Transcript: wasmCloud Q3 2025 Roadmap: Component Model, wRPC & a Simpler Host
wasmCloud Weekly Community Call — Wed, Jul 9, 2025 · 102 minutes
Transcript
Brooks Townsend 04:00
Hey everybody, welcome to wasmCloud Wednesday for Wednesday, July 9. Today we're going to be doing our quarter-three roadmap planning — the general wasmCloud roadmap over July, August, and September. As a reminder, this meeting is totally open; anybody's welcome to come and share their perspective on wasmCloud. We also open up a GitHub discussion ahead of time so we can talk about specific issues and find the things the community votes on to put on the roadmap. Before we get into the nitty-gritty, we usually have a new community member joining us — maybe not new to the community, but first time on the call. Alex, would you like to do a quick introduction? How you found wasmCloud, what you do — the floor is yours.
Aleksandra Jones 04:57
Hi everyone. My name is Alex Jones. I'm a technical trainer with Linux Foundation Education. I work on WebAssembly, cybersecurity, and other content for the Linux Foundation to help educate learners on open source technology. I found out about wasmCloud when I was learning about WebAssembly as an intern for the Linux Foundation, so I've known it for a couple of years now. The reason I wanted to come on this call is to learn more about the community and to interview Brooks and anyone else interested in providing information about wasmCloud, so that other people can see the project, learn more about it, and hopefully either join the project or use it in their own production projects. Thank you.
Brooks Townsend 05:51
Awesome. Thank you so much, Alex, for being here. If anybody wants to share their perspective on wasmCloud, please do — a lot of the folks on this call are maintainers or long-time community members, but for anyone interested, Alex posted something in the wasmCloud Slack a little bit ago. Great to have you here.
Brooks Townsend 06:22
All right. Now that we've done that, the rest of the meeting will pretty much be roadmap planning. If folks have things they want to bring up for the Q3 roadmap, now's a good time to queue that up or paste links in the chat. As is tradition, I'd love to do a quick retrospective on the last roadmap — see how we did and reflect on the goals.
For Q2 we tried a new separation of categories. Instead of organizing by feature/bug/documentation, we organized all tickets into research, development, or good-first-issue. That separation made the roadmap more approachable: people who've contributed before can take development items, first-time contributors can make a dent through good-first-issues, and research items — which require project perspective and history — are usually better taken by a maintainer leading a specific effort. I think that was a great success.
As far as the big pieces of work: we made great progress on wash plugins — you can write WebAssembly component plugins to make subcommands for wash. Something I've been working on as we got to the end of the roadmap is essentially wash reimagined as a plugin model first. I haven't shared that work in the community call yet, but I hope to next week. On the wash dev dashboard and output story, a community member took up the issue of providing the wasmCloud dashboard with wash dev, which has been going great. We've also seen good brainstorming around an OpenTelemetry dashboard for debugging applications. Aligning wash with the XDG directory specification went great — a community contributor implemented that, so it's complete. And we've done a lot of research into the strategy for wash dev, which feeds into pluginifying wash.
Coming into the individual items: two things are still in the "ready for work" phase, which I think we can roll over to Q3. They're still warranted. Deep design exploration of HTTP was one of the biggest items from the last roadmap, and I wouldn't say we've done no work — Massoud implemented the built-in HTTP client provider and did some reorganization of crates there. But it's still worth more deep design exploration, especially with WASI P3 coming down the pipe. The other one — the provider key-value NATS issue that appears to hang — seems a little hard to reproduce, but it's still worth taking a look. I'd actually propose that as a good-first-issue for the next roadmap.
The two we didn't start — pluginifying wash and the host configuration file — I don't feel too bad about, because I've been working on both, trying to come up with the right abstraction and level of detail. I'd love to share more next week so we don't bog down this discussion.
My favorite thing from this roadmap, the thing that makes me want to carry the format forward: on the good-first-issue list, other than a couple I need to merge myself, every single item was completed by a community member, a contributor, or a maintainer. So many were taken by new contributors who came in and solved a couple of issues, which has been awesome. Huge hats off to everyone who came in. I'd love to keep highlighting issues on the good-first-issue page every week in the community call — pick the next one down the list, highlight it as an issue of the week, and move on. We've gotten great gains from that.
That just leaves completed work: we punted on some of the workload identity work, but we do have an implementation of the identity interface and you can use workload identity to join NATS and get credentials. A community contributor replaced the .wash directory with the XDG base directory spec. Eric added documentation, with help from Roman, for handling wRPC error — the special error format you can now use in your custom WIT interfaces to handle transport errors. And community members came in for wash updates and allowing external access of the host ID. So many of the issues on the Q2 roadmap were completed by community members and contributors. Without getting too warm and fuzzy, it warms my heart. Does anybody have thoughts, questions, or concerns from the Q2 roadmap before we move on to Q3?
Brooks Townsend 17:09
There were definitely things not on the roadmap that are well worth shouting out. Hats off to Massoud for contributing the NATS blob store capability provider. It's awesome to see more and more capability implementations on NATS — with the current status quo, where you run wasmCloud alongside NATS, you get a message bus, a persistent key-value store, and now a blob store (a distributed object store) all using the same infrastructure. You run NATS, you run wasmCloud, and you have all these distributed cloud capabilities — you just have to configure NATS. We've basically implemented the whole WASI cloud world, all of it, because config is also stored in NATS JetStream. Good job, NATS and WASI cloud — you're friends.
It's worth mentioning that over the last quarter we had a little scare thinking about what the future of wasmCloud looks like in terms of NATS, and we're pretty happy to have settled on no changes necessary. wasmCloud and NATS are going to work better together in the CNCF space. While I think it's good — thinking forward to Q3 — to find ways to make the wasmCloud host simpler, I still see tons of integration and power for plugging in with NATS, especially for our distributed edge and distributed cloud story. There really isn't another project that can replace it wholesale.
Something we took off this roadmap, just because it's hard to track and takes a lot of maintainer time, is the development of WASI Preview 3. wasmCloud is only a small but critical part of WASI P3 development. Our own Bailey Hayes is working all the time on the Bytecode Alliance side to steward the standards. Victor, a wasmCloud maintainer, has been spending a ton of time on the JavaScript component tooling and the JS runtime side of the component implementation. And Roman, another wasmCloud maintainer and the creator of wRPC, has been implementing WASI P3 in Wasmtime — fixing bugs, testing, implementing component-model async. These folks aren't the only ones doing it, but they're spending good time and putting forth good work. Thank you all. And Colin, you're here on the call and involved in WASI more tightly than I am, so thank you for your service.
Brooks Townsend 21:43
So just as WASI P3 was a big part of our Q2 roadmap, it'll be a big part of the Q3 roadmap as well. I didn't capture it on any specific tickets on the wasmCloud side yet, because I don't think we're really in a spot to integrate anything, but as general background: we're looking forward to the next iteration of WASI. The 0.3 previews are expected sometime in August. This refactors some of the 0.2 interfaces like HTTP and IO, and it adds native async support to the component model — a huge piece of work. Thanks to everybody on the Bytecode Alliance side contributing there.
Okay — that's the last bit from the Q2 roadmap. Let's move on to Q3. The only things present on this board right now came in this morning, whether they were existing issues or ones we created wholesale. Last week in the call I shared a blog I'd been working on — a couple of weeks ago we published a "Year of wasmCloud 1.0," which is an awesome milestone. In the second part of that blog, "charting the next steps," I tried to gather the feedback we've gotten in Slack from developers and people deploying wasmCloud in production. I work at Cosmonic, so I work with enterprises using wasmCloud internally, and I tried to gather that feedback to outline what's working really well and what isn't. It's not to say we haven't addressed these issues — it's to inspire ways to do better. The pluggability of components, our NATS extensions, wash dev as a developer loop, and language-specific SDKs have been awesome assets. When I look at the things that didn't play out exactly as planned, I used that to feed the issues on the roadmap.
Everything on here is up for discussion — this is community roadmap planning, so anybody's welcome to say "I don't think we should do that," or "this needs more detail," or to propose more items. Before the fun discussions: the good-first-issue list is actually really thin right now, so I'm interested if folks want to file good-first-issues. Those are usually smaller-scoped and can come in at any time.
Moving to the development triage: supporting in-process component-to-component calls. This is something we've talked about for a while, and I think we should do it. In the blog I called out that when components run in the same WebAssembly runtime — the same Wasmtime instance — they can call each other's functions with a couple of nanoseconds of overhead. If you compose two components together, you'd see that. But what we actually do today is: anytime a component wants to talk to another component, it goes out over the wRPC/NATS transport. That has nice properties — it's predictable; two components on the same host or on different hosts go through the same transport path. But it has downsides in performance: it's not nanoseconds, it's a couple hundred microseconds of hitting a NATS node and coming back, and there's potential for network fallibility — if the leaf node goes down, components can't communicate. What I'd love is: if you make a decision when deploying components to put them on the same host, you should be able to be specific about that so they can communicate directly. I still think this is a runtime platform concern over a developer concern — you shouldn't have to program "I'm going to be running next to this other component" into your component — but it should be an option. Massoud, you had a comment which I think is super fair.
Massoud (ossfellow) 29:41
Well, as I said, this requires more intelligence in the host — distinguishing if components are in-process or out-of-process to route the traffic. The idea is good, but at least from that perspective it contradicts the other ticket that's attempting to trim down what the host knows and does.
Brooks Townsend 30:16
Yeah, that's super fair. I think for how components talk to each other — whether it's distributed or in-process — the host should basically be told exactly what to do. That might sound abstract, but all I mean is the host shouldn't be making a game-time decision when a function is called, like "am I running that component locally, or is it located somewhere else in the lattice?" Just like we have links today, the host should be told specifically: "you're running these two components, and they're going to talk to each other in-process." That's the principle I'd like to approach this with. There are ups and downs to anything, but that's how I feel.
One thing we talked about for a while: on the link itself, when you tell the host where to route something, we could include a transport — does this go over NATS, over wRPC/TCP, or is it in-process? That one's still in triage because it needs more detail, but I've put myself on it.
This next one may be a little spicy, but it's worth talking about. In wasmCloud we still use nkeys to sign our components and capability providers. We don't use them for routing or capability claims anymore — that's a vestige of the past. We use wascap for embedding a JWT in a component so you can know who signed it and its build identity. These seem a little at odds with emerging standards for signing artifacts; Sigstore seems like something people would be interested in. The signing step remains a little confusing — you run wash build on a component project, you build it, then you sign it, and now in the build directory there's a component and a signed version. I don't think signing itself is bad to keep, but over time we've seen more success ditching wasmCloud-specific standards, and I don't feel we've been using these in real deployments to any particular gain. You don't have to have a signed component to run it in wasmCloud — that was a specific decision for 1.0 so you could take a component off the shelf and run it. We still sign all our artifacts when we publish them, but I don't know of real use cases relying on this right now. wascap, nkeys, and the provider archive format all solved a problem at the time and aren't so needed in a component-based world. Massoud, you did a lot of the investigation into Sigstore and signing artifacts — any other thoughts?
Massoud (ossfellow) 36:32
The implementation of wascap is custom — it could be replaced. The point is that I think we'll live in an era where signing is preferred over not signing and making it optional. The question is, if we consider that a good feature, how do we want to approach it? This is a product used not only by lay people like me but also by corporations, and feeding into a framework that's more compliant with the ones used in the corporate world is not a bad idea.
Brooks Townsend 37:40
Yeah. Massoud, would you be interested in throwing some thoughts into this issue?
Massoud (ossfellow) 38:04
Yes — I'll do my research and put the responses there so we can discuss it later and decide as a community.
Brooks Townsend 38:04
That sounds awesome. I'm not trying to arbitrarily cut things, but I do feel these add confusion to the initial process and aren't particularly used when packaging an artifact. With your research, you'll dig up the right thing. I'd much rather have an example for "here's how you Sigstore-package a component."
Taylor Thomas 38:40
Yeah, I'm totally fine removing this. The only thing we might want to check with some people on — I don't think it's being used this way — is that the nice thing about nkeys was the string format: a publicly cryptographic, unique identifier for routing purposes. We're not leveraging that right now; we used to. There might be people who'd use that kind of feature, so we should double-check. But overall I'm in favor, because it's additional complexity we don't need. And there are other ways to do that — we're using SPIFFE and other things — so that could be leveraged if we need to.
Brooks Townsend 39:31
That sounds great. I like what Luke called out too — we could sign things with Ed25519 keys and still keep a similar thing. I'll tag Luke so he's aware, but make sure to follow up with him too.
Brooks Townsend 40:10
This next one is a continued motion toward reusing existing standards and things that work. I've tried to examine some of the things that are wasmCloud-custom and see what we can drop if it's not really helping at the project level. Thank you, Massoud, for signing up to add more thoughts there.
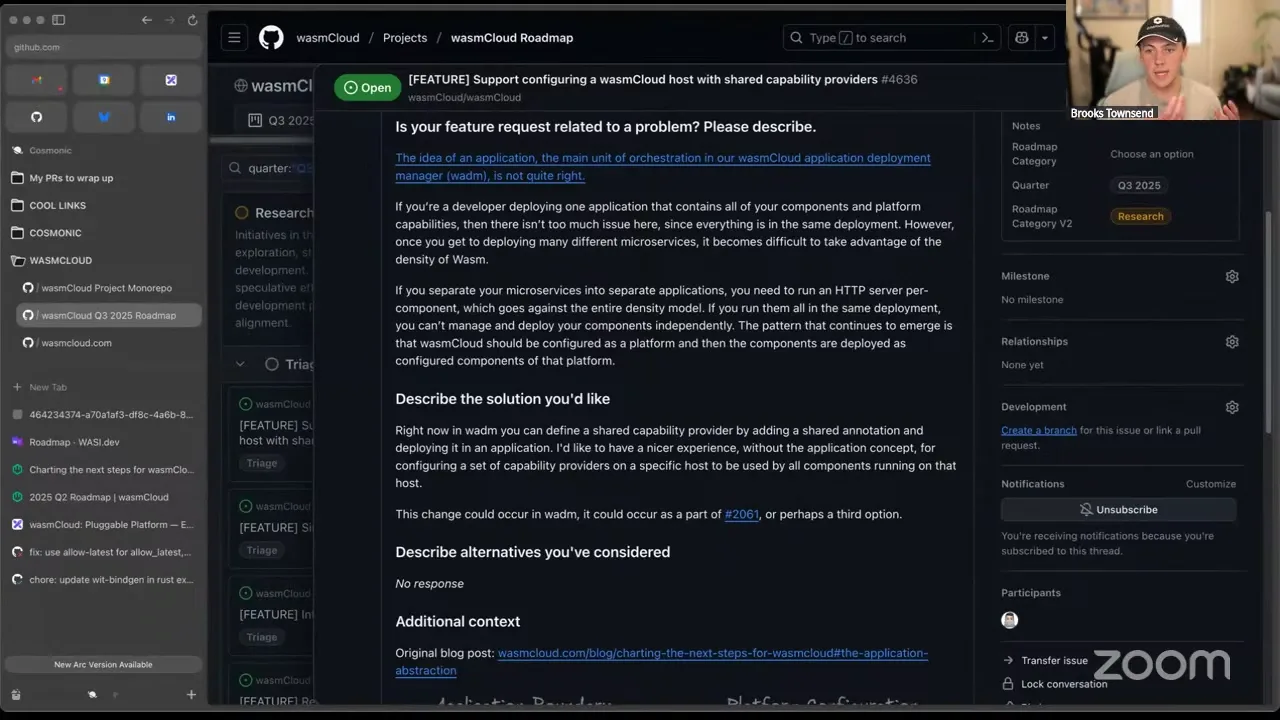
Okay, into the research category — typically more open-ended or speculative efforts. Most of these came straight from the blog post: what could be better? I tried not to be overly prescriptive on the solution, because there's plenty of room for design. First: support configuring a wasmCloud host with shared capability providers. This came up in the wasmCloud Slack just this past week. Folks who deploy with wasmCloud most likely deploy using wadm, our application orchestrator/scheduler. wadm bundles the capabilities and components you need into something called an application — a manifest format we took from OAM (Open Application Model), used by KubeVela and a couple of other projects. We picked it because it wasn't container-specific but was YAML and let you lay out everything you need declaratively. That, in itself, isn't a bad idea — it's great for a couple of isolated applications.
But on one wasmCloud host you may have multiple applications with different domains, and the commonality is that they all use similar capability providers — they all need something that implements wasi:keyvalue. With the application boundary, you have two choices: deploy an instance of that provider entirely for your one application, or — introduced after 1.0 to compensate for this — run a capability provider in shared-provider mode, where you run it as an application and say "this provider is available for anybody to use." That addresses the underlying concern, but what we really want is a set of capability providers configured once and reusable by many components. If I have three different components that use HTTP, I want each to have a port, path, or host name assigned to it — not an entire HTTP server each. By removing the forced boundary of the application around reused capabilities, deployments become more efficient. I don't have a strict prescription for how this should occur — it could change in wadm, or be part of host configuration at startup, or something else — so this one's really in brainstorm. But I'd love that shared-provider mechanism to be something we use to configure the wasmCloud platform: you have your set of deployed hosts, you expose some capability providers that any component can link to, and that's you configuring your platform. Massoud, you had a question — where do we capture the link configuration when the capability provider is the source?
Massoud (ossfellow) 47:33
Today, the HTTP provider's configuration says it's going to send whatever it receives to this destination — a component that wants to use it. When we separate these things and make them shared, and they're no longer expressed on the same manifest, the question becomes: where do we capture that? Does it mean the application manifest for wadm needs to be updated to move that to the component side, to make it a consumer rather than a target?
Brooks Townsend 48:28
The relationship of config to providers is complicated, especially when you think of a component that wants to listen on a specific path or port. That's a configuration property of the component — the component is saying "please expose my port here" — but the provider is the one that opens up the resource. Right now in wadm, when you reference a shared provider where the provider is the source, we still create a link from that provider to the component, and the configuration you supply in the app manifest gets sent to the provider itself. So we capture the link configuration on the guest-manifest side but still send it to the shared provider for opening up that port. We could probably do that a little cleaner. Often the capability provider has a set of information it needs to accomplish its goal, but config is more centered around the component being called or calling something else. There's room for improvement there. Does that help address what you're thinking?
Massoud (ossfellow) 50:35
Yeah, I'm familiar with the mechanism. I'm commenting that this change would still require changes to wadm — we cannot escape that.
Brooks Townsend 50:53
Yeah, if you're orchestrating with wadm, we'd have to change something — wadm may have a list of providers that's been configured, or something like that.
Taylor Thomas 51:22
I just want to call out — and you said this is brainstorming — I think the ideal future is where the platform is configured with these things beforehand. It doesn't matter what kind of provider it is — a binary provider running locally, a Wasm one, whatever. I think that'll make it clearer, because Brooks and I have had many debug sessions where we sit there and curse ourselves about "source, target, target, source." I really don't love that terminology — we were like, this was a mistake. So the ideal is going back and leaning on the imports and exports as defined by WIT, and hopefully providing feedback to the wider community on how that's done. But I'm curious if we can take steps along the way, because no matter what we do, things like wadm will evolve. We've had brainstorms around the host being simpler — we can delegate a lot more, rather than the host handling so much. The orchestration piece can be any number of things: Kubernetes, the next version of wadm, multiple things. And since a lot of people here are familiar with Kubernetes, essentially label-targeting capabilities — "this thing has these capabilities, target it to that." I think the middle ground is where I'm not sure if we can just make the jump or need an intermediate step, because the source/target — which thing has the config — is just confusing. If we can fix that, that'd be great.
Massoud (ossfellow) 53:22
Taylor, I'm fully supportive of any simplification, because that also makes maintenance much easier. But in cases of components such as HTTP or messaging, the provider needs some insight into where it's sending the incoming traffic. So we still need some way of expressing "you're sending it to this port" or "you're sending it to that topic."
Taylor Thomas 54:08
Yeah, I'm not saying that'll go away. I'm saying hopefully we can make it easier, because then it's just a platform-capability level, which is the whole idea. What's the way we do the configuration that's not as difficult to understand as we currently have it?
Brooks Townsend 54:26
Yeah, I snagged this one and assigned it to myself. I'd love to capture the key challenge, give some options, and propose something more concrete, because this feeds into the future of providers, links, and config — they're all very tightly integrated.
Massoud (ossfellow) 55:10
Ideally, providers have no purpose other than serving the needs of components. That means providers should have bare-minimum configuration — just what they need to hook into the ecosystem — and the rest of the responsibility of guiding them ("I'm here, send it to me" or "I'm sending to you") should be delegated to the component side.
Brooks Townsend 56:05
I like that idea. Speaking of providers, I've got more fun things to talk about there. But don't let me railroad over conversation — if anybody has thoughts or questions, just raise your hand. We always run late on the road-mapping session, so if anybody has to go at the top of the hour and wants to throw something in, let me know.
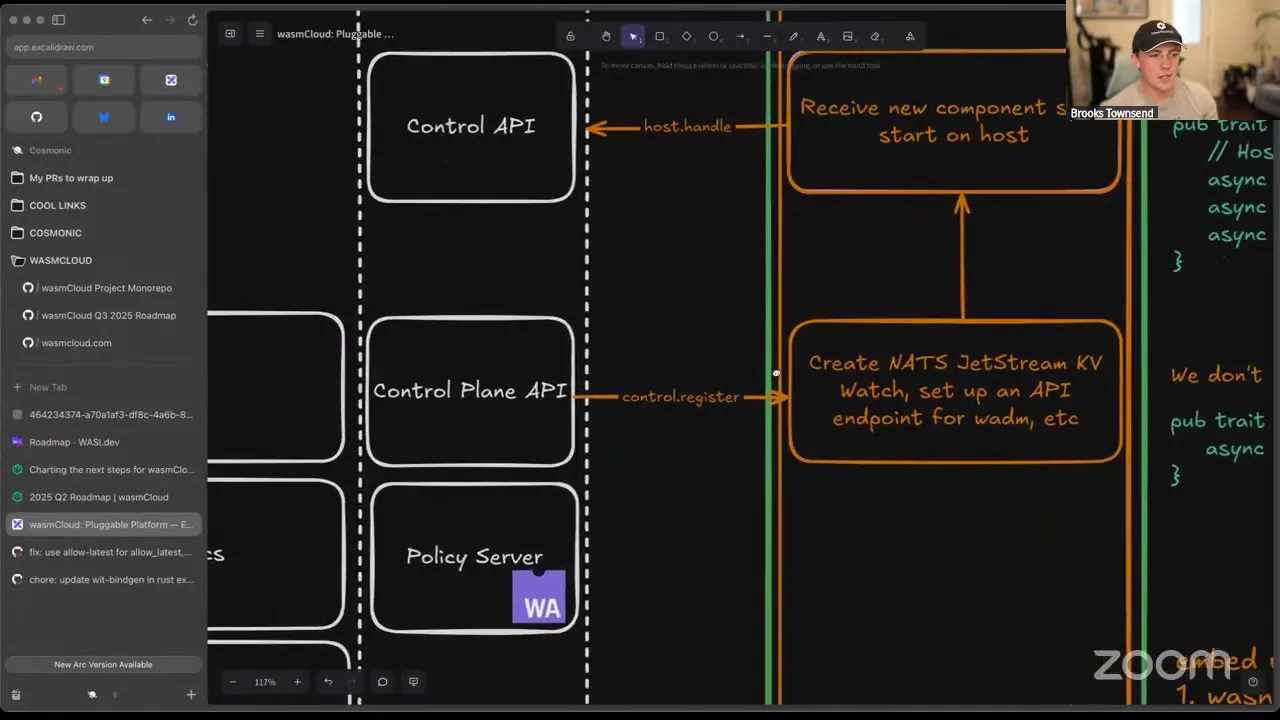
Capability providers — do we love them, hate them, can't live with them, can't live without them? I'd love to transition the capability provider model. We came up with capability providers a long time ago because WebAssembly didn't have a standard interface for networking, and wasmCloud at the time didn't use WASI, so we didn't even have file system stuff. A capability provider provides a capability to a component, and we've carried that forward a long time. We distribute them using OCI: you build native binaries for each architecture and OS you want to support — very annoying — then package it into a tarball in OCI. We've had proposals to make that better, like putting binaries up as separate layers.
But if we think about what a capability provider is: it's a binary the host launches on the same machine, which receives a bundle of configuration over stdin when it starts — "here's how you connect to NATS, here's the log level, I'm going to send you a bunch of links, I hope you're listening" — in addition to serving exports or supporting imports using wRPC. I think all this detracts from the purpose a provider serves. As Massoud said, it's meant to give a capability on behalf of a component.
So: providers as a wRPC server — name pending, naming isn't my strong suit. Really, a wRPC server could be any program, binary, container, or component that serves and implements a WIT interface over a transport available with wRPC — TCP, NATS, QUIC, UDP. As Taylor mentioned, we've called these "external providers" in the past, when brainstorming how to run a provider in a container so that, if you're already running in Kubernetes, you could control its resources independently. In combination with configuring a set of platform providers, I'd love to lean into the model where the host is told "here's where you can talk to a provider," and all that provider is responsible for is serving an interface over the transport it's told.
I was really inspired by Luke's proposal for virtual components. A virtual component is something listening on wRPC that can be addressed over wRPC — if you know where to call this component/provider, you can. What's nice about this: the host can stop dealing with executing binaries — process lifetimes, the intricacies of doing it on Linux, Mac, and Windows. We can throw away a lot of our difficult aspects. You tell the provider to start, and then we don't really know if it started. When you restart the host, you don't have to restart all the providers — they're sitting there waiting. I'd love for the host not to execute binaries or containers — it just executes components. That's in the vein of host simplification. In the local development story, we can lean more into built-in providers (in the same process) and simple components that implement provider functionality — like implementing the blobstore provider using the file system, in-process. When you run in production, you orchestrate these providers using Kubernetes or Nomad. I need to pull up with Luke at some point, because he runs a really large set of wasmCloud applications in production and does it all with Nix — no containers. If we think of providers more as WIT-serving servers, it really simplifies what the host has to do and helps us get rid of one of the more friction-full pieces we have now. This isn't saying capability providers won't work anymore — it's the beauty of it: it just makes the provider's job simpler, because a provider is already a wRPC server. I'd love to do a little more spiking on this.
Massoud had one last comment before he headed out — that this change is probably going to make workload identity necessary. I don't know if it'll have to be there, but certainly if wasmCloud is talking to some arbitrary external service, workload identity would make that a lot more secure. This goes hand in hand with configuring the platform. Did folks have any thoughts on this one?
Taylor Thomas 1:05:59
Looks good, Brooks. I think we just need to make sure, when we figure this out, whether things need to register themselves with a server — are they globally available for a given wasmCloud lattice? When we talked about this before, I brainstormed a basic registration mechanism. There are multiple ways this could be handled, but we should probably have something so providers are known to be available and around. Or maybe not — maybe we don't need it. Just something to think about.
Brooks Townsend 1:06:36
Yeah. I hope everybody took me seriously that I'm trying to call out things we can do better without being super prescriptive — thanks for asking questions. For what it's worth, the majority of these changes we can probably roll forward as a new control-interface operation or a new mode of operation in the host.
Okay, actually, since I'm already working on the other one, I might steal this one too. I'm just going to steal every item on the roadmap. But don't let that stop anybody from leaving feedback. These are basically BRFCs that bring items out of triage, and then we make it happen.
Next: simplifying interface maintenance. We've spent a lot of time maintaining interfaces. Inside the wasmCloud runtime, we build in bindings and support for wasi:logging, wasi:keyvalue, wasi:blobstore, wasi:messaging (0.2 and 0.3), wasi:config, and runtime config. This makes them complicated to maintain, and it's not really anybody's fault — we wanted to give people functionality using the latest and greatest, even draft standards. When you're in wasmCloud, we want you using wasi:blobstore for a blob store and wasi:keyvalue for key-value — as long as those are what's being proposed through the various levels in the WASI cloud space, that's what we should use. It feels silly to have our own separate abstraction. But integrating into the host means that if something changes upstream, we have to maintain both versions. We knew that, and we're able to, but it takes time, and it's hard when we have many capability provider implementations built on these. The wasi:keyvalue interface has gone through draft changes; we support a different version of that interface to go over wRPC, and we have implementations for Redis, NATS, Vault, and maybe something else.
So moving forward, we should learn from this. We shouldn't build in more interfaces that are in draft, because they're likely to change, and we shouldn't put the responsibility on any interface to never change once it's a draft. Bailey called out the right set of interfaces to build in: WASI 0.2 interfaces, which are committed; we'll do the same with WASI 0.3. Those are very resistant to change, and if there's a breaking change we have adapters. We can also build in things that are wasmCloud lifecycle — wasmCloud component, wasmCloud lattice bus — those we control: the interface, versioning, backwards compatibility. In general, there's no reason we can't lean into our custom interface support. The wasmCloud Postgres provider is an example — you'd have no idea it wasn't built into the host. We should lean into that as much as we can. The burden of compatibility goes on the wRPC server side, which is a lot easier to control than releasing a wasmCloud version that supports wasi:logging without a version and wasi:logging 0.0-draft.
Taylor Thomas 1:12:28
Brooks, the only thing I'd say there is wasi:config feels like one we shouldn't rip out. I don't care if we have to replace it with our own wasmCloud config again, but we should definitely have a config thing around for components. The other ones I'm all game with ripping out, because they were a pain to manage — go, not embedded in there, but on the wRPC server side. But wasi:config feels like one we should keep around.
Brooks Townsend 1:12:57
Sounds reasonable. I'd love to think of ways we can make these plugins too — you can provide your own implementation of wasi:config. The intent is definitely not to take away these capabilities; it's to decouple them from the host lifecycle. But calling out config as a little different makes sense.
Brooks Townsend 1:13:42
This next one's a little stickier: reducing host responsibility and API surface. We've talked about this before — it came up around NATS earlier in the year. A host now is responsible for a lot: managing processes on the local OS, reconciling its own state with a global NATS JetStream bucket, writing state to that bucket so it's socialized among other hosts. I'd really love to simplify some of these things. We've already started in the wasmCloud host. What I'd like the host to do is start with some set of configuration — maybe the providers it should run, or the OTel endpoint to connect to — and then sit there and wait for a scheduler or orchestrator to tell it what to do.
I have a diagram that I hope helps inspire what this could look like. This is the same one I brought up when we talked about the tight coupling of wasmCloud to NATS: when the host starts, you have to connect to a NATS JetStream bucket to get data and config, subscribe for control-interface operations, request secrets, check with the policy engine, publish events, and so on. It's all there for a reason — I'm not saying it's bad. But what we have now are light abstractions: instead of "give me the config from NATS," the host uses an abstraction that says "give me this piece of config," and there's an implementation that fetches config from NATS. Or "here's an event that happened — publish that," and you can hook into it however you'd like. The theme is moving toward the host being less tightly coupled to specific implementations and more embeddable inside a different system that wants to dictate how the host gets information.
To tie this together in a more specific straw man: we can have the wasmCloud host library, essentially as it is today, embedded inside the wasmCloud binary you run. All the host is responsible for is basic configuration — log level, where to write standard error logs, where to emit traces/metrics. It should wrap our runtime — Wasmtime, but our opinionated version of it to execute components — and support a wRPC server API to talk to capability providers. What would make this a lot simpler is if the host's control API is at the granularity of "run this component — here's all the info you need: its config, links, secrets, the component bytes." If the host is only responsible for taking that specification and executing it, it doesn't need to reach out to a secret store, source configuration, or execute a provider. The whole theme is: some supervisor/scheduler — wadm, Kubernetes — tells the wasmCloud host "run this," and the host could say "no, I couldn't," but that's it. It doesn't need to do what it does now, where wadm takes a whole manifest and breaks it into individual commands sent to all hosts everywhere.
A really cool way to support this — down at the Rust trait level, so take it with a grain of salt — is that when the host starts, it could register with a scheduler/control plane and send a host heartbeat: "I'm alive, can somebody help me do a thing?" That might be wash locally — wash sees the host started and calls functions directly on it: "here's your component, go start the thing." It could be a gRPC server connected to Kubernetes, where Kubernetes says "go start this component." It could be a direct subscription to a NATS JetStream bucket watching for component specs. I'd love a default mode for this supervisor — maybe a NATS bucket mode, maybe loading from a local file. If we separate these concerns to the supervisor layer, the host core becomes really small and embeddable — we can put it in wash. By outlining the different responsibilities in wasmCloud's architecture, we get a more flexible system, because the host core is responsible for so little. Does that make me sound crazy, or is it a decent straw man for moving forward with reducing host responsibility?
Brooks Townsend 1:22:04
I'll take that as it made me sound a little crazy. Oh, nice — I got a thumbs up. I figured making things simpler wouldn't be controversial. Lucas, you said it sounds good — much of that behavior is pre-wadm.
Lucas Fontes 1:22:41
Yeah, pretty much. The fact that the host is doing a lot comes from the fact that it was possible to stand up a host and interact with it directly. But the moment we always have a scheduler present in the setup, the scheduler can take a bit more responsibility.
Brooks Townsend 1:23:03
That totally makes sense. We'll need the most simple version of this for an edge deployment — where you could just throw a configuration file at a host and say "here's all the stuff you have to run," no runtime scheduler. But leaning into this model makes host responsibility a lot simpler.
Brooks Townsend 1:23:37
I'll link that Excalidraw. Nothing set in stone, but simplifying the host would be super nice. We talked about this a while for the control interface v2 endpoint, so I think we can start working toward some of this sooner rather than later.
Okay, one more I wanted to talk about, and it's interesting — I'm really curious what people think. This is intentional distributed networking, related to the ability for components to invoke each other in-process. One of the magical aspects of wasmCloud is seamless distributed networking: whether you run two components on one host or on two hosts, they talk to each other the exact same way, because every component-to-component call happens over wRPC, with NATS as the transport. We do that for wasi:keyvalue, wasi:http, wasi:blobstore — things you maybe wouldn't expect to be a distributed call — but we make it work because of this wRPC model. That's really cool, and it's a little scary when you configure this in production, because it's hard to know when all your calls are going over a transport. If you use the pluggable nature of wRPC to change from the NATS transport to a TCP transport, your routing semantics change — you connect to a TCP port, which may not have the same properties NATS does, like queue subscriptions and routing.
What I'd really like: lean in on the ability for components to call each other directly if they're on the same host, which makes this a lot easier. But when you make a distributed call, you should have the ability to handle errors at the transport level, and you should specifically need to opt into doing a component-to-component call over a distributed network. Today in wasmCloud, if you call a wasi:keyvalue endpoint — increment this value — and there's no provider on the other side, your component will panic; you can't recover, because the component expects an implementation in the host and the interface doesn't have a result we can act on. So we made wRPC errors to compensate. If you take any custom interface and make the return type a result with your desired return type and a wRPC error as the error type, you can handle these transport-level failures in your component — no panic. Maybe NATS wasn't connected, or you didn't have the proper link configured. This is awesome for custom interfaces and compatible with composition, but it's not compatible with wasi:keyvalue — they're not going to build wRPC error into that interface.
So I'd love a mode for wasmCloud where you can opt out of distributed networking and ensure everything's kept locally on one node if you want two components to talk to each other. And if you're doing a distributed call, you have two options: use an interface with wRPC error so you can handle network failures and explicitly opt into wRPC, or use an interface like wasmCloud Messaging if you want the NATS semantics of going from one component to the next. I don't know if these alternatives cover every scenario, but I want to preserve wasmCloud's awesome distributed networking — I just want it to be intentional. I don't want to force NATS transport mechanics on folks, because often when they come into wasmCloud and ask "how does my one component talk to another?" we say "wRPC and NATS," and then "how does the routing work?" and it's "go learn NATS and come back." The real goal is to make deployments more predictable — to give a platform engineer who's placing components on particular hosts more control over how the distributed communication works.