Transcript: wasmCloud v2 on Kubernetes — Runtime Operator, wash host & WASI P3
wasmCloud Weekly Community Call — Wed, Nov 5, 2025 · 61 minutes
Transcript
Bailey Hayes 04:06
Recording in progress. Okay, great. All right, I'm going to hit record now. Here we go, live on the wasmCloud community stream.
Thank you for coming to wasmCloud Wednesday. It's our first Wednesday of November, and we've got a pretty cool demo of the next version of wasmCloud that Lucas is going to show. I figured we'd have a discussion around that afterward, so I wanted to allot time for that, and then Victor is going to give us an update on his work on WASI P3, and I'm going to make a couple of shout-outs for CFPs and upcoming conferences. So let's get started with a very cool and fun demo. Lucas, you want to take us away?
Lucas Fontes 04:59
Awesome. Let me steal the share here. Can you see my browser? Right, that's the right window. So, what are we talking about today? We've been cooking on wasmCloud for quite a while, and we're approaching a point where we have all the pieces needed to show everything working in one go. What I'm going to show today is the setup.
So here I have the runtime operator repository, and the first thing I'm going to do is get myself a Kubernetes cluster. That's going to take a couple of seconds.
Lucas Fontes 06:22
Now that we have a Kubernetes cluster, we're going to install the runtime operator and the new wasmCloud host, which communicates with the operator using NATS. For that we'll do a make helm install. What's happening here: we're setting up the wasmcloud-system namespace with a few deployments. Those deployments contain NATS — the message bus we're using — the runtime operator, which is responsible for getting the CRDs and scheduling the individual workloads onto the host groups, and three host groups. One is called default, which doesn't expose HTTP; one called private-ingress, which is an HTTP-capable host that only answers internal requests; and a public-ingress, which is an HTTP-capable host intended to respond to external, public requests. We're seeing them all in error status because NATS has to be up for everything else to come up. If I run this again, it should all be running nicely.
Now we have everything installed and the system is running. The very first thing we do is see how many hosts we have. For that we run kubectl get host — the same way Kubernetes itself has kubectl get node. When we do get host, what we're actually getting are the hosts, and these are the individual pods hosting the wasmCloud host, letting us see which hosts are available so we can place workloads on them in a multi-tenant way.
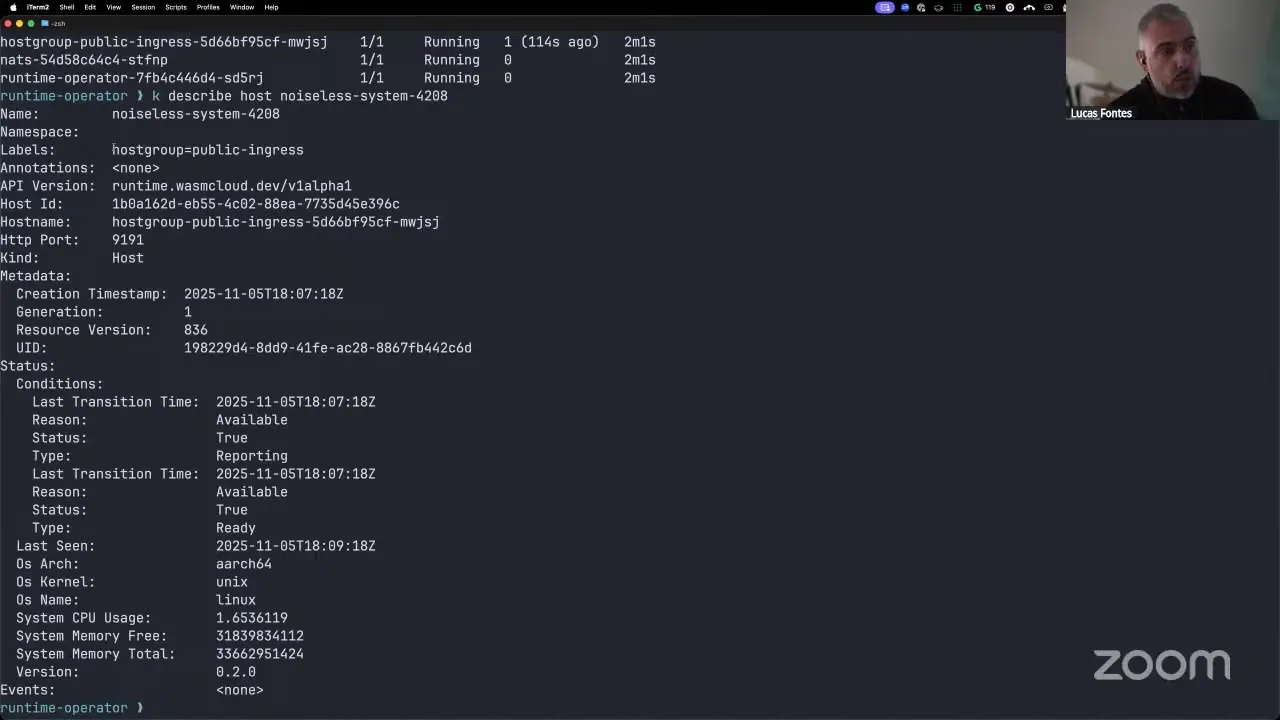
We have three host groups here. If I go into wasmcloud-system and get the pods, you see we have three pods. We can increase the number of pods in a deployment, which means that host group will have more capacity. So it works exactly the same way a node selector would in Kubernetes. Let's get one of those hosts to see a bit of their information. Here we have information about the host itself — the architecture, the CPU usage, the version. We also have the labels that this host should respond to when we're doing host selectors. So this lets me say, "I want to deploy a component, but only on this group of hosts."
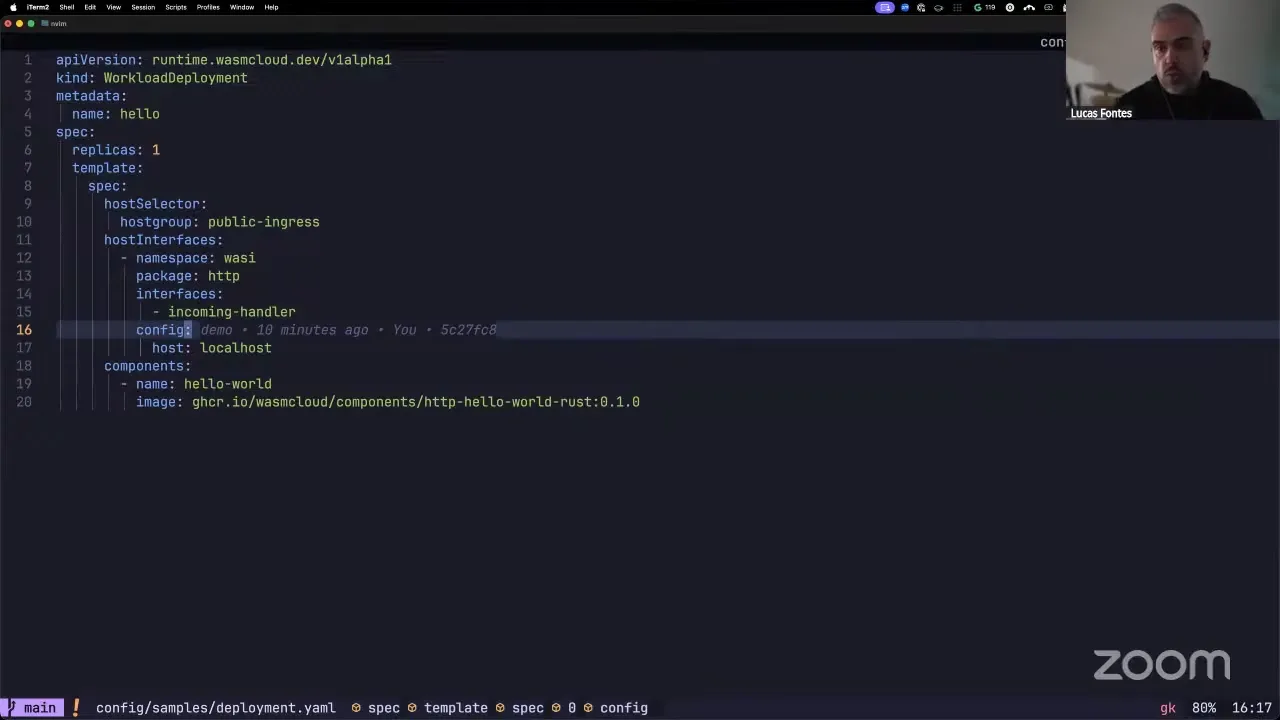
With all the hosts up, the next thing we're going to do is place some workloads. We have a sample deployment here, which is pretty basic but gives an idea of what we're talking about. This is going to be a workload deployment under runtime.wasmcloud, and we just want one replica of this workload deployed. We want to deploy it to the public-ingress host group, and here we declare which interfaces from the host we want to make available to this workload. By default, none of the host capabilities are exposed to a component — you have to tell the sandbox, "I'm allowing this component to have access to this interface." We have an HTTP component, so we need access to wasi:http/incoming-handler, and we also have a field for configuration where we can pass any configuration the interface on the host side might need to tie this workload to an external resource. In this example, we want the HTTP host — localhost — to be mapped to the component we have here.
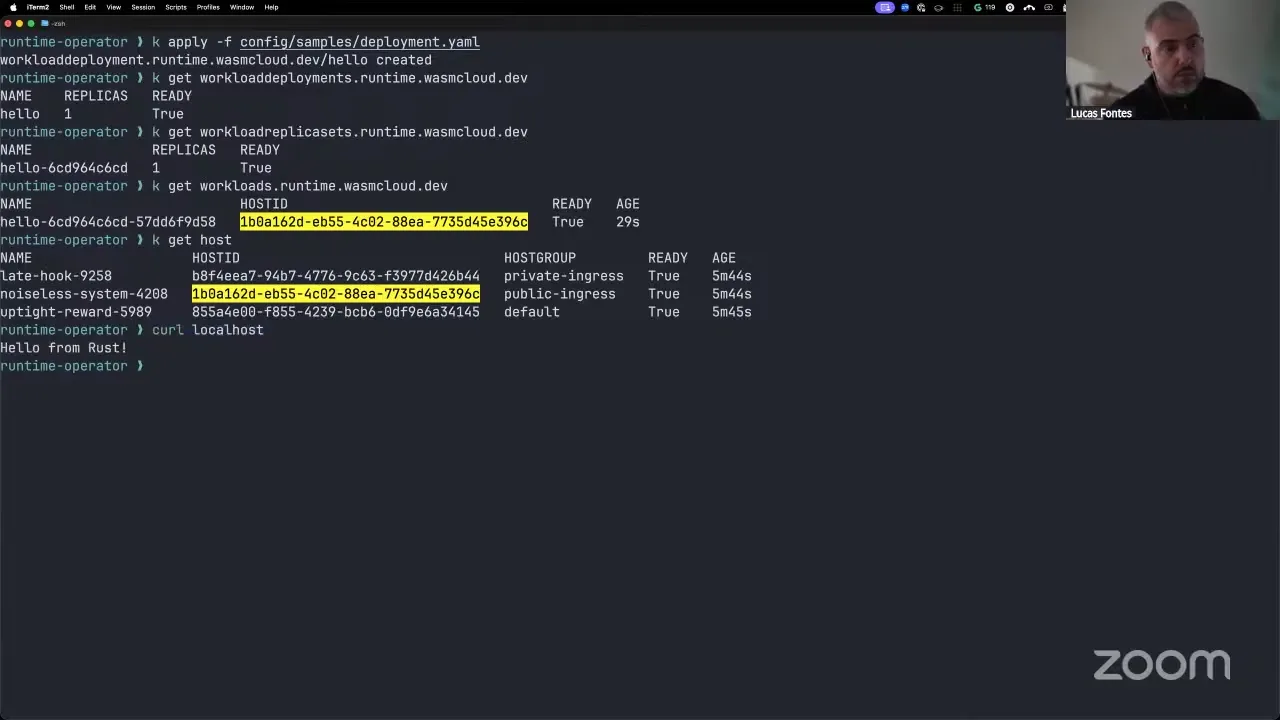
The important part: on this side we have the WebAssembly component, and these host interfaces are on the host itself, meaning it's Rust code. So when we pass all this interface definition and configuration, what we're saying is, "start this host plugin with this configuration," and that's going to be individual to this workload, so it's isolated from other workloads. Notice that we are not specifying a wRPC provider, an external provider, links, or any of that — this is the entire setup. So let's apply it. Now we're creating the workload deployment, and it's already up. What this creates is a workload deployment — we talked a few community calls back about the concept of a workload deployment, a workload replica set, and a workload itself.
Lucas Fontes 12:44
I'm going to do a get host here, just to show: we asked it to be placed on the host group public-ingress, and that's where it landed. Now we should be able to curl localhost, and we're reaching a component. So that's pretty much how I set it up locally when I'm testing and getting it ready for deployment. The important thing is this has been installed using Helm — the Helm chart is available in the runtime operator repository. We have not published this yet.
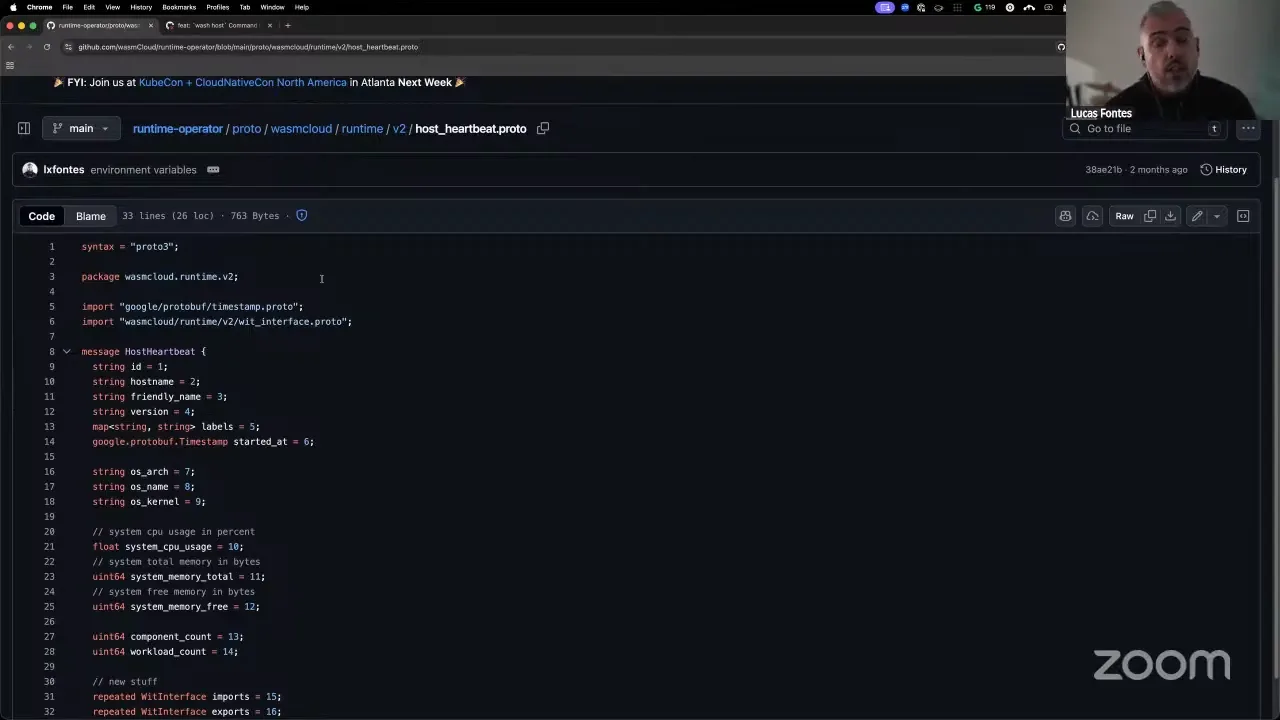
Lucas Fontes 13:42
What we're running here is essentially wash, and we're running wash off this pull request in the wash repo, where we're bringing a command to wash called wash host. The same way you have wash dev, wash build, and so on, now we have wash host, which makes that binary act as a cluster host. We pushed it to a temporary image just so we can have this demo, but I can run it here to show what I'm talking about. This is the wash Docker image, and you can see the usual wash commands — build, config, and so on — but we also have this new one, host. We can do host help. This is the one that literally brings up the wasmCloud host.
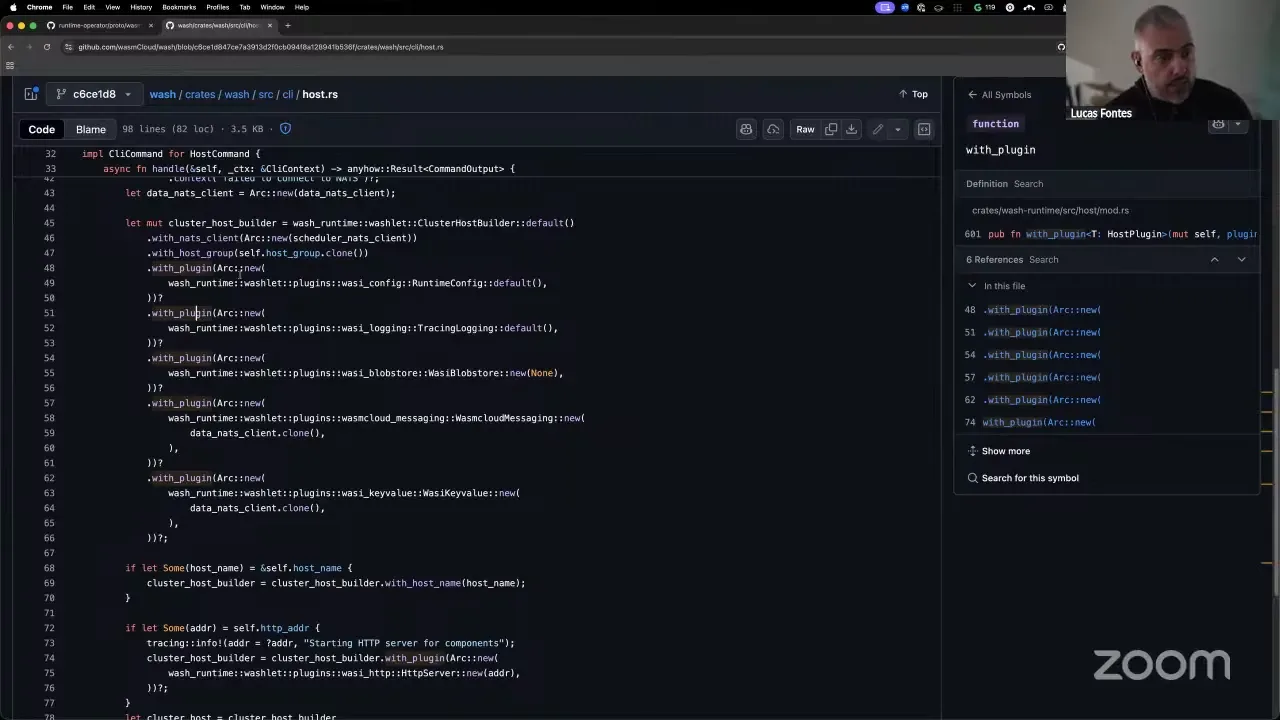
Now, wash host and the settings to kick off a new host are pretty minimal, because all the intelligence for scheduling has been moved over to the operator. There's no expectation that the host would act on its own without a scheduler. The other thing going on here is that we made it so you can bring your own scheduler. If you get to the point where you don't want to be tied to Kubernetes, you would implement your own scheduler, and we're providing facilities to do that.
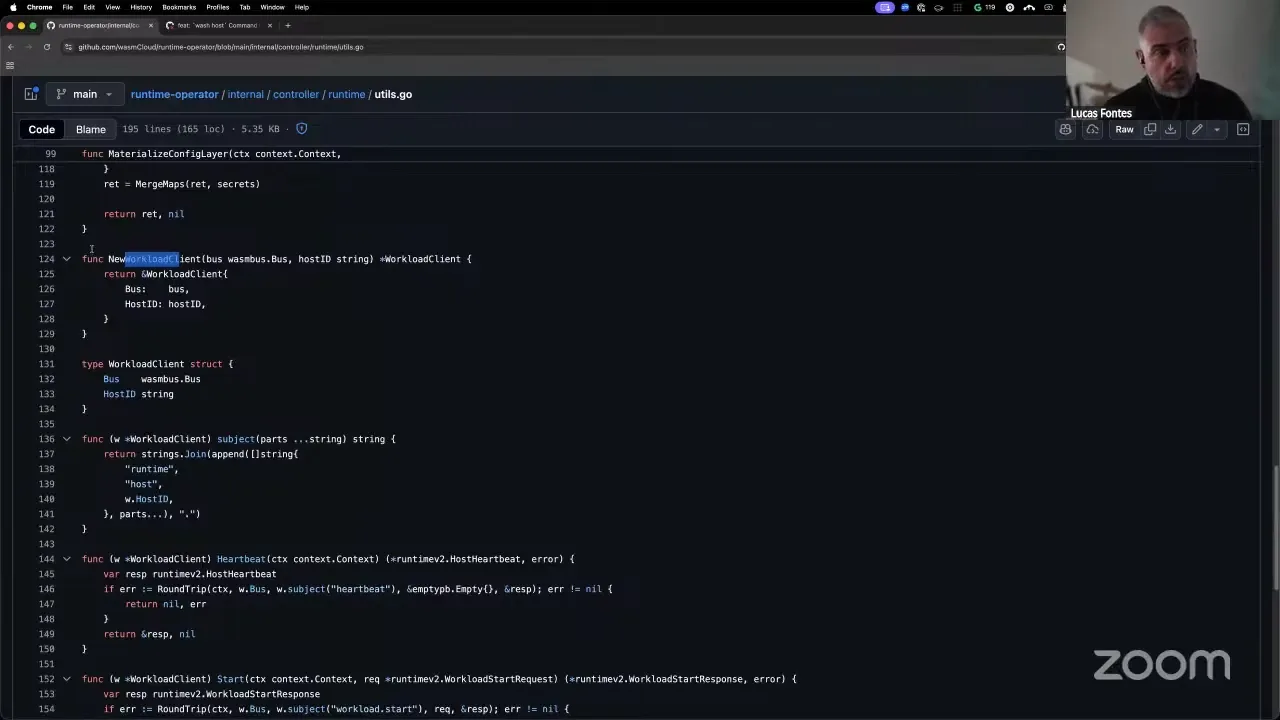
All communication from the operator to the host for scheduling is encoded into a single Go structure here. So if you were to implement this for any other scheduler, this is the code you'd want to steal. What this code does is get the protobuf messages that we have — for example, the host heartbeat. We have the message definition in protobuf, and we encode the messages in JSON format and send them over NATS. So we have ready-to-go clients for Go, Rust, Python, and other languages. If you want to write a scheduler for wasmCloud in any language, grab these protobufs from the runtime operator and build your own.
Now, there's also the angle of: I don't want to build a different scheduler, I want to build a different host altogether — I don't want to use NATS, I want to use something different. We're looking at that angle too. Inside this pull request, we have a really easy-to-use Rust builder pattern. The runtime is coming from a few built-in plugins that we enable by default. We're still not sure if they'll all always be enabled or if this will be on a switch, but you can add your own WIT interfaces as plugins here. In the example we're about to ship for wash host, we have config, logging, blobstore, and also wasmCloud messaging — wasmCloud messaging being the one that's not part of the WASI family, but we include it because it's wasmCloud. All these plugins have a sibling for the development story. So wash blobstore in local development uses a temporary directory; in the host implementation it's backed by NATS. So everything that's ephemeral in local development has a NATS-backed counterpart for production.
We're wrapping up this pull request with a few other things to clean up. Many of these already exist in some capacity, but we're making sure we clean up to a point where we can call this a release candidate. Once that's done, we pretty much have wasmCloud v2 ready for the process. All right, I talked a lot. We'll stop here and see if there are any questions. I see a hand up — Victor, go ahead.
Victor Adossi 19:51
I just wanted to point at the question in chat.
Lucas Fontes 20:02
Oh — "Will we have autoscaling for hosts?" Great question. Autoscaling is kind of orthogonal. When we think about scaling, autoscaling happens at this layer. To get autoscaling going here might mean two things: autoscale my hosts — as in, my host is running at 80% CPU, therefore I need more hosts — or, I have more components, therefore I need more hosts. For the first case, autoscaling the number of hosts you have, you'd create a Horizontal Pod Autoscaler and point it at one of these deployment targets. The Helm chart doesn't set up an HPA for you automatically, but that's something we can add — not opposed to it at all. We just haven't seen the need yet, because you can layer it on top of the configuration. Autoscaling for the components themselves is something we haven't looked into at this point.
On the host name, somebody is wondering how and why namespaces work. The namespace in this section is the WIT namespace — these are the WIT interfaces we want to get from the host. This one is wasi:http. If we were using wasmCloud messaging, this would be wasmcloud:messaging — producer, something like that. So the namespace here has to do with which WIT namespace you want to import from. Now, where namespace also shows up is here, but this is part of Kubernetes itself, so you can create this workload in pretty much any namespace you want.
Frank Schaffa 22:43
Yeah, that was a confusing part. Coming from the Kubernetes side, namespace is your logical breakup. And now within the host interface there's a namespace there, so I was wondering about that.
Lucas Fontes 22:59
That's great feedback. The host interfaces here is almost like we should be calling it "WIT interfaces from the host," but we have "host interfaces" in there. That's one of the things that's fairly easy for us to adapt and change. What else do we have? This is the most basic setup if you want to do a Hello World. What we're looking into now is having a few samples — for blobby, for other interfaces, for wasmCloud messaging — and showing a bit of the different patterns for composing applications using WebAssembly.
You'll notice that when we talk about host groups, we have three different host groups, and there's a reason: separation of concerns. One is responsible for ingress — if you're writing a CDN-ish use case, that's the kind of ingress you want. There's private ingress, which is if you're working on internal-only HTTP servers. And the default host group is for when you want to create a bunch of WebAssembly components for background jobs — they don't need to receive HTTP, but they need to subscribe to message buses or send HTTP requests out. With these three host groups in the development setup, you can compose all those different deployment patterns. Any other questions? Otherwise I'll get back to Bailey.
Flynn 25:01
Can you control the names — host group private-ingress and host group public-ingress — or can you spin up other hosts? How much control do you have over this stuff?
Lucas Fontes 25:14
Notice how we started by doing make kind setup and then make helm install. The make helm install is installing this values.local. The setup I did here is the exact same Helm chart that can be used to deploy on a remote Kubernetes cluster — deployed locally using a values.yaml that maps my local setup. For the runtime we don't have the wasmCloud image out yet, so I pointed the runtime image to the temporary one; in real deployments you wouldn't have to do this. Then we have the list of host groups you want to create. Here I specify that I want a public-ingress host group with one replica, this type of service, exposing HTTP as a node port, and limiting CPU and memory for that sandbox. I declared all the host groups I want, which is why we have three. If you don't specify any, the default is a single host group called default with HTTP enabled — the get-you-out-the-door environment. But you should customize the host group list.
Bailey Hayes 26:56
Lucas, do you mind doing a describe on a host, just to show that the runtime operator is looking for basically an annotation to know that this is a host? I want to emphasize that this is for end users. It's kind of like the Linkerd inject thing, right? You tell us we can schedule to you, and you decide how this looks.
Flynn 27:29
And — I'm not entirely sure how to phrase this — in what way is ingress from outside the cluster being affected here? I assume you have a proxy running somewhere, and a load balancer service. What controls that?
Lucas Fontes 27:59
So, for every host group we create in the Helm chart, we create an associated service. The service can be ClusterIP, NodePort, LoadBalancer, or headless. In a production environment, this one would be a LoadBalancer, for example. But for local we're doing NodePort and mapping port 80 to this crazy port number, which in our kind config maps any traffic for this port to the development host on port 80 — and that's why the curl works. So this is the "I want to see wasmCloud running on my local computer as easily as possible" path. If we were to install this on a remote cluster, the values YAML would be significantly different.
Flynn 29:20
Well, I have to run to a different meeting, but this looks cool. Thank you — looking forward to playing with it some more.
Bailey Hayes 29:32
Thank you, Flynn, see ya. For folks who don't know, WasmCon NA in Atlanta is on Monday, and Flynn and I are giving a talk where we're going to run exactly what Lucas just showed, but meshed with Linkerd. I'll have a setup intending to show maybe a load balancer and more of the ingress side. But it all just kind of works — that's the TL;DR — because we're building into all the things that are already there in Kubernetes. So it's a pretty nice, native integration.
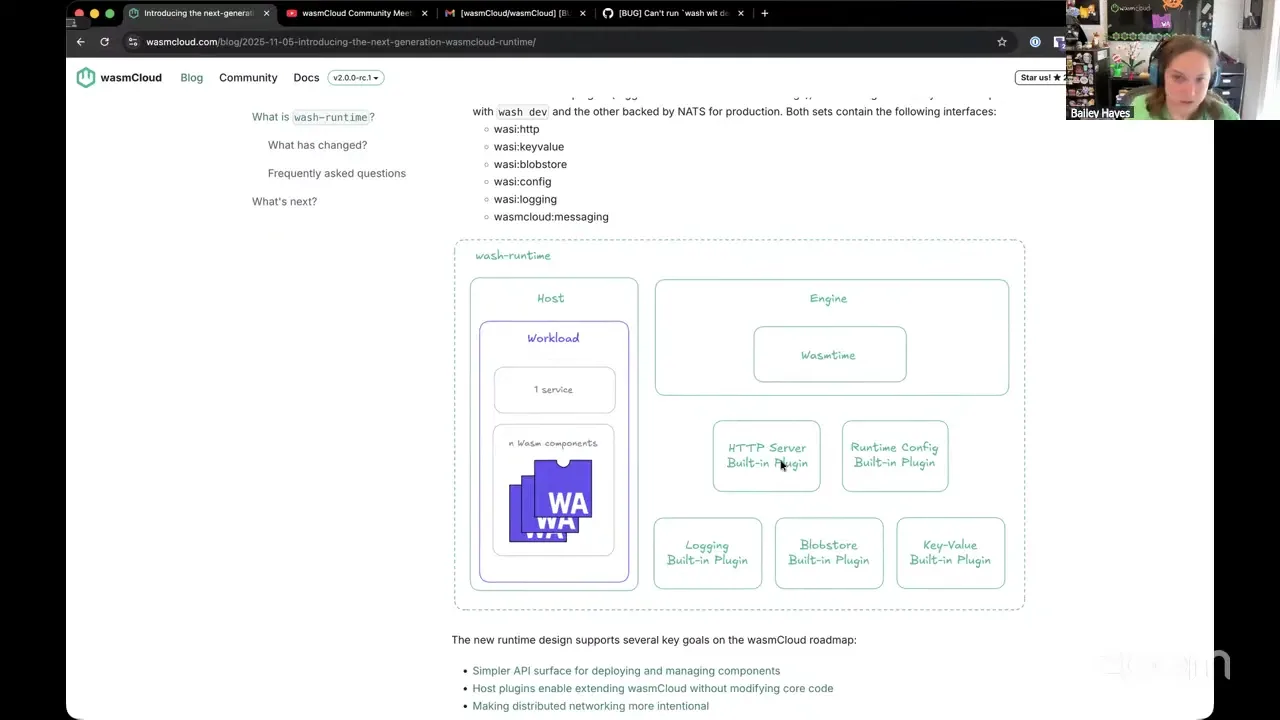
I dropped a link to the docs we've already landed. The main callout that Eric's been working on is we've now changed the label from "next" to "v2.0.0-rc1." So this is where we're ready for release-candidate feedback. What Lucas just showed: we've got the wash runtime crate buttoned up, embedded in the wash dev command and in wash host — it's all in that same wash binary now, so it's one binary. And he showed it being operated by the runtime operator, which is now in the wasmCloud repo. We're about to cut that tag, so technically it doesn't exist yet, but maybe later today you'll see it. Instead of using our test GHCR reference, you'll be able to find all these things in GHCR. In parallel, we're working on getting the documentation together and more examples and demos together so folks can grab hold of this and try it out.
ossfellow 31:25
Bailey, thanks for the presentation. I have a question more related to version two. It partially goes back to the exchange we had about building HTTP into an HTTP provider as a transport, versus separating transport into a separate plugin — so you can replace it between a web version, a NATS version, and so on. Basically you'd have your wRPC transport as a separate plugin. That's one part. The other part is about service-type host plugins, the ones that are succeeding the providers today. Is it reasonable to assume that such services should have two implementations, one for local communications and one for wRPC or remote communications?
Bailey Hayes 32:48
Let's start with the first part of your question. Essentially: how are these components even doing their networking — what's their transport? We published a blog today that Brooks and Eric have been working on for a while, and it details the architecture for all these different things. So hopefully this is very helpful, and it links to our initial features and design discussion around how and why we're making these changes. They basically all have an implementation now.
Back to your question. I've got a component deployed here, and you saw in the workload deployment spec that it depends on wasi:http. In theory, what provides that wasi:http interface is virtualizable — it's whatever this plugin decides to do to implement it. What we provide by default is just regular old HTTP, no special tricks, which means there's no extra networking hop. What we had before with capability providers — these host plugins are more what's replacing a capability provider. If you wanted this to be over wRPC, that's an option you could implement. But what you could also do is have an interface that is literally wrpc: namespace, whatever you're trying to do, if you want to do something specifically over an RPC-style transport. Be transparent about it in your component, so you're not slipping into the fallacies of thinking you're doing a non-networking call and then suddenly doing a networking call. Be very explicit about the type of networking you're doing — that way you can expose those errors. In that scenario, you'd have a plugin that's a wRPC-specific plugin providing that interface.
Now, the second part of the first part — how does the service work? We've included an example of a cron trigger. When you think of a service, it's probably easiest today to think about things you'd use as types of triggers; cron's a good one. Lucas, did I get everything there? Anything you'd add?
Lucas Fontes 35:41
Yeah, the service is what we need to explain a bit better going forward. The challenge with WebAssembly is that everything is invocation-based — there's no concept of global values or things that survive across multiple requests. What we're doing here with the service is giving this workload a place where it can run long-running code. You can create an infinite loop inside the service, and it acts like a regular Unix process for all intents and purposes. You can open sockets inside the service, both inbound and outbound, and you can communicate with other components inside the same workload. So this gives you the ability to create a very simple service doing while true: call my sibling component — and there you go, you have a cron trigger of sorts. This plays a lot with the identity and network addressing of each individual workload, which is something we're also validating as part of this pull request. We'll have the ability to pinpoint every single workload inside the host by giving it a unique hostname, a unique IP address — a unique network identity in general.
Frank Schaffa 37:25
So Lucas, for this service you're creating, what's your idea in terms of doing a health check?
Lucas Fontes 37:36
Great question. The service is optional in a workload. When a service is present, it becomes the supervisor for all the components in that workload. That means if the service is down, we consider the whole workload to be down. The service comes with a few settings for restarts — restart a max of three times, or never restart it. So the service is essentially the health check of that individual workload. In terms of what's being health-checked, the runtime checks if the WebAssembly sandbox is still active. Inside, you can be doing HTTP checks or checking file system things — it's really not important. Think of it as a Unix process: if the process is running, everything's good; if it crashes, we replace it and put it on a different host.
Frank Schaffa 38:46
Is this already documented somewhere? Because it makes sense.
Lucas Fontes 38:53
I think it's coming as part of this documentation drop. Just to quickly touch on this — it seems like some weird stuff is going on here. What we're trying to enable: the challenge with components, because they're invocation-based, is how do you do connection pooling? How do you do long-lived resources? By having this concept of a service on a per-workload basis, we now have a place we can run PgBouncer, for example, where each workload has its own individual PgBouncer. They have 1,000 components of concurrency, so you're funneling 1,000 TCP connections into a single PgBouncer connection out to your database. So we're going to use it as an aggregator point for the workload.
Bailey Hayes 40:28
Massoud, you had what felt like maybe a second set of questions. Do you mind reminding me? First, did we answer your initial question?
ossfellow 40:43
I do need to write one of these plugins myself, and once I write it I think I'm going to get the hang of it. I have all the pieces, but I haven't been able to cognitively connect all the dots — and for me that requires going through the exercise of writing one.
Lucas Fontes 41:09
I agree. If this helps: if you've ever implemented a WASI interface on top of Wasmtime using the component macro, it's exactly the same thing. You have one extra trait to implement, the host plugin trait, which tells the host "I want to be a plugin, and these are all the interfaces I want you to send my way." It's very minimal. Take a look at the wasi:http one I shared, or maybe start with the config one, which is the tiniest. If you've seen Wasmtime code, this is going to be no news to you.
Bailey Hayes 41:59
Yeah, just 122 lines for that one. And you see you get basically direct access to some of the Wasmtime interfaces.
ossfellow 42:08
Okay, I have worked with Wasmtime before. So basically the services are now given more authority in terms of managing some of the relationship with the runtime?
Bailey Hayes 42:29
And it's important to highlight, this is native code.
Lucas Fontes 42:34
Yeah. Massoud understands the current wasmCloud runtime, and that's exactly the callout: we don't have an abstraction in front of Wasmtime anymore. By writing plugins, you can go straight to Wasmtime.
Bailey Hayes 42:54
And actually, Mindy is going to be dropping in wasi:webgpu pretty soon, and that'll be another example of how somebody can slot in something they were working on as a Wasmtime extension straight into this via our plugin interface. Massoud, your feedback made me think it would be really wonderful — one of our next documentation tasks — to create a tutorial on how to add your own host plugin and build your own wash host. That would be a really great v2 doc to get together.
ossfellow 43:32
That would be awesome. The second question was about these host plugins that will act as providers. One of the goals, as I understood it, in version two was to differentiate between in-process versus out-of-process communications. So my question is: when it comes to such plugins, do those two still apply — saying that a provider communicates with components, or provides services to components, that are on the same host versus on a different host, so we have a local transport versus a remote transport over wRPC? Should these providers each have both implementations?
Lucas Fontes 44:44
At the moment, everything lives inside the host — all the calls are local. So if we were to bring wRPC into the mix, it could happen a few different ways. It could be a workload service that does the wRPC communication out, using TCP, NATS, whatever, because now services have TCP/IP capabilities. It could also be a host plugin, but if you make it a host plugin you also need to address permissions — who can call whom inside the workload mesh. That part we haven't gotten into. How we're seeing communication between one component and another is using wasmCloud messaging. wasmCloud messaging is part of the host now, and you don't need any setup at all — you don't need to tell it which NATS host or any of that. You add the interface, you say which topic you want to listen to, and you can send JSON messages back and forth across components, which gets you that RPC feeling.
Bailey Hayes 46:10
That reminds me — one of the things here is making this distributed networking more intentional. The solution is essentially making networking internal to components as part of the workload. You can think of the workload itself as a form of tenancy — that is the tenant, this is its box. What I'm so excited about is that when you look at a workload, what you should really think about is that this is basically an entire composed component itself. It's its own world in WIT terms. In the future, when we have features in the component model like runtime instantiation, we could do really cool things — like a service that acts as an HTTP router, where each component serves on a specific route, and it would only need to instantiate the routes actually being called, not the other components. That's the type of flexibility this design enables.
Frank Schaffa 47:20
From the point of view of multi-cluster — since this is a Kubernetes construction — I'm wondering, have you started thinking about running this in multi-cluster? Is that something I can commonly handle, or do I have to be aware of the different clusters?
Lucas Fontes 47:50
Yeah, we're following what Kubernetes is doing — that's the gist. If you have a cluster that's multi-regional, then your setup is now multi-regional. But if you have a cluster that's just three nodes in a bedroom closet, that's cool as well. We're not trying to solve for the multi-cluster question here. The management is really within the Kubernetes boundary. You can add a layer on top of this — for example, deploy a virtual API server and deploy all these nodes as Docker images in different cloud providers, and it would work — but for all intents and purposes you're still interfacing with the Kubernetes API server to manage this fleet. I think we did a demo of this.
Bailey Hayes 48:58
Yeah, it's a few months back at this point, but we did that early on to validate this design. Any other questions, folks? So yeah, please check out this blog. As we cut the release candidate, we'll post in Slack and say, "yo, it's time, come try this out," and we'll give you the steps to get started. I think that's our main call to action for the community — give it a shot and give us feedback. Right now a lot of that activity is inside the wasmCloud wash repo we were showing here. It's such a major reimagining that we've kept it kind of separate from v1 so we can keep v1 stable and doing its thing. So this is effectively our home right now for v2. Anything more we should say on that front, Lucas, before I start making callouts to events?
Lucas Fontes 50:07
No, this is great. And thanks for all the questions and feedback. This is great. Thank you.
Bailey Hayes 50:14
Thank you, Lucas. Okay, so I have a special celebrity link for you today. If you didn't get your submission in for wasmCon EU for next year, use my special link — and by Friday, aka this week, maybe do it today while you're still thinking about it. Get a CFP in, maybe put in your talk about wasmCloud and how great it is. If you need help creating submissions or content, please reach out to me or Liam — we love to help our community share their story. So that's one. Wasm.io is also open for CFPs; that's open till December, but don't wait, get it done.
We'll be posting more about what we're doing at WasmCon next week. Expect the community call next week to be pretty light, because we're going to be on the floor. But we always like to say hi from the floor, so I'll sign in and show everybody around a bit of the KubeCon floor. We have a blog post — "wasmCloud at KubeCon NA 2025" — and we're right here in the project pavilion. If you want to see some of the Cosmonic folks, we're right here, so we can wave at each other between the two booths. If you go to the Cosmonic site, we have a similar version of this blog, and it's called out, so if you're looking for us, you can find us. We also have a ton of really exciting talks I cannot wait to see — and to also be over with, since some of those are my talks. Liam, I saw you come off camera — I feel like you've got something you want to say.
Liam Randall 52:30
We're going to get through this. As usual, Bailey, you're on top of everything, so it's great. I just want to make sure we called out — travel could be a little weird for folks next week, but Bailey and I are driving, so we will be there with bells on as usual. Our booth will be over at AI Day. If you want to see the sandbox MCP stuff, we'll have a little kiosk over there with wasmCloud and IDP Builder and a bunch of other stuff. That's Monday. We'll be at those two spots — Bailey will be running wasmCloud, I'll be over at AI Day. We kind of divided up representation for folks.
Frank Schaffa 53:19
Are the talks going to be streamed live, or just recorded?
Liam Randall 53:26
They should be streamed live. If you log into your Linux Foundation account, you can follow the live stream there. I'll drop a link in Slack right after the call. I think Elizabeth's talk about wadm is going to be incredible. Bailey's got her talk with Flynn — Flynn was on moments ago — that's going to be pretty awesome. And Eric has a poster session during the happy hour on Tuesday, so he's going to be quite busy. We've got a bunch of fun demos that'll be out on the floor too. And I think I'm also forgetting a talk.
Bailey Hayes 54:15
Mindy from Cosmonic and Colin from Adobe are going to be showing the Content Authenticity Trustmark Onyx model running in wasmCloud with wasi:webgpu.
Liam Randall 54:32
Which is brand new — I don't think anybody's ever seen it before, considering it just compiled for the first time last night at midnight. So that's exciting. On Tuesday we'll be divided between the floor — the wasmCloud kiosk is open in the mornings, if you look at the schedule — and then the Cosmonic crew will be over there, and we'll happily host all the wasmCloud things over there as well. That's Tuesday, Wednesday, and Thursday. So it should be a good time.
Bailey Hayes 55:08
Absolutely. We do have five minutes left, and I did promise a WASI P3 update. Victor, are you game to give a five-minute update?
Victor Adossi 55:23
Sure, I can give a super quick update. Right now I've been doing a bunch of work on the JCO side — the open-source, Bytecode Alliance-stewarded project for the JavaScript ecosystem. What I've been focusing on is adding async support. At this point, Preview 3 — the next iteration of the component model — brings in features to both the component model and, of course, what shows up in your WITs, your WebAssembly interface type definitions. It brings in stuff like futures, streams, and being able to call components and have components call each other asynchronously.
Right now the implementation is mostly done and looking really solid on the Rust side. So what I've been doing is making sure that jco transpile — a way to take a Rust component and convert it to run on a JavaScript runtime, any JavaScript runtime that supports core WebAssembly — works with this new async component model paradigm. It's a lot of making sure things work the same; we want this second host implementation to function similarly to the Rust implementation that already exists, and to be able to use the Rust components that get written. Rust has the best support, and probably will for a while, with regard to P3. So people are creating P3 components that do async things, and making sure we can run those with JavaScript as a host is what I'm working on.
A bunch of new tests and a bunch of bugs — thanks to Christoph from the WebAssembly community, who's been kicking the tires and filing bugs, we were able to get some fixes in. This shows up in releases. P3 support is still experimental, but we try to push out the pieces that are done as soon as they're done so people can try it. People have already been bringing their Rust components and trying to run them, and whenever we run into a bug we fix it and keep going. So right now we're in the testing-and-fixing phase of the JavaScript implementation.
Bailey Hayes 58:33
Thank you, Victor. What's so important is that this is our second reference implementation, which allows us to move the standard forward. Once we have the second reference implementation, we'll hold the vote in the WASI subgroup at the W3C — and the tests Victor is working on, we need a completed, working test suite. But once we have it, we've done P3, and that is super exciting. We're getting close. We're still on target for this year, end of year, and I'm hopeful we'll have it.
If, like Victor called out, you want to try out P3 today, you can definitely do it. And you might be wondering — we just showed you wasmCloud v2; does wasmCloud v2 have P3 in it right now? No. I'm expecting us to release wasmCloud v2 — as soon as we can stabilize, release, and get feedback, also before the end of the year — and not just the release candidate we're cutting today. Then we'd have a fast follow upgrading to the latest version of Wasmtime that's stable on top of P3, where those interfaces are still turning a little. Once that's stabilized, we'll bring in the latest Wasmtime, and you'll have it in v2.0 — maybe v2.1 or v2.2, but it'll be this year too. I think that's pretty exciting. Thank you for the update, Victor.
Victor Adossi 1:00:19
Yeah, no problem. In the meantime, changes to JCO itself still progress. If you've been watching, a bunch of fixes have landed. Thanks to members of the community who have been filing issues as they ran into stuff or asking about features — we found a lot of pieces of the JCO documentation that probably need work. That's another place we're always happy to get help.
Bailey Hayes 1:00:50
So, call to action, folks: help us harden JCO for P3. Well, that's it for the agenda, unless folks have questions for Victor. I think we're at time. Thank you, everybody. I hope you have a wonderful rest of your week, and I'll see you from the KubeCon floor next week. See you later. Bye.