okay, thank you. So I'm going to talk a bit about the runtime, the wash runtime, which powers wasmCloud v2, and HTTP, and how we got here. In wasmCloud v1, if you want to expose anything through HTTP, you bring up a wRPC HTTP provider, and that's where the routing logic resides. With that information, you receive your HTTP request on that wRPC provider, and requests are then sent over NATS in wRPC to an individual host. This approach requires that all your HTTP processing happens somewhere else, in a different process. It introduces one extra network hop between the wRPC provider and the wasmCloud host — and it's even a bit more complicated, because it's a network hop going through NATS, and every single WebAssembly call is being proxied over this.
So this pretty much says that in order to get really good performance out of wasmCloud, we need to stop using the wRPC HTTP providers for ingressing traffic into the cluster. This means bringing that closer and closer to the runtime. This was a key design choice in the wash runtime v2, and we took that at the very beginning: we can create an HTTP plugin, and if anybody needs another HTTP plugin, they can implement their own. It's easy enough that somebody else could do it as well. But then it turns out it was not that easy. As soon as we saw the pull request from Aditya — he was trying to add a wash HTTP client and a gRPC client plugin in a way that we detect whether a request is gRPC or not, and we use a different plugin depending on some information from the request itself. As we started looking at this implementation, we realized we had a really heavy dependency on the Wasmtime wasi-http crate, which was forcing us to funnel all the calls through a single interface, where we needed that to fan out to two different interfaces: the HTTP plane and gRPC. So we asked Aditya to kind of hold a bit, because we had a plan on how to unroll the situation. The goal is for us to have a solid HTTP implementation inside wash that supports HTTP, gRPC, HTTP/2 — all the nice things — and not have people implement their own WASI plugins all the time when they need a different HTTP routing strategy.
So we pretty much decoupled the HTTP implementation from what you want HTTP to do as a client and also as a server. Then we come over to this other pull request, and what we're doing is solidifying the fact that HTTP is tightly coupled to the Wasmtime context. This means we are bringing in WASI HTTP as something that will always be present in the runtime, but you can enable it or disable it depending on your use case. Two things can happen. You might choose to implement a router, where the only thing you're concerned about is allowing or denying HTTP requests from components. Or you want to implement a whole new HTTP stack, because maybe you don't want HTTP to go out to the internet at all — you want to fake all the requests internally, or maybe you want to send all the traffic to a service mesh. So for those cases, for full completion, we now have two different ways to integrate HTTP with the runtime. One is, "I want to bring everything — the HTTP server, the client," and for that I'm going to implement a host handler. Or, "I'm just worried about the logic; I want to plug this into a different XDS, or into a different gateway on Kubernetes," and that's where you'd use a router. So how does that look, and what's the actual difference? I'm going to get to the diff.
Lucas Fontes 17:31
So this is the README for the wash runtime, and we see that the key differences are: we're no longer importing the plugin. We're now bringing the HTTP server straight from the runtime, and we're also bringing in a dynamic router, because we already have two consumers from HTTP — we have wash dev and we have wash host. We're providing two router implementations here that show how to implement your own. In this case, we're bringing in the dynamic router. Instead of configuring an HTTP plugin and adding it to the host builder, you now construct it here, passing the router, and then you pass it in as a special HTTP handler. You can only pass one HTTP handler — that's going to be the one responsible for HTTP throughout the entire runtime — and this way plugins can get access to that HTTP exit point of sorts. The two key implementations are the dynamic router for the clustered environment, and the wash dev router, which always sends the request to the same workload. If you don't provide an HTTP handler, that means all the outbound HTTP requests will be blocked — we're doing deny-all by default, exactly because you should care about enabling HTTP or not.
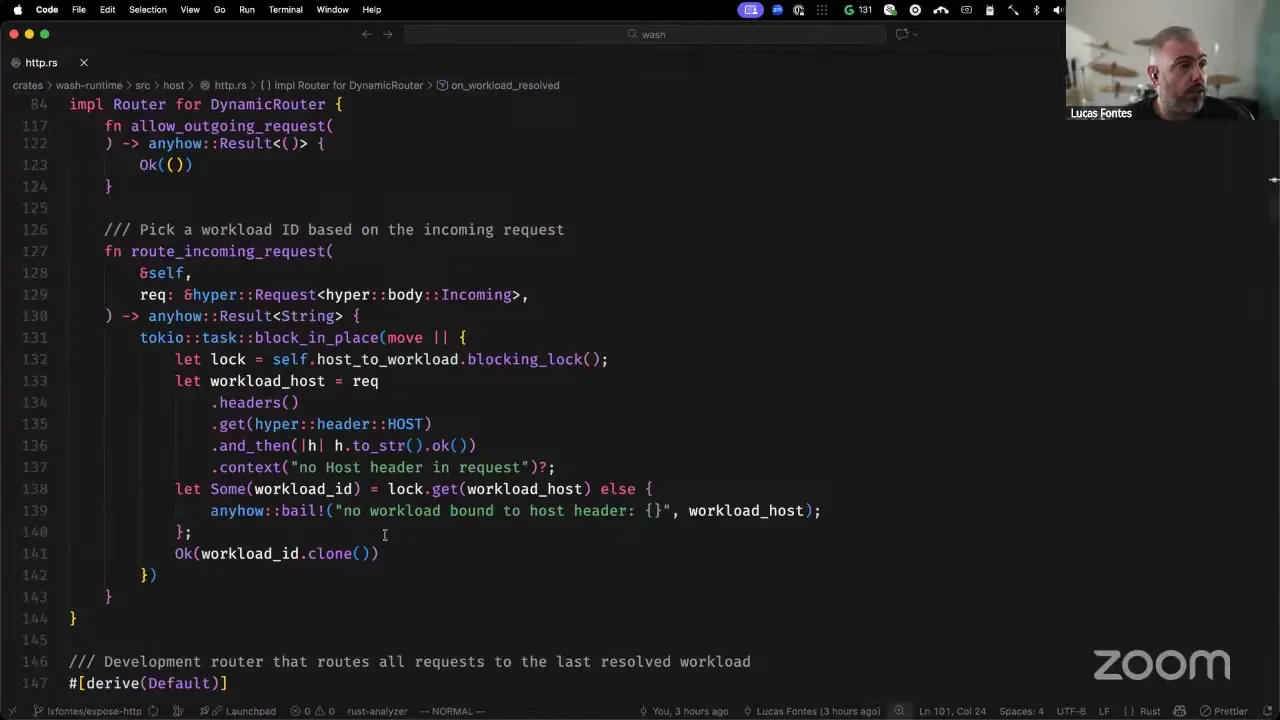
Let me quickly show how these integrations look. For the case where you're implementing just the logic, you implement a trait against this router trait, and you have two core callbacks. One is "on workload resolved" and the other is "on workload unbind." When the workload is resolved, that means the runtime received an external request, processed all the components, linked everything together, and now it's ready to start serving it. At that point we call the router and tell it, "hey, I have a workload here that has all the components ready, and it has HTTP — go configure it, update your internal state any way you want." And we have another callback, "on workload unbind," for when that workload is stopped or errors out. Then we have the two HTTP-related callbacks: one for allowing the outgoing request — in this case we receive the workload ID trying to do the request, a reference to the actual request going out (please don't touch it, because if you consume any bytes it's going to break), and the config, which is the Wasmtime HTTP config. This is for outgoing requests — pretty much the HTTP outgoing handler. For incoming requests, we receive the raw request as a reference and return a string, which is a workload ID. So in "workload resolved" you have the workload ID; inside this handler you'd likely put that information in a hash map you're storing somewhere; and in routing incoming requests you'd look that up. That's essentially what the dynamic router does: it gets the workload resolved, checks if we have the incoming handler, gets the host from the configuration, and adds that to our own hash map. When the request comes in, we get the host from that request, look it up in our map, and that's it. The runtime has all the information it needs already to process the request — it knows the workload ID, knows the handler, and has a pre-warmed instance ready to serve.
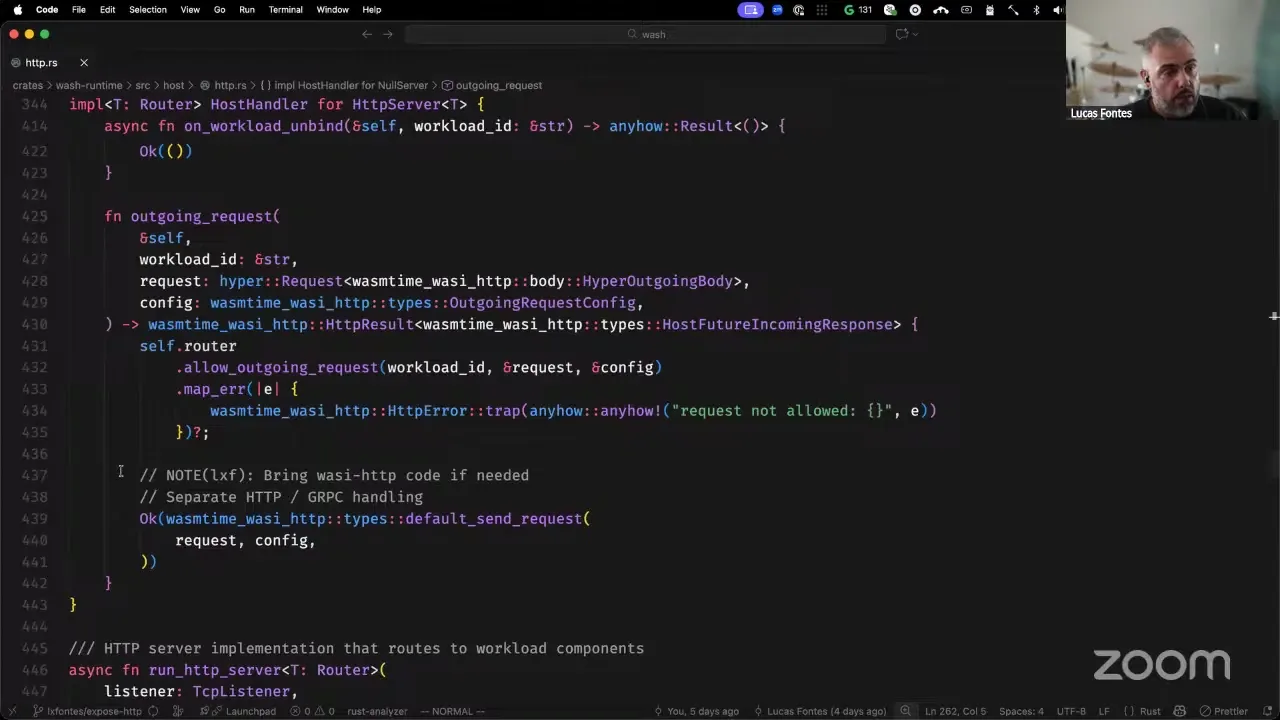
We have the wash dev router, which is similar, but the only thing it does is track the last workload ID — every time there's a new workload, we just replace the previous one. Now, if you want to integrate more tightly — you're implementing your own HTTP transport — then you implement this host handler trait. This one calls you back when it's time to start or stop, so you can bind sockets, bring up the HTTP server, and so on. It also has callbacks for the workload resolved, but it will not have any callbacks for incoming requests, because you're supposed to do the incoming request yourself. For outgoing requests, because this is plumbed to the Wasmtime context, we have it here. The same way we provide implementations for the router trait, we provide two implementations for the host handler trait: one that is a no-op server — every time you try to use HTTP it says "no, you're not going anywhere" — and another that is the canonical implementation, doing the same thing the WASI plugin was doing up until two days ago. We can also create the HTTP server with TLS — all those things are kept; it's exactly the same implementation, just in a different place. The other thing worth mentioning, related to Aditya's pull request for the HTTP client and gRPC: now we know exactly which points we need to add the gRPC logic. So instead of having a specialized plugin for gRPC, we have a flag saying "yes, this component is allowed to do gRPC or not," and we get that information via the configuration for the component. So, lots of code changed, but the behavior remains the same — wash continues to work the same way, no argument changes. The only difference is in the plumbing between wash and the wash runtime. I talked a lot — any questions or comments?
ossfellow 26:19
Some of them got answered. This is still based on the Wasmtime HTTP, right?
Lucas Fontes 26:26
Correct, yeah.
ossfellow 26:46
One thing you mentioned is that a runtime would have only one HTTP implementation, right? And that means transport is a layer over that HTTP. So I have one — but now this component is gRPC, and that component requires, I don't know, QUIC, and so on. And all of them are still being supported on the back of that?
Lucas Fontes 27:13
So the challenge we were facing is that the way we implemented plugins works really well if the plugin doesn't require a special context binding. If we wanted to use the Wasmtime HTTP implementation, we need to use the Wasm context — we need to bind to that context, and we start going down a path of many pointers being dereferenced, many types being cast down, and so on. We had to make a choice: stay with Wasmtime HTTP and create this second trait — essentially a specialized HTTP plugin type — or reimplement HTTP entirely as a wash plugin. We chose to not reimplement all of HTTP as a wash plugin.
Bailey Hayes 28:25
Yeah, and I totally support that choice, because Wasmtime is continually fuzz-tested, beaten on at a much broader scale than one day I hope we'll be at — but right now, why not join efforts?
ossfellow 28:42
No, that makes sense. But I have a question that's probably more geared toward you, Bailey — or maybe Lucas can answer — and that's about where wRPC fits in the picture. I know how pervasive wRPC is in v1. Do we still consider wRPC to be the transport layer between, let's say, a distributed host implementation of wasmCloud? Where does it fit?
Bailey Hayes 29:32
Yeah, I'll give my answer, and then, Lucas, I'd like to hand it to you too. The way I see it is that a host is its own world — I hate to use the overloaded WebAssembly component term for that, but that's how I look at it. I don't really expect hosts to work in a ring together; when they're doing that, they should be using some type of remote protocol. That could be over wRPC, if you have two components remoting to each other. But the way I see the world is you should just use either an event bus or an HTTP call, and then you get very transparent errors and network handling specific to exactly what you were trying to do. The scenario where we were trying to fit different hosts filling different niches in a cluster worked out to be magical in the bad sense — magical with unexpected pitfalls you couldn't really code for ahead of time, and definitely all the mistakes made in the CORBA era, if folks remember that. So I know you're trying to figure out where wRPC fits in this equation. I still think it's really nice ergonomically: if you're in a completely component-native system and you want to communicate over wRPC, you may want to literally have an interface that is wRPC-namespaced, and then it's very transparent that you're doing a wRPC-style RPC call. I think that makes a ton of sense. The reality, though, for us today — what's our 99% use case? They're doing HTTP or they're doing event-bus messaging, and if we have first-class support for those two things, almost every use case people are doing network-wise just works. They're able to build with the libraries they know, their standard libraries, and have things just work.
ossfellow 31:47
Is it fair to say that wRPC in v2 is no longer a core feature of the wasmCloud platform? Like it's demoted to "use it if you need it," but it's not a requirement for distributed workloads?
Bailey Hayes 32:09
It's not core. I see that as nice-to-have, but not part of the MVP, since we've been able to hit the 99% use case today by having people build it into their host.
Lucas Fontes 33:11
I was pretty much going to replay a lot of what Bailey said, just with a weirder accent. But the important thing is that if we look at what wRPC is doing, it's giving us typed, WIT-described remote calls. In external communication with non-WebAssembly services, that can be replaced with wasmCloud messaging — essentially you have publish/subscribe, request/response, publish, and handlers. So wRPC makes sense if you really want to do WIT and you're okay paying the penalty of all that abstraction. If we look at how wRPC works, it essentially gets everything happening in Wasm, puts it into a buffer, sends it over the network — and it has to do that for every single lift and lower operation that Wasmtime is trying to do. That's the difference between being able to do 30,000 requests a second and 5,000 requests a second for a few protocols. So we really didn't feel like, for wasmCloud v2, that everybody should pay the penalty of wRPC when all they want is to distribute workloads. We decided to remove a bit of that facility of the auto-linking and auto-magical component configuration in favor of expediting a lot of the performance.
Frank Schaffa 35:15
Yeah, Lucas, that makes a lot of sense. So what does the HTTP protocol version come into play here? gRPC will force you to use HTTP/2, but you can still have 1.2 and so forth.
Lucas Fontes 35:43
It's one of those "it should work, TM." We're using Wasmtime HTTP, and underneath it's using hyper — it's everything from the default Rust stack. The differentiation between HTTP/1 and /2: I'm not sure we even should make a switch or a flag for it. I think it should just work, because depending on the request, we know the version and can pick a different client based on the request being issued from the component. So I really think that if everything goes fine, it should be totally transparent. If you stand up a gRPC service in a component, it'll just work — you don't have to configure anything special.
Bailey Hayes 36:39
Yeah, so I think today, Aditya, the hyper server crate that's built into Wasmtime wasi-http doesn't have the feature enabled that does the auto-connect switch. But I think that's the route we should take. What it essentially does is what Lucas just said — it looks at the request and does an auto-connect switch based on the protocol. There was another implementation detail there: we had to make sure the te header that gRPC requests use is allowed to be passed all the way through. And it is now, both in the Wasmtime wasi-http and per the WASI HTTP spec itself. The very important salient point about WASI HTTP is that it's intentionally protocol-agnostic. We wanted it to be virtualizable across all these different types of protocols, to make it work for all these different environments. So in theory you can do one, two, and three, if you're in a three-like environment.
Lucas Fontes 37:59
Awesome. And we feel like with this we're pretty close to closing the scope for wasmCloud v2. We probably have to cut another release candidate here and stabilize, write more tests. But I think this is kind of the final cleanup before we have an actual v2 release.
ossfellow 38:26
Lucas, I have kind of a follow-up to what Frank was asking. Most of us on this call know that Wasmtime right now supports P3, and HTTP/2 is really something that comes with P3 for WASI. So is it correct to assume that today — because Wasmtime supports HTTP/2 — there isn't anything on the wasmCloud side that prevents us from opting for those features?
Bailey Hayes 39:23
It's actually funny that you led us into this, because I had it on the agenda to talk through the differences here and what the rollout is going to look like. I want to highlight that for WASI HTTP we made a patch update to define that the te header I was talking about is allowed. So WASI HTTP P2 is virtualizable for HTTP/2 now — it matters on what your server implementation does, and what we're highlighting is that our server implementation doesn't do it yet. But that's configuration, that's compiling things in — it's easy, it's not standards work, so we can get it done quickly. Of course, my preference is always, where we can, let's upstream it all the way to Wasmtime so we all have a shared, awesome implementation. Essentially your question is, when is that server part going to land? We don't know quite yet — we've got to investigate a little more about what to flip on to make sure HTTP/2 works, like what Aditya and I were chatting about in the chat. But once we have that, I think it'll be very quick.
However, let's talk about Wasmtime P3 and what that means. Good news in the community: Mozilla, at the W3C in-person meeting, showed off their experimentation using the WebAssembly component model for Firefox, and they got really excited about it. They gave this awesome presentation where they did a deep dive on why it really matters to them and that they want to start working on it. My favorite part — Ryan Hunt, who's a lead engineer for the Firefox WebAssembly team, pulled up Hacker News and said, "they're always giving us a hard time, we did this awesome thing with WebAssembly 3.0," and the first thing was, "where's my DOM at?" This is basically going to be their answer for that. Now, Lucas spent a good bit of time deep-diving on what they would exactly need, and we learned of a scoping case that's going to be really important for the browser implementation — it wasn't as important for our implementation and didn't come up when we were implementing P3. This is a lot of preface for: we found a design change we had to make during implementation. We've begun rolling out that change. But what that means is that P3 components produced off of main today are incompatible with both Wasmtime 38 (the current main) and Wasmtime 39 (which is going to be out soon — it won't be in that one either, because we cut that release two weeks before and continuously fuzz it until the release is out, so we don't add extra code unless we absolutely have to). So Wasmtime 40, I think, is going to be the one we're aiming to align around on P3 across the whole ecosystem. I do want to highlight that Roman just did the major upgrade to Wasmtime 38 for both wasmCloud v1 and v2, and we've merged both of those changes as of yesterday. I'm aiming to get a patch out for wasmCloud v1 this week, and then the next release candidate, and both will be on Wasmtime 38 — just in time for next week to update to Wasmtime 39.
ossfellow 43:37
When is 40 expected to be out?
Bailey Hayes 43:47
We release a new version of Wasmtime every month. So 39 is basically November's, 40 is December's.
ossfellow 43:58
Okay, so in December we should be able to start writing P3 components.
Bailey Hayes 44:05
You could — if you're game to build off of main, you can start today, but it's building off main in a lot of places. You can see the release process for Wasmtime; it's very regular, on the same days every time, and then whenever we get a CVE we put a patch out. That's part of the reason we're driving so hard on getting Wasmtime 38 out — so we can have our CVEs patched. December's release is usually around the 24th, although we'll see if we do something different depending on the holidays.
ossfellow 45:11
But from a wasmCloud perspective — building off the main of Wasmtime — is there anything in wasmCloud, let's say v2, that prevents me? I want to start porting some of my stuff to v2. I understand the architecture at a high level, and I think now if I do plugins or regular components, they're still components. That means I want to use async, then I need to know wasmCloud allows me to leverage async. That's where my question is coming from.
Bailey Hayes 46:07
Yeah — you can get started with wasmCloud v2 today and just use WASI P2 components. We'll have a really easy way to upgrade from WASI P2 components to turn them into P3 components, similar to the adapter technique we did for P1 to P2, so you don't necessarily have to rebuild from source to take advantage of that. But you're going to want to, because the main difference between P2 and P3 — "async" is actually not the right word, even though we've been saying it, but it's a good generalization. The main difference is that now we have the primitives we can bind to in our language bindings. So in your guest code, you can much more ergonomically and easily write async code. It's not that async wasn't supported — actually we had async via a callback technique built into wasi:io, so P2 does support async, and that's part of why things like HTTP/2 do work on WASI HTTP today.
ossfellow 47:10
I have done that, and I've used polling and so on, but that's still doing some blocking stuff in order to wait for the response. That's why I'm looking for the ergonomic way of operation.
Bailey Hayes 47:29
Yeah, so we're going to depend on Wasmtime. I'm expecting Wasmtime 40 to come out at the end of December, and then we're going to immediately turn around and build that into our wasmCloud wash build. At that point we'd need to turn on a flag to make it available. I think I'd still put it behind a flag, so you'd flip it on — it wouldn't necessarily be on by default until we hold the vote that says this is the next standard. Because, still, just because Wasmtime implemented it doesn't mean we've passed it through, or that there aren't any more incoming changes. I don't expect there to be — and they'll get a message from me if I see anybody trying to propose more changes. But let's just say our goal together is probably end of January for us to have a full release. I don't want to promise any sooner.
ossfellow 48:36
Do you have the stories for that? We can contribute, because we need to follow your design lead — you design things, and then we can help with the implementations.
Bailey Hayes 48:52
The good news is that as far as our wasmCloud implementation is concerned, we're not concerned whether it's P3 or P2 — that's totally transparent to us. We just run those workloads on whatever we've configured Wasmtime to be able to run. So all the stories — I definitely have folks working on it. Victor, for example, is working on the second reference implementation; he's been giving us regular updates every week here, and has made really good progress this week, discovering one of the key differences. That's one of the areas we need to have done to advance it as a standard: the second reference implementation, taking these interfaces and making them work in a Node.js environment. He's been making awesome progress. So once we have all those test cases completed and he swallows this next design change — sorry, Victor — we should be there. All those stories are tagged out in the WebAssembly component model repo, the subsequent WASI repos, inside Wasmtime, and also JCO — so lots of places, but they're all moving. Nothing's blocked. That was a lot — any more questions on those two combined? We're getting a patch update, moving onto Wasmtime 38, we'll move onto Wasmtime 39 within a month, and Wasmtime 40 within two months.
Lucas Fontes 50:40
Yeah, I think the feedback we're hearing here is a bit more on the path to v2 — what are the remaining tasks, what's left out? We'll get on that. There's also a conversation about where this is going to live: wasmCloud versus the wash repository. We'll have some discussions on GitHub and go from there.
ossfellow 51:11
I have a question for Lucas. I've meant to ask in three meetings — I've been in situations where I couldn't speak. Lucas, what is the relationship between wasmCloud and Kubernetes?
Lucas Fontes 51:32
So I think we are using Kubernetes as the standard scheduler that we don't have to write. What I mean is, Kubernetes is really good at being a scheduler. When it comes to WebAssembly, the challenge is the cardinality of things you need — pods, IP addresses, and so on. So what we did is use the Kubernetes API simply as a scheduler, a place to store data. This doesn't mean wasmCloud only works on Kubernetes, and it also means we can run wasmCloud in way more places than before, in a few different ways. First, we run everywhere Kubernetes is available — AWS, AKS, GKE, all the cloud runtimes. Then we have the situation where you can run a k3s API server — just the API server — and point the wasmCloud operator and hosts to it, which means you can literally place a bunch of wasmCloud hosts in your edge network. They'll all be talking NATS, but you're managing everything from a central location using kubectl, and that's pretty nice. Then we have the other case, which is, "I don't like Kubernetes, I want to implement my own scheduler." That's why we have all the protobuf information now available, and also all the Go code that is inside the runtime operator. So you can literally get that and implement your scheduler on top of anything you want. You want to store your workload definition in Redis? No problem. Static files? No problem. We pretty much decoupled many layers of wasmCloud here — at the host you have plugins, at the runtime you have plugins for the scheduler. They all mean you need to write some glue code to get there, but this is also good, because then you're providing your own artifacts, keeping your own intellectual property. So, sorry for the mini sales pitch.
ossfellow 53:58
No, no. So, I'm a Kubernetes guy — that's my daily job. The reason I was asking is that this new relationship between wasmCloud and Kubernetes is not, at least from my point of view, fully articulated. Kubernetes is not being declared today as the primary platform, but for a lot of people in the community it's viewed as where you go when you have large-scale workloads. What's the situation when you're running wasmCloud at the edge — especially when you have a lot of edge — and you want to run it in such a distributed way? Does it mean you now need a lightweight Kubernetes cluster running at the edge, or can you have this dual mode where you use Kubernetes for larger-scale or main things, and then other solutions when Kubernetes is not a good fit?
Lucas Fontes 55:21
Kubernetes is not mandatory. It's really that we had to align on something, and Kubernetes is the incumbent. If you're in the Nomad camp or the Kubernetes camp, sometimes they don't like each other — but ultimately Kubernetes won the scheduler war, for better or worse, and here we are writing YAML. Addressing a bit of Yordis's question about what we mean by "scheduler": it's anything responsible for placing workloads on hosts. At that point you've collected all the information — which artifact you want to download — and you're like, "I want to send this to host one, and tell it to start this workload with this HTTP host configuration." It's really targeted, different from what wadm was doing, which is a bit more sending out a bid for hosts to say if they can fulfill it or not. It's also not to completely close the door for wadm being updated to have this v2 interface — but it's not very interesting, because the interesting parts of the wadm spec are related to wRPC providers, which are not in v2; and what's left is the component and link configuration, which is also not in v2. So there's very little overlap there, but we could make it work. I really expect the next wave of schedulers to be mini schedulers — like a Redis scheduler, something tied to other applications that already have a PaaS. Dokku, for example, could benefit from something like this. With this, we're going to cover wash dev for developers, wash host for your clusters, and we've been thinking about another one called wash serve for your build-pack environment — let's say Heroku. "I want to deploy components to Heroku, how do I do that?" Well, you use the wasmCloud build pack, and that won't need a Kubernetes cluster or anything to bring up that workload. But this is something we're going to look at right after we land the wasmCloud v2 bundle.
Bailey Hayes 58:29
Yeah, on that front — for the last thing you said, Lucas — I think you could just imagine a standalone use case, and that's where you'd put the wash serve command. The other thing I just brought up: we were having this really great conversation in Slack, so folks, if you want to chime in there, add more details, or help us make these docs and explanations real, you're super welcome. This is a sketch I put together really quickly this morning. Lucas, would you roughly say this maps? I realize I need to include the wash runtime to describe how this piece works — I didn't add that there. People think there's a scheduler, and there kind of is, but I would honestly call this the reconciler instead. All it's doing is saying, "this is the state I'm supposed to be in. Yo host, do this."
Lucas Fontes 59:36
Yeah, that's correct.
Yordis Prieto 59:38
Reconciliation is more how I see it, Bailey — a scheduler is like, "get this thing to be that thing."
Bailey Hayes 59:44
Yep. So it's a vast simplification compared to what we had at v1, for the better.
Frank Schaffa 59:57
By the way, isn't the HTTP module now part of Wasmtime, embedded now?
Bailey Hayes 1:00:08
Yeah, so I obviously stole an old diagram — I need to update it. I think there's what, it's like a cake. Wasmtime, where you've got this cool spot with the store and the Wasmtime instance — that's the thing that actually provides the sandbox for the WebAssembly runtime bits. But then there's this other side that's just straight-up native code, and it's kind of hard to describe that layer of the cake. If you think of the WebAssembly component sitting at the very top of the cake — maybe you've got little figurines getting married or something — and then all the way down there are many more layers for the types of implementations you can implement, with the bottom layer being us wrapping the whole thing. That's probably too abstract; I need to stop. We've got more, better diagrams incoming. All to say: the HTTP server implementation, where that's actually wired up, is at a totally different layer than what people would canonically think of as the WebAssembly sandbox layer.
Bailey Hayes 1:01:35
Well, we're out of time, but this was a really great discussion and conversation today. I've got a cool demo I'm going to save for next week, but it involves C++, which is very exciting, so stay tuned for that. It made me want to cry, but it was also really fun, if you can believe it. Okay — thanks, everybody. Have a good rest of your week. Bye bye.