Transcript: WebAssembly on Kubernetes: the New wasmCloud Runtime Operator & WASI P3
wasmCloud Weekly Community Call — Wed, Sep 24, 2025 · 90 minutes
Transcript
Bailey Hayes 06:01
All right. Hey folks, welcome to the September 24 community call. As you can tell, I am not Brooks. Brooks is on an amazing vacation — I hope he eats lots and lots of sushi and ramen where he's at. We've got a packed agenda today. I'm going to run through a couple of things we've been landing and things that are in progress, and then I think the bulk of the discussion will be around a Kubernetes-native operator that Lucas is going to walk through.
First thing first: we've been landing a ton of things for wash lately. If you're not aware, we've been working on the next version of wasmCloud, and a lot of that is landing in this repository — wasmcloud/wash. It's out of tree from wasmcloud/wasmcloud main, which makes it easier for us to keep main stable and iterate on top of it while we make breaking changes over here. This is starting to really shape up. This is a call to action for anybody interested in getting started with the next version, because we have a ton of issues worth running through — several of these are features we need before we can cut our next major version, and many are labeled good first issues with great detail. Some would be pretty fun for somebody who wants to get their hands dirty with wasm-tools, which is the crate that both Wasmtime and basically every language producer toolchain in the ecosystem uses. If you don't see an assignee and you want to do it, you can assign yourself, or add a comment saying "I'll take this one."
Bailey Hayes 09:30
This one I call out directly because I really need it. When you build with cargo-component, or with a handful of the other Bytecode Alliance tools for producing a .wasm artifact, we've come up with a convention that most tools are supposed to follow: in the custom metadata section, you expose things like what you'd normally see in OCI labels — the version of the artifact, what license it's under, where the source repository came from. When you put these annotations on an artifact, the benefit is that tools like GitHub Packages look at those labels and do a lot of nice integrations around them. So it makes it easy for downstream consumers to know what they're going to get.
Another low-hanging fruit, good for anyone wanting to get started even just using Rust: there's a flag we can pass in on clap — the crate we use to parse command inputs — that would let me do wash build --release. Obviously something we need before we cut our major version, and it should be pretty straightforward to add.
Going back to some of the others: "finding the intended WIT world." Brooks was trying out some Claude Code integrations and asked a bot to take a swing at it; it got a little lost in the weeds. So even though you see a PR, it's not the case that Brooks or I invested time — we wanted to see what a bot might do. The bot didn't quite land it, but maybe a human directing the bot could easily get it done. In the most common case for just about any WebAssembly component project, you want one single world that says exactly what it imports and exports, and when we build it we should be able to derive that. It matters more for Go than other languages because Go doesn't have a top-level SDK experience like TypeScript, where I can pass extra information in a package.json. There's go.mod, but I can't add my WIT world into it. Putting the smarts in wash gives us the ability to simplify the experience without a config file. The key design goal for wash is that it's a polyglot build tool you can use across any WebAssembly project, and it just does the right thing by default.
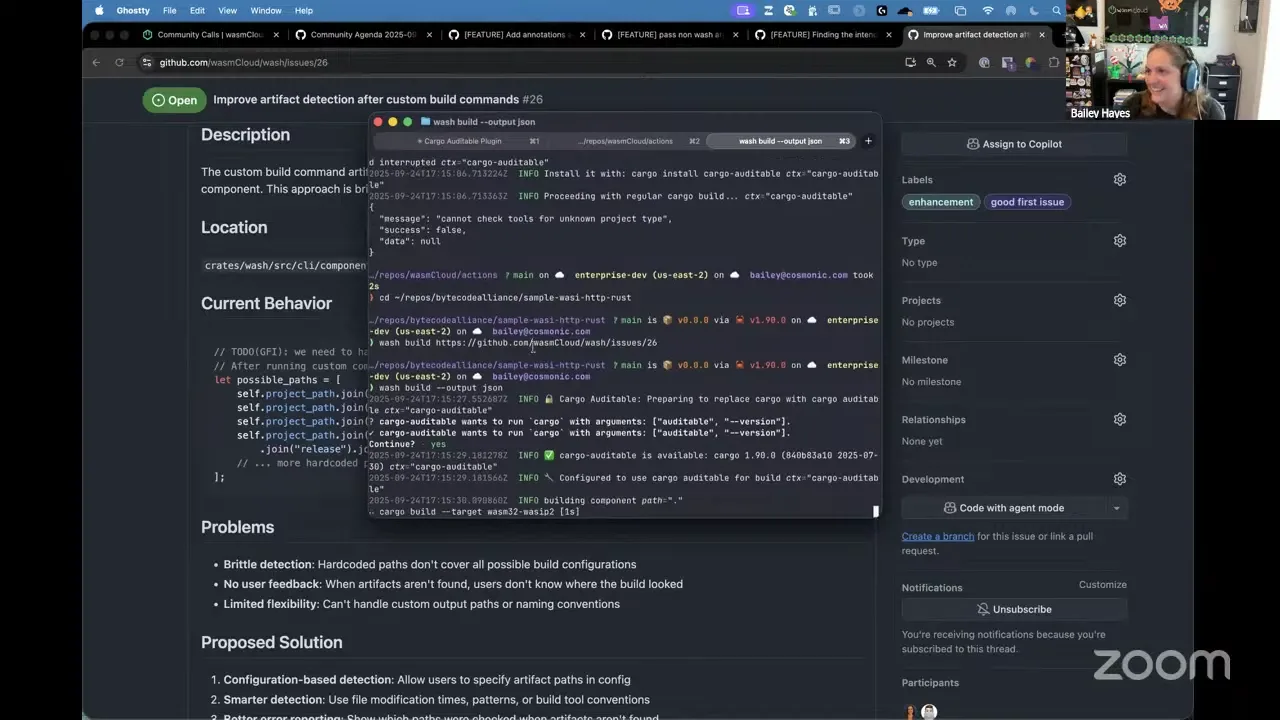
And last but certainly not least: outputting the artifact path when we build a component. Where this really shines is when you're writing build automation — a GitHub workflow where you want to take the output from build and immediately pass it to a publish action, which was exactly the use case I ran into. The previous version of wash just created a build folder and copied the Wasm into it, but that's not idiomatic to a language and it's a little intrusive. Our key design with this next version is not to be intrusive — not to require a wasmcloud.toml with all our specific info. All that information is already in your package.json, your Cargo.toml, ideally your go.mod. So wash build --output json lets you say "here's your input, here's your output, that's the artifact path." Let me go to the Bytecode Alliance sample — a random project that doesn't know anything about wasmCloud — and run wash build --output json with my own custom version. I can't believe that worked.
Bailey Hayes 15:29
Well, I just got surprised on the call — I added another plugin that might be interesting. I wanted to be able to add extra language features like cargo-auditable, so when I'm running in a Rust project and do a build, I always get an auditable artifact at the end. But the thing I want to call out is this little data blob. This is where we can attach a lot of interesting outputs for anybody trying to create GitHub workflows. By doing this, we can get workflows that are language-agnostic and reusable across many projects.
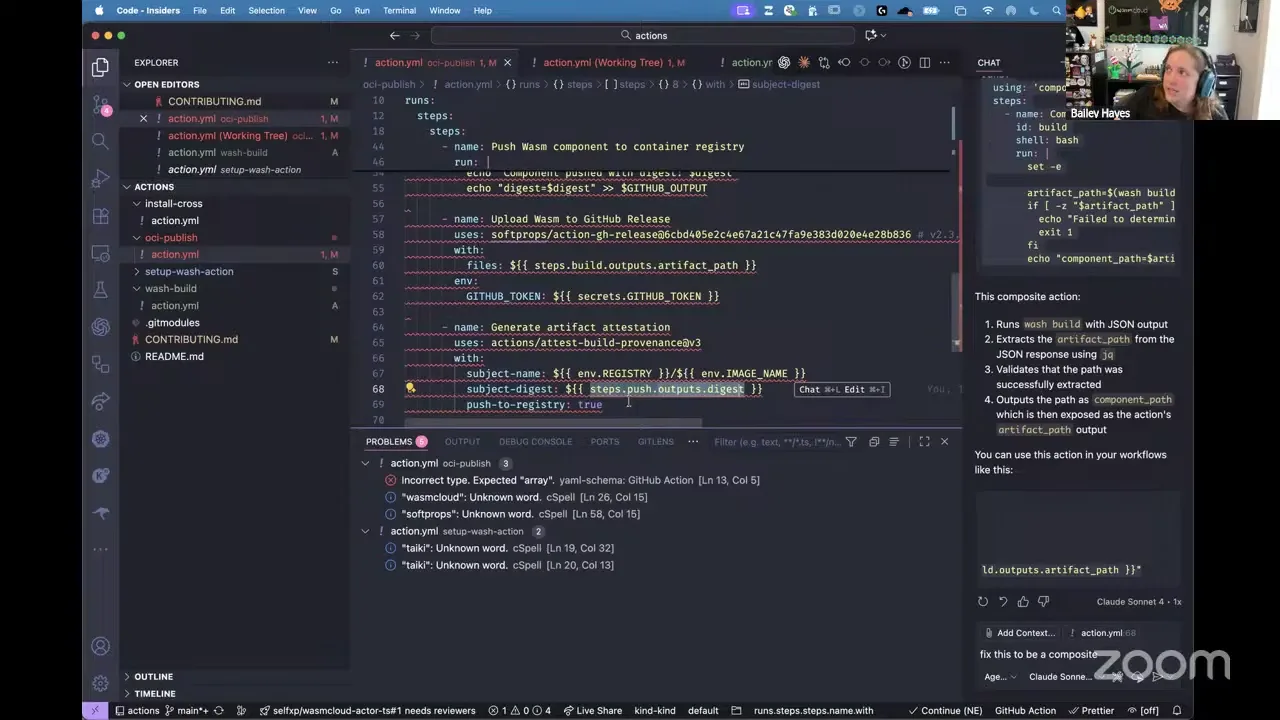
We've talked about wasmCloud building out a shared monorepo of common composite actions that we maintain, and submoduling in actions that need to be published to the marketplace. We already have an action published to the marketplace, and it's got a couple of new enhancements. The biggest one is that we now have the ability to pass in a plugin list to the setup-wash-action. I haven't technically merged and released that one yet, but let me pull up the PR.
Bailey Hayes 17:09
Here we've got a PR for being able to enumerate your plugins. I also made sure I added those to the cache, so if you keep rerunning this we aren't always re-downloading the same set of plugins. So now let me show you where and how we'd apply them. This takes that setup-wash-action and creates another composite action on top: this composite is just wash build. I run wash build, take that output, and parse the data blob to get the artifact path. Now I have a build output — a composite action I could drop into any WebAssembly project anywhere, and it just knows how to build and gives me the information I need for the next step. That next step might be running validation or security checks, or in my case, running that exact same composite and then doing another portable thing: taking the component, running wash oci push to push it to a registry, and then doing attestations on top of it. Notice all of these just build on taking the previous output from a GitHub workflow and applying it downstream — for example, taking the digest out of what we build. Making sure the digest is included in that data blob as part of wash oci push was one of the other fixes we landed this week.
So that was the whirlwind tour of updates on setup-wash-action and the wash project in general. I gave enough time for anybody joining late to now check out the prime-time part of this show, which is our new runtime operator. Lucas, would you like to tell us what that is and why people should care?
Lucas Fontes 19:56
Thank you, Bailey. Yes, let's get on that. Let me share my screen here. Hopefully everybody can see me — I cannot see anybody right now.
Lucas Fontes 20:24
So what I'm going to talk about is the transition from the Kubernetes story in wasmCloud v1 to the Kubernetes story in wasmCloud v2 — and there's going to be a lot of YAML ahead, so get ready. In terms of architecture, one of the key changes is that we are no longer deploying wadm or NATS. Before, the wasmCloud operator was a reflection of the data we had in wadm — it passed data between the Kubernetes API and wadm, but it was not actually participating in scheduling decisions. All the state for the workloads still lived inside wadm and NATS. If the operator went down, the system would continue to work, but if NATS went down we'd have to recover all the deployments and manifests from somewhere else, because it's not coming from Kubernetes.
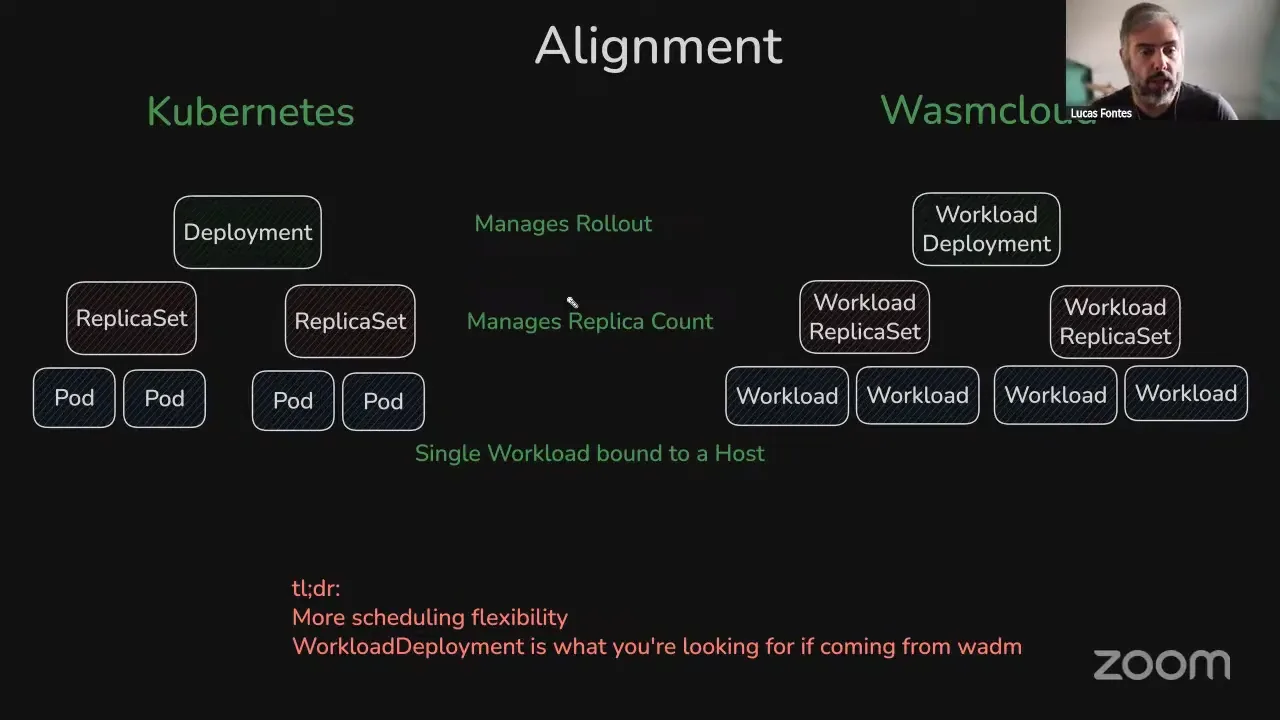
With the runtime operator for v2, we are no longer deploying wadm or NATS, and all the state is stored in Kubernetes together with the CRD definition. So the operator becomes a bit more stateless, and there's no need to worry about whether to back up your NATS or run a three-node cluster. The TLDR is the installation footprint is now smaller.
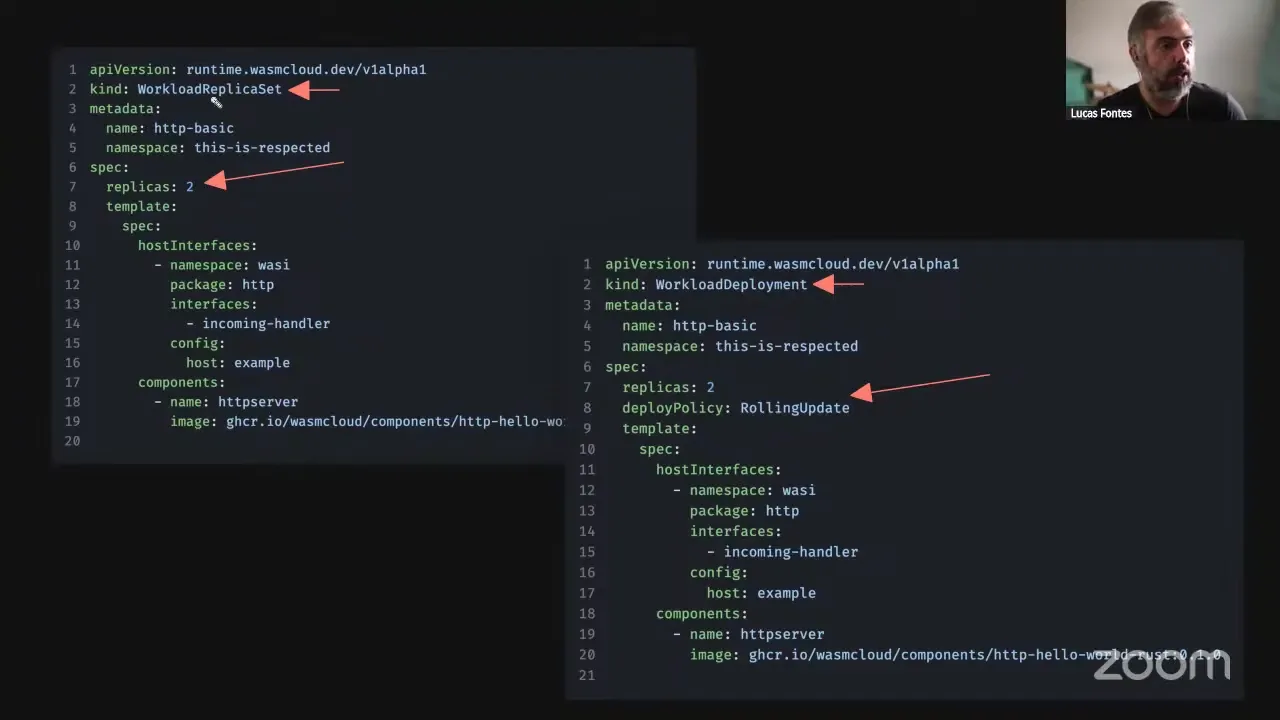
We're also doing a bit of alignment with Kubernetes proper. If you're coming from Kubernetes, you understand that a pod is a set of containers bound to a given host. In wasmCloud we're aligning the naming there: we have a CRD called Workload, which represents a group of components deployed on a single host. On top of that we have the replica set concept — in Kubernetes a ReplicaSet manages the replica count of pods; for wasmCloud we have the WorkloadReplicaSet managing the replica count for workloads. On top of those two we have deployments. Kubernetes also has daemon sets, stateful sets, and so on, but for wasmCloud right now we only have deployments. The replica set ensures a certain number of workloads are always available and placed; the deployment determines whether you want a rolling deploy, a blue-green deploy, or a canary deploy. It controls a few different replica sets underneath and orchestrates them to have zero-downtime deployments.
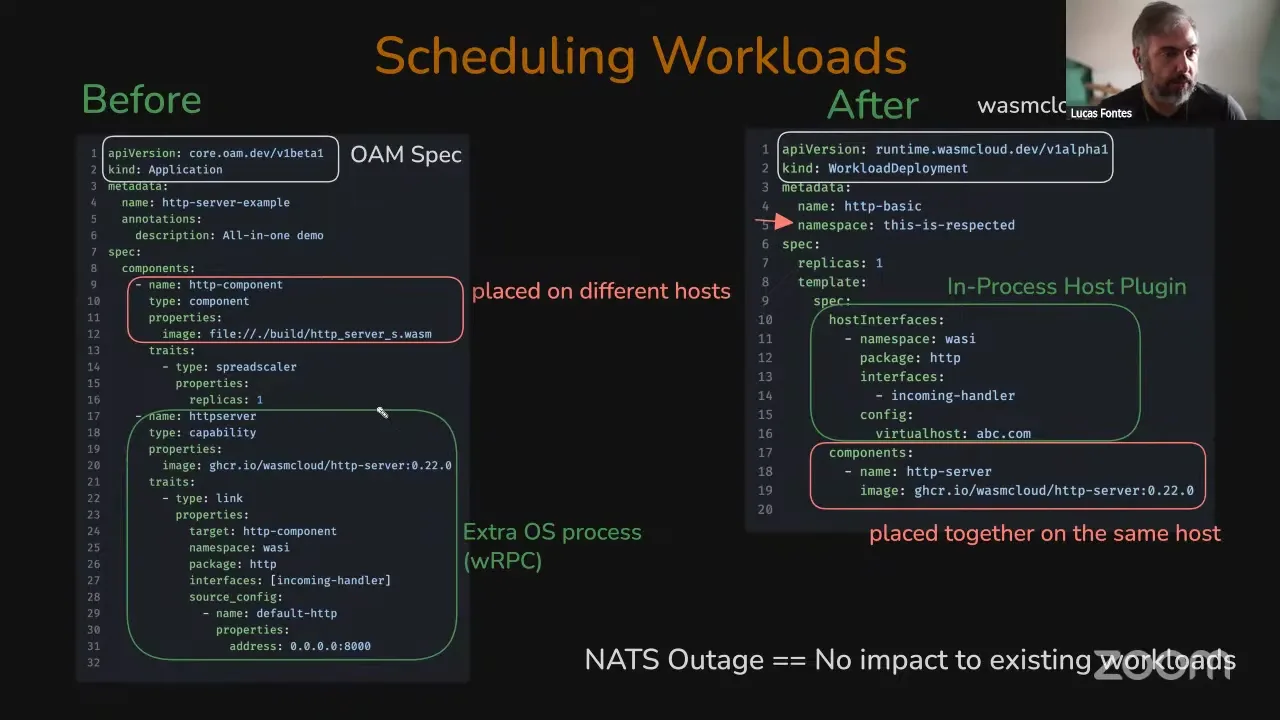
On the left we have the wadm manifest and on the right the runtime workload manifest. First impression: there's less YAML, and less YAML is good. One key difference — we are going from a concept where you could declare components that have unresolvable interfaces. For example, you could deploy an HTTP component without a provider that backs that HTTP interface. Now, within a workload, all the interfaces are expected to be resolved — they have to come either from another component declared in the workload or from the host. With wasmCloud v1, if you forgot a provider, the system would still accept your application and it would turn into an outage, because there were pretty much no checks on whether all the interfaces could be fulfilled. Now we bundle that all into a workload: you have a set of interfaces you need and a set you're providing, and that Venn diagram should be a circle.
Another interesting thing: with wadm, the list of components you add isn't guaranteed to be placed on the exact same host. You might deploy an application, see higher-than-usual latency, and not understand why — your component is going to NATS, taking the scenic route, and coming back to the exact same host. For the new specification, everything you declare in a workload is guaranteed to be deployed on the exact same host. The identity for the workload is at the workload level, and then we have individual identities for each component, just like Kubernetes and containers.
Lucas Fontes 30:20
The third thing has to do with providers — the interfaces that aren't coming from any component. With wadm we had the concept of external providers, which you declared in your configuration; the wasmCloud host downloads that binary on the spot and executes it on the host. You can imagine the security challenge that poses. For the new model, what we have is in-process plugins. These are written in Rust, they're part of the binary that ships with the host, and they have access to the same environment as the rest of the wasmCloud host. The same instance of a given plugin is shared across all workloads, but each workload has its own context and its own boundary for data access. And because components are now placed together on the same host, if you have a NATS outage we are not impacting existing workloads — we're only impacting the scheduling part of the system.
Going beyond the basics, we have the ability to target hosts by label — something we also had in wadm — but now we also have the option to force-schedule a workload on a given host ID. The host ID is now simply a UID; once you have it, you can staple it into your workload definition and that forces the workload to always be placed there. We also have the ability to export volumes to components: we can expose an empty directory or a host path, and just like Kubernetes we declare the list of volumes we want to expose to the workload, then each component can claim a given path. These paths can be different on each component.
The host interfaces section is optional — only in case you need some extra interfaces from the host. In my earlier example I did not specify a version, because the host will try to find the best match. But if a workload requires a specific version of a WASI interface, it can lock it here. So if you wrote something for blob-store 0.2.0 but 0.2.2 is coming out, this lets you be really specific about your requirements. Liam, I see you have your hand up.
Liam Randall 34:54
I was going to let you know there are a couple of questions in chat. Frank Schaffa wants to know — since we're doing this with Kubernetes — is affinity or anti-affinity being considered?
Lucas Fontes 35:12
Yes. The concept of affinity and anti-affinity will be part of the replica set and deployment controller.
Liam Randall 35:24
One quick question — so when you have a host interface that's asking for something specific, with the host selector requirement, that's what it uses when making a scheduling decision?
Lucas Fontes 35:42
Right. Let me do a little detour on that, because it might be interesting to see in action. Subscribing here on a health check — the host now tells the scheduler "I have all these plugins available," and the operator uses that information to find the correct one.
Bailey Hayes 36:26
Hey Lucas, I have a quick question for a point you're about to make. Is it possible for components to share the same directory in a volume mount? So I have one workload and two components that want to work on the same file.
Lucas Fontes 36:43
Yes. These can be either a host path or an empty directory. So you can imagine a situation where you have one component being the worker and one being the producer — you can request an empty directory and use it for message passing.
Moving on: version locking, pretty important. The host interfaces have an optional configuration — for example, WASI HTTP accepts a host, letting you declare which host you want that component to respond to. For blob store or messaging you'd pass which topic to subscribe to. Notice the binding says "I'm a component and I need to serve HTTP for host example" — this information is now part of the workload, not a provider link external to the component.
We also have image pull secrets. On v1, when fetching component images, we can now specify a regular Kubernetes secret used as a registry credential. We can define a pool size — essentially "I want five instances ready to go," and if you go above that you spin them up as needed. So if you want to deal with bursts — a flash sale where you expect 1,000 requests all at midnight — you have that memory ready to go and spend less time in cold starts. The pool size works together with max concurrency: one tells you how many to keep warm, the other tells you the limit. When you reach that limit, the component doesn't emit a trap or fail — there's a queue, so we're essentially applying back-pressure on local resources.
We can also separate configuration per component. Because components are a list, we might have volume mounts or configuration that apply to one component but not a sibling. You can fetch configuration from a config map, a Kubernetes secret, or as literals, and we overlay them — secrets, then config, then literals. And the last one is pretty fun: the concept of allowed-hosts, which controls which HTTP outbound hosts a component is allowed to call. So if you're deploying a group of four components and only one is supposed to make HTTP calls, that's the one you add allowed-hosts to. By default all hosts are allowed; we were thinking about introducing a deny-hosts as well. The point is, because we have access to the host name components connect to, we can enforce policies on it.
Frank is asking if there's a capabilities equivalent of network policies to control who can talk to whom. Workloads only talk within their little bubble; if they want to talk to another workload, they have to go through Kubernetes networking. In the next iteration we're looking to give each workload its own IP address, so they're addressable directly from Kubernetes. The control we're starting with right now is on top of an existing WASI interface — it's not on top of TCP/IP — and it's an outbound interface, because the inbound interfaces are way more complicated to implement.
Let me show some things. I have the operator installed, I have a host, and a couple seconds ago the host was sending its heartbeats. We're now including more information in the heartbeats: system CPU, memory, and all the interfaces exported by the host via its host plugins — key-value, blob store, config, and HTTP. We get a list of all the hosts coming up inside the Kubernetes cluster; they register with the operator and report as a regular CRD. Instead of doing wash get inventory, you can do kubectl get hosts. They'll be marked as not reporting if they haven't communicated back within two health checks.
The next one is workload deployments. I have an HTTP workload here. Let me describe it. We have the deploy policy — this is a rolling update — and the spec saying this is coming from the hello-world-rust component image. In the status is where the fun is: we know the artifact was fetched correctly, we know the workload is in sync with the host, and the number of replicas we requested is the same as we see in the system. We also have bookkeeping — which replica set we're deploying, how many are ready, how many are still coming up.
Lucas Fontes 46:36
From the workload replica set we have the actual workload, and when we get to the workload level we now see exactly which host ID that workload is running on. There's an extra switch that also includes the host name. Why is this important? Because this is the identifier present in logs, traces, and metrics. So with the workload you know exactly where it's placed.
Where is this going to land? This will be in wasmcloud/runtime-operator. If you want to look at it right now, you can go check cosmonic-labs/runtime-operator. When should it start landing inside wasmcloud/runtime-operator? Together with the host v2 — the runtime v2 — which is the work Bailey was talking about. I talked a lot, so I'll stop here and see if there are any questions.
Bailey Hayes 49:12
This is awesome, Lucas, thank you for the walkthrough. I dropped some links earlier — one being an implementation of the Workload API. Brooks gave a similar presentation last week going through the architecture of how that API works and how we'll build a host around it for v2. I talked a little about wash v2, which is designed around this whole evolution — both the Workload API and making everything pluggable — and then obviously, for the deployment side, to take it all the way to prod you need a good deployment story, which this runtime operator really fills. We've been dogfooding it in our own deployments and it's real nice. We've got rolling updates, we can control which version we're deploying, we're deploying via Backstage and Argo CD so we can do GitOps against all of this. It's been a huge improvement over what we had in v1. We've learned so much over the past year running on wasmCloud v1, and I think we're ready for feedback. So folks doing this, let us know if we've solved all your problems — or, perhaps more likely, what problems remain.
Frank Schaffa 50:42
One thing — this is really great, great presentation, Lucas. If I want to play with this at home, is there also documentation so I can try this on my own?
Lucas Fontes 51:08
Not right now. We have the operator in the public, we have the runtime being developed, and then we have the mock host on my computer and Brooks's computer. We're looking to make sure these things aren't simply dumped there — we want this as a single drop, with the runtime, the host, and the operator going to wasmCloud together. But in the meantime we're doing all the development in public, so you can go to the new runtime and to cosmonic-labs and see the new operator.
Bailey Hayes 51:52
We don't like to point folks in the wasmCloud call to what we're doing on the commercial side, but Frank, I know you've been engaged with us there before, so I'm okay to say: if you try our trial, that deploys with a version of this operator that we've embedded inside our product.
Liam Randall 52:22
We've been trying to move this along really quickly, co-building it with a number of folks and getting feedback, so we've been iterating on the interface. The plan is to get an updated release out in the next couple of days — Friday or Monday — that will land some improvements compared to what's available right now. It's all in the public repos that were linked. I think it's a lot more elegant from a deployment and integration perspective — one of the big things is it really enables you to leverage the entire Kubernetes ecosystem out of the box. There's a nuance there, which Bailey mentioned in chat: the wasmCloud host runs in a container, so all your containerized controls work here. And for each component running on top, there's differential support for the entire pipeline — for example, signing a component works just fine, and there's a new blog post we put up a couple weeks ago documenting that. We're still dialing in the per-component IP controls so you could control which component can talk to which. If folks have ideas, requirements, or requests, we'd love to hear them.
Bailey Hayes 54:49
So, Frank, I'll drop some steps. We've got a Cosmonic channel in our Slack, so I'll point you there. As you can tell, there are like four key moving parts, and keeping them all in sync while iterating really fast is a lot easier when you ship a single package. So I'll send you a link to the single package and all the links to where we're doing the different drops across these repos.
Frank Schaffa 55:31
Okay, great. Thanks.
Bailey Hayes 55:38
Any other questions about the operator? Okay, I've got a documentation PR of the week. First things first: Eric's PR that we mentioned last week landed. We've been adding documentation — it would be closer to say we have a placeholder where we can make sure we get really good docs before this release. If you go to wasmcloud.com and our docs, you can drop down to "next." Next already has how to install and work with the next version of wash; the runtime operator is in the queue, and so is the next host. Eric, anything more you want to see on that front?
Eric Gregory 56:28
Yeah — just that the latest PR in the docs repo has a breakdown of the proposed outline for a reorganization of the docs moving forward. So if anyone has thoughts on that outline and wants to add commentary, that's very welcome and appreciated, and we'll continue iterating forward on the pieces of this next release.
Bailey Hayes 57:32
Cool. The other thing on our agenda, wrapping up — we try to bring in any community updates we can, and I have a pretty cool one: Wasmtime cut a release with the WASI P3 first RC. So WASI P3 — there's an initial version implemented in a runtime near you. If you think that's exciting, you're welcome to talk to us and we can guide you through it. It's a release candidate that already has outdated interfaces — we've already made updates across all of them, that was expected — and we've got a couple more iterations to do on that front, definitely more in terms of language toolchains. So this is very much focused on the host side of the equation, but it's happening, it's getting closer, it's looking real. We're on track for our current roadmap, so I'm pretty pumped. You're going to see some big changes in your Wasmtime embedding, because we went from sync to async, y'all. We're aiming to consume and deliver that as part of our next host version — we're probably not going to take this exact RC, since we're also the ones who made these interface changes to fix them upstream. We want our changes to land first, and then we'll integrate those into the next version of the wasmCloud host.
Liam Randall 59:00
I would maybe comment — Jakob's company, Betty Blocks, put a nice little video into the wasmCloud Slack. If you have a chance, check that out. They're doing some cool stuff with Wasm there. I think it's worth the watch — WebAssembly components — and I think it also ended up on YouTube.
Bailey Hayes 59:21
Yeah, please hop on our Slack. Like, subscribe. All right, thank you everybody. Hope you have an awesome day. Bye.
Bailey Hayes 1:00:18
I mean, look — would you say you're a serial lurker?
Justin Janes 1:00:18
Maybe. There are a lot of plates I started spinning at the same time, and they come in and out of focus. Around 2018, right when I started hovering around wasmCloud, was the same time I was hovering around machine learning and Kubernetes. I just left my Kubernetes QA job at SUSE back in April/May, and I'm circling back toward machine learning right now. I still know WebAssembly has a future, but because machine learning is so disruptive at lots of different levels of abstraction — people are even considering using it in beamforming algorithms for wireless access points — it's having pretty far-reaching implications.
Bailey Hayes 1:01:20
I could see how a model would be helpful for that on the edge. I totally agree — that was a lightbulb moment for me. I've been building MCP servers with Wasm, and it's perfect for that use case. I've been making upstream changes in a lot of places, but basically I've got it now where I can take the TypeScript Model Context Protocol SDK off the shelf with a template I'm going to open source, hopefully by the end of this week. You take the open source SDK they provide and it just compiles to Wasm. The trick was that I had to change it from Express to Hono — getting it onto something using the WinterTC standard instead of straight-up Node.js stuff — and then I've got something really tiny, scales to zero, starts really fast, perfect for all these serverless use cases. Everybody wants to remote-host these things, so I'm pretty stoked about that use case. I think agents make a million miles more sense as a Wasm component than as a container.
Justin Janes 1:03:48
Especially with isolation, right? Other than the TypeScript SDK, are you using the wassmcp project Taylor worked on?
Bailey Hayes 1:04:00
I've played with that — these are pretty radically different approaches. That one aims to load components as tools, but the server itself doesn't compile to Wasm; the server is a customized embedding of Wasmtime, and it really seems designed for localhost use cases — like, what local developer tools could I use in VS Code. It doesn't expose what you'd expect today. So my theory is different. There's also a third approach called wasm-mcp or mcp-wasm, where they've tried to take the MCP protocol and convert it to WIT, and the transcoding and HTTP request are abstracted away — you define yourself as a tool. That's probably the hybrid between wassmcp and my approach. I went the full extreme: the protocol itself is HTTP-based, it's streamable HTTP, so let's do it as WASI HTTP all the way down. If I want to add custom policies, I compose it with another component. My host does TLS termination, and if I need to filter or do something special from a middleware sandboxing perspective, I can do that right there — and I don't have to do anything weird to make it compatible. I can take the thing off the shelf and it just works.
Justin Janes 1:08:31
I think a lot of people are in a similar space — augmenting yourself through LLM-based tooling, and augmenting the LLM-based tooling to better augment yourself. It's a meta loop. A lot of people approach it with the tools they're familiar with. I've done a lot of my own agent massaging locally — I want it to follow the test pyramid, maintain a particular shape, implement categories of tests. I keep coming back to recognizing that Kubernetes and NATS and a lot of modern tooling are still struggling with multi-node functionality, and I'm like, maybe it's time to revisit Plan 9. I've taken to using the Microsoft/GitHub spec kit — it starts by planning, telling your agent to plan and planning with it.
Bailey Hayes 1:11:24
That's why I don't have a problem taking meetings now — I'm being productive, Claude's doing some stuff for me right now, it's cooking.
Justin Janes 1:11:39
I'm honestly shocked none of them come by default with git commit as a post-command hook. That was one of the things I added as a pre- and post-command hook with git, doing git commit or git branching, so you're protecting your changes — I've had some wild behavior come out of them. I use multiple agents — Claude and Gemini — and I'm highly favoring local-first machine learning algorithms.
Bailey Hayes 1:12:26
Are you using Llama for some of that?
Justin Janes 1:14:10
Yes, but I've rewritten a bunch to use particular model files from Hugging Face. There's a company started by some MIT grads who had some algorithmic magic — they were using the C. elegans worm and deduced a better activation function for neurons. They used it initially on self-driving and drones, and they were able to drastically reduce the size of a neural network from thousands of layers to nineteen. It's called Liquid AI now, and they have a bunch of really small, performant models. If you get topically focused, I'd encourage you to look at fine-tuning them. Are you familiar with the acronym MoE — mixture of experts? The crux is you have a model that's actually five, eight, etc. other models under the hood; one does routing from your prompt, and it loads the appropriate model into memory to answer your request at the highest quality. There's also work Google wrote about this last week called "sled," and an older paper about cascade querying, where you do parallel prompting — if your local LLM has low confidence it offloads to the larger remote LLM for more qualitative output.
Bailey Hayes 1:16:15
I think this is exciting. It's like — you remember that xkcd comic about when you first learned how to code in Python, you feel like you have wings? I feel that way again. Even though my time is so split up, changing context every hour kills me. Old-school me would have had to write that code, and I needed a block of two hours to write anything worth anything. Now I don't, and that's awesome. I am blocked very much on code review, though. I'm not comfortable merging stuff to main until a human has really gone through it, and understanding the approach some of these large bodies of change took is really time-consuming. So I still feel like that's the great bottleneck.
Justin Janes 1:18:26
You need to put a little more trust in that. I have an agent that's particularly critical on purpose — basically to audit what's done on behalf of me. There are good results already at code review on GitHub.
Bailey Hayes 1:18:26
What I need is to give up on quality a bit. For my open-API-to-MCP tool, my first pass I let it go ham — here's a Python version, write this in Rust — and it worked, which felt like magic, but it didn't have any of the design parts. So I did another iteration laying out the abstractions, and ultimately one of my developers said "Bailey, I can't maintain this mess, give me two days," and they rewrote it themselves and deleted thousands of lines of code. Operationally those lines didn't bother me, but cognitively it was a high load for both the LLM and my dev. I'm still split, because I keep finding bugs in the human-written version and it's making me grumpy — I know I handled that case, because I prompted for it.
Justin Janes 1:19:56
Focus more on the intermediate layer. Instead of zero-shotting or one-shotting the translation, have it generate the document that describes the key algorithms and assumptions — that's an underutilized benefit for translation-type tasks and reviews. One thing I worked on: the Go compiler doesn't check for multiple locks on mutexes or wait groups that aren't properly released, so I used Claude and Gemini to write a constraint solver to scan for that, and I've surfaced hundreds of bugs. It was more beneficial when I had the intermediate layer between those two tasks.
Bailey Hayes 1:21:10
That's really helpful. I'm going to play around with spec kit, because I imagine that's the intermediate layer where I'd iterate. We should probably include a bit more of an AI/ML update at the end of these. I'm constantly a little overwhelmed by how much is out there. Even for my team — I posted in general last night: we're using the Claude team plan, ChatGPT I scaled back, and Copilot is getting good, though I've noticed it's just copying straight from Claude. I think Claude will ultimately win, even though these other companies are way more agile — with AI, big companies that used to not be agile now are.
Justin Janes 1:23:02
Don't ignore Gemini CLI either. When your Claude allocation fatigues, Gemini is still good for generating the planning and iterating on the design part. And the models you can pull locally are another good tool — like the Liquid ones. Let me find that Hugging Face URL.
Bailey Hayes 1:23:50
Hey, you're teaching me and I appreciate it. Wasm was so close, and then AI kind of took all the air out of the room. But if I can attach Wasm to the AI train, then we can get general-purpose compute that doesn't suck. What gives me a lot of anxiety is how much we're setting the planet on fire with all this. When I talk to enterprises — I showed one the MCP demo last week, and they said "this is great, because we already have a thousand MCP servers," and I'm like, oh my gosh. You know what it is? It's a container. They just took their current infrastructure footprint and 2x'd it.
Justin Janes 1:24:41
You'd like Liquid even more from that efficiency standpoint. Here's the link to theirs running in WebGPU.
Bailey Hayes 1:24:53
Did you know we hired the guy who's the champion for WASI WebGPU?
Justin Janes 1:25:35
In my current role there's not enough headcount and no way to scale except by heavy automation, so one way or another I'm going to be doing this.
Bailey Hayes 1:26:27
I do expect this bubble to burst — all the VC funding has been injected for the right amount of time for that initial cycle where a lot of them fail and then people get cold. It comes in waves; the moment somebody gets really successful, the wave goes back up. But I'm expecting a down wave in the next month or two.
Justin Janes 1:27:11
I fundamentally believe that even the large models — I don't think we need them that big. When you look at how capable some of the smaller models are at particular tasks, what we'd really benefit from is expediting someone saying "I have this task, this goal, this research direction, and I need to very quickly fine-tune a particular model with some level of reasoning toward that goal," and then run that small model locally. If you look at how wasteful power toward email is — how much email is junk mail, how much of the power grid does that consume? You could toss in operating-system features no one has used in 20 years. There's a lot of underutilized functionality, and I think we can bring this new, highly functional, dynamic system closer to home. We could make what we already have more efficient.
Bailey Hayes 1:28:35
I've got to have something like sled in place. That's the key — something very efficient about selecting the right model. The only reason these large models are so popular is that people just sit on one for all the things.
Justin Janes 1:29:19
It's still true for WebAssembly — I don't give up on it. Where you're at in particular, close to the Bytecode Alliance, I still think there's a lot of potential there. Otherwise I wouldn't be here. I consider myself fairly well read — I'm reading five or six research papers every day — and I still think it's very relevant, but maybe more toward Plan 9. That's my bias speaking. Feel free to DM me with any questions, or if you're like "do you know of a tool that does this?" I'm happy to share anything I've learned and spread the knowledge.