Transcript: whamm Wasm Instrumentation and the Component Model
wasmCloud Weekly Community Call — Wed, Jun 25, 2025 · 45 minutes
Transcript
Brooks Townsend 03:33
Okay, well, why don't we go ahead and get started. Elizabeth, I'll make you a co-host so you can do the thing. I'll just do a quick spiel and share my screen, but then I'll pretty much hand it over to you. Alrighty, let's do it. Hey everybody, welcome to wasmCloud Wednesday, for Wednesday, June 25. Let me take a quick peek at the agenda for today. Essentially, what we've got is marked as a discussion, but I think there might be a demo — demo and discussion. I wanted to welcome a new community member to the wasmCloud community. Elizabeth, I think you've been around for quite a while in the Wasm ecosystem, and just recently you've been getting a little bit more involved in wasmCloud and on the Cosmonic side. Elizabeth, do you want to do a quick intro of yourself — your involvement — and then what you want to show with your project?
Elizabeth Gilbert 04:50
Yeah, sure. So I've been around in Wasm for about three years now, because that's when I started my PhD — I just finished my third year at Carnegie Mellon doing research on WebAssembly instrumentation. What I mean by instrumentation is the ability to instrument some programs with some logic that enables you to do dynamic analysis on your code while it's running. Those can be things like branch profiling, or building out call graphs or flame graphs — things like that are primarily built using instrumentation. So I've been working on this framework, which has a lot of different components to it. It's called whamm, which is a fun name — it's really memorable — and what it is is this way to instrument your code. You write your code in a DSL, and the DSL is inspired by DTrace, if anyone's familiar with that. You have these high-level events that you want to hook into in your program, and there are two different strategies it can use to instrument a program.
You can either instrument with static bytecode rewriting, so it'll look at your Wasm bytecode, inject some logic at those event locations wherever they happen in your bytecode, and then you'll have this now-instrumented program that performs your dynamic analysis as it executes. Or you can instrument through dynamic instrumentation, so you can interface with the engine in this new interface that we built out on the Wizard research engine, if anyone's familiar with that. There's the standalone instrumentation module that expresses the instrumentation, and then the engine loads this module as a kind of side thing that's going on, and as events occur dynamically in your program, it'll fire those callbacks in your instrumentation module. So the instrumentation module itself is monitoring what's going on in your dynamic program.
I can show some of what's going on by sharing my screen, and we'll see — sometimes demos get a little weird. Fingers crossed this one doesn't. Okay. So I have a couple of demos. I think Brooks actually just sent a link to the repository — it's just under this demo folder. There are two different demos; this one's simpler, it's literally just counting the number of calls that happen in your program. There's this really simple, handwritten Wasm application that does nothing interesting, but inside here, like I said before, you have these high-level events. This is the match rule: I'm looking in my WebAssembly bytecode for any call opcode. When I see a call opcode, I want to insert some logic before that occurs. I only want to instrument calls where the immediate is two and the first argument to my call is zero. That further predicates my match, constraining it to whatever event I'm really looking for. With Wasm semantics, the immediate to the call opcode is the call target — function 0, 1, 2 — so anytime I'm calling that function, I'd be instrumenting this location.
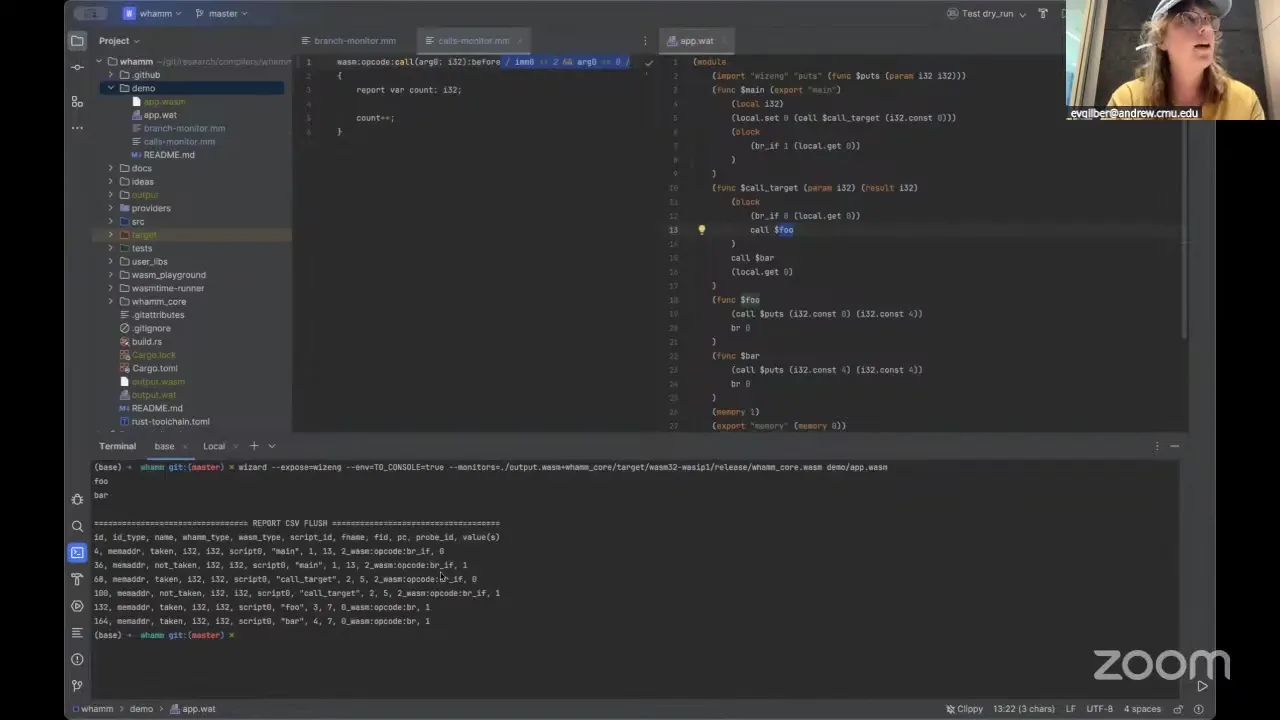
To run this on my application, I have a little CLI, which is nice. I can also use the CLI to help me build out my script. We have a couple of different options. To instrument, we use the instrument command. I can also pull information through the info command — say I want to get the bound variables at the rule wasm:opcode:call:before. That helps me see what's in scope, because there are random variables showing up in this script that I haven't defined anywhere, and that's because different parts of the match rule bind variables when they come into scope. So the Wasm provider gives me things like fid, PC offset, and the function name — all the things that get defined when I'm traversing my program trying to find these events I want to instrument. If I want to constrain this to only the Wasm opcode calls inside fid zero, I'd put fid == 0 in my predicate. The immediate0 is the immediate to the opcode at index zero — for a call, it's the call target, fid — and then arg0. The reason it says "unknown" is because you don't know the type of a call until you have the program; it's program-agnostic until I tie it to a program, and that's where the type information comes in.
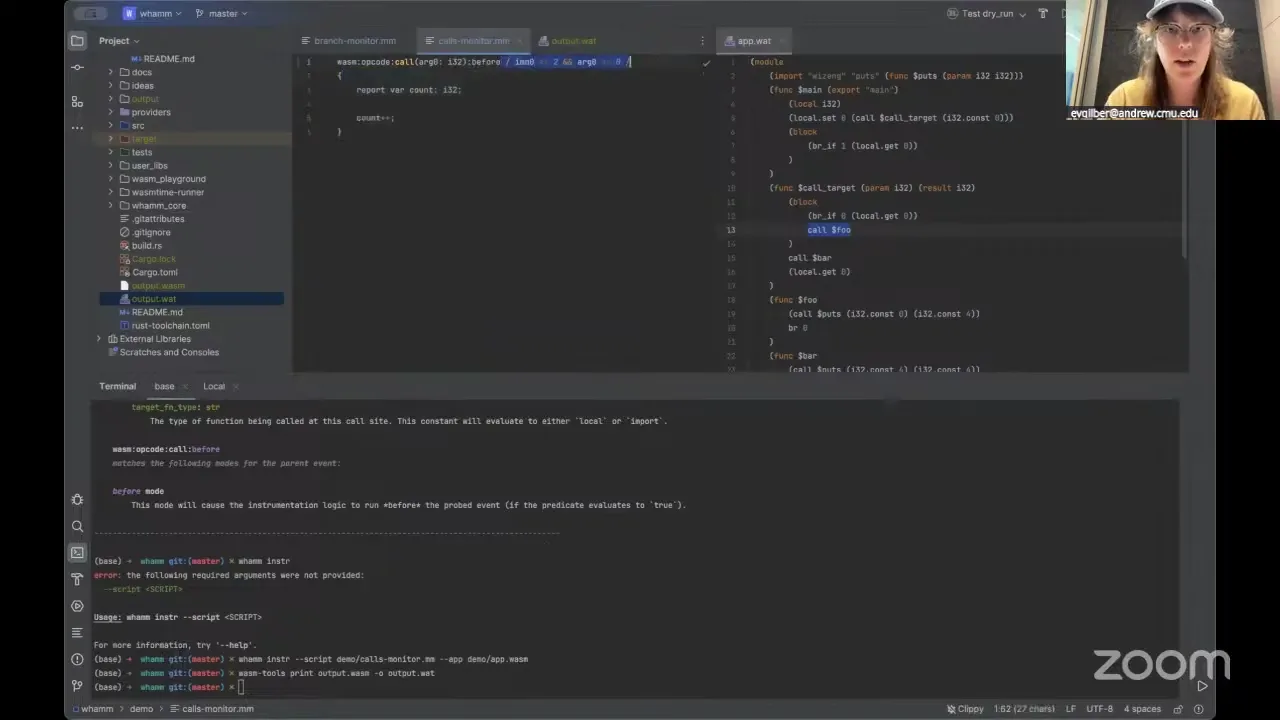
So that's the high-level description of the calls monitor. If I want to actually run it, I'd use my whamm instr command, which requires a script. I want to do bytecode rewriting, so I'm going to take this application Wasm file and instrument it. Well, it didn't die — that's a good sign. By default this puts the instrumented application to output.wasm. I'll print out my Wasm bytecode to a human-readable WAT.
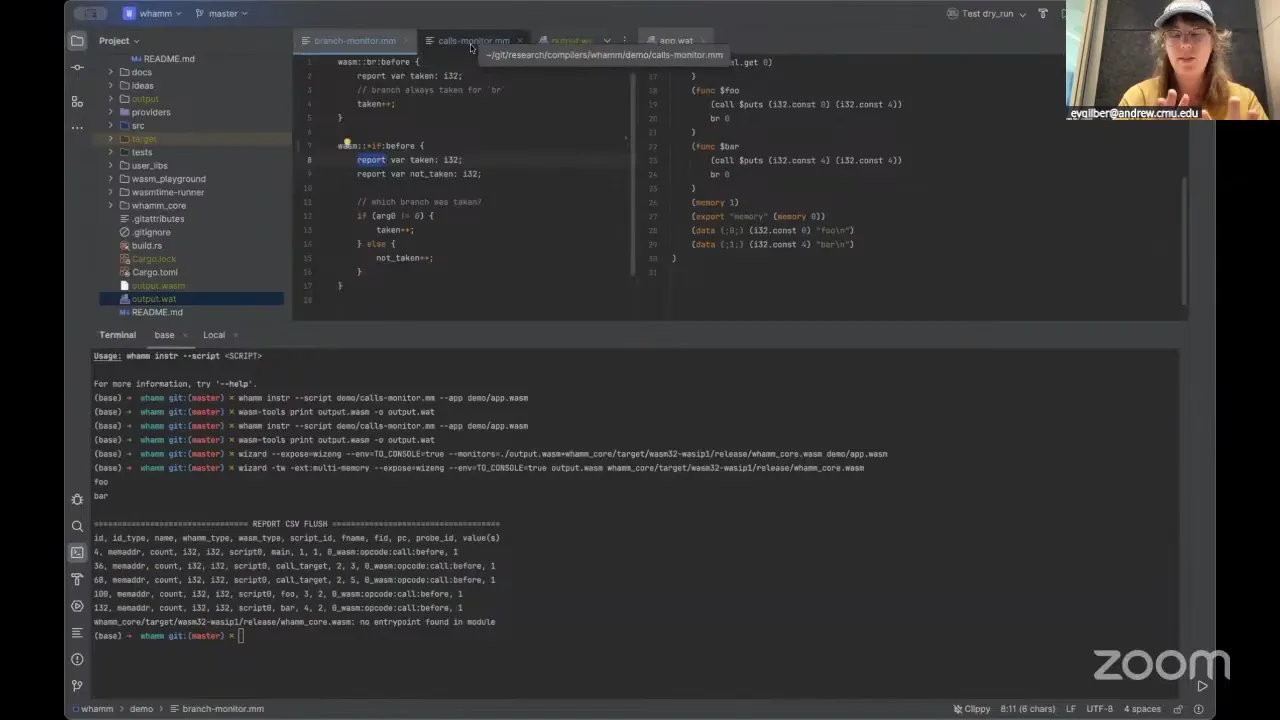
So now we have an application, my-app.wat, that has been instrumented with a bunch of stuff in it. It's found all the calls that matched my event definition and inserted this count incrementation. Where did it increment? I wonder if the arg wasn't zero — okay, we're just going to remove that. There we go. It must have been on the predicate, something wasn't actually activated. So when it does a call foo, it has all of this stuff injected beforehand. Before, it was just br_if and then a call, but now it has all this other logic doing my increment on this count variable. I can read this to you, but it's not that interesting — just trust me that it does an increment. If I run it — it's a really long command — I'm running this on Wizard. This environmental variable is for the library I'm using to do more sophisticated stuff; in this case it's just printing.
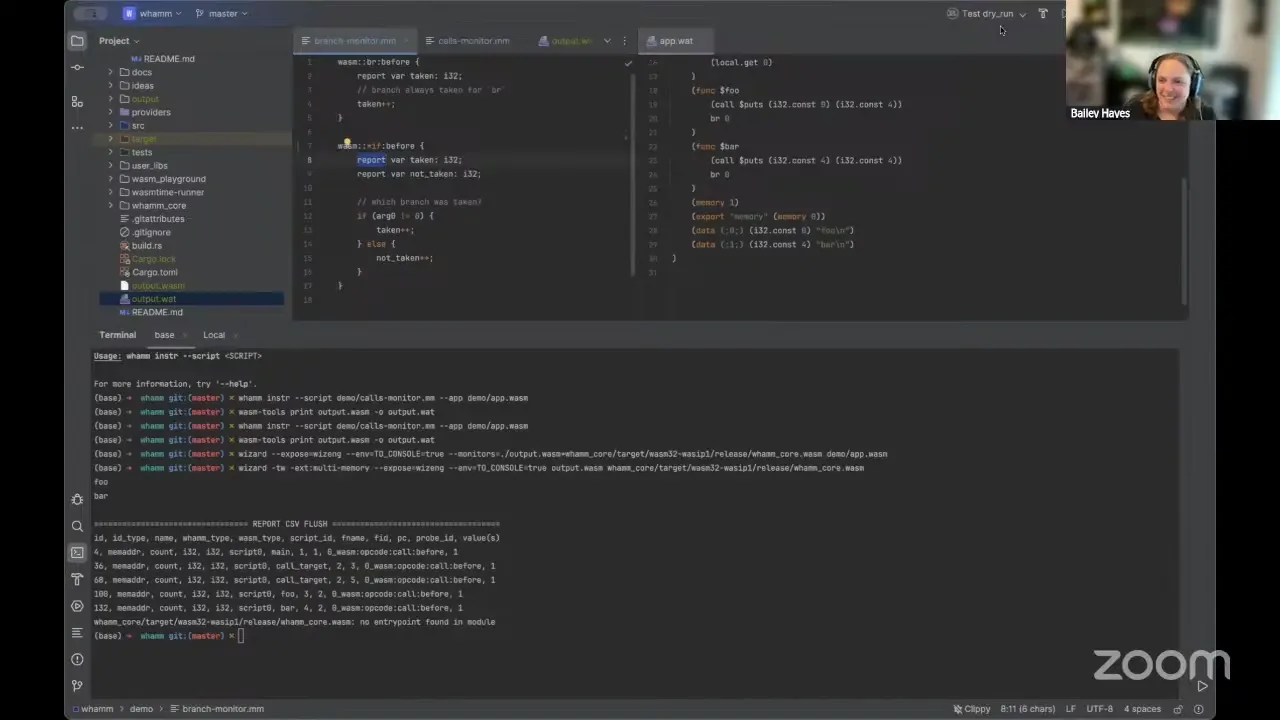
Oh wait, this is the dynamic one — hold on, I want to do the bytecode rewriting. There we go. I'm activating multi-memory to support this import; this is that environmental variable I mentioned, it's running the output.wasm, and I'm adding in this library to do more sophisticated stuff. If I run it, it's printing out the probe state for all the probes that were injected — all the calls that were instrumented. I have one report for each, the number of times that count was incremented. In this case I guess I reached all of the counts one time. I don't know how much detail y'all want — I can show you the branch monitor if you're interested. There are more features in the DSL too, like globbing: if you want to match on multiple events, you can use a pattern, so it'll match on all the Wasm opcodes matching *if — the if opcode, the br_if opcode, those types of things. The report keyword tells it to flush at the end of program execution. I'm trying to make it high-level and intuitive, and this is just the bytecode-rewriting side.
Bailey Hayes 16:59
Cool. Thank you so much, Elizabeth, for sharing. Anytime we get into this, it's a good day. How much have you talked about some of the things you can do with this? Personally, I'm really excited about the idea of being able to add logging and observability tracing after the fact — I don't have to go edit somebody else's code to get logging for what type of WASI calls they're calling, and being able to say what they're using the socket for. Are they actually creating lots of different sockets? How are they interacting with the system? That's going to be really powerful, at least for observability. But I bet you've thought of a lot of other things I'm not calling out.
Elizabeth Gilbert 17:55
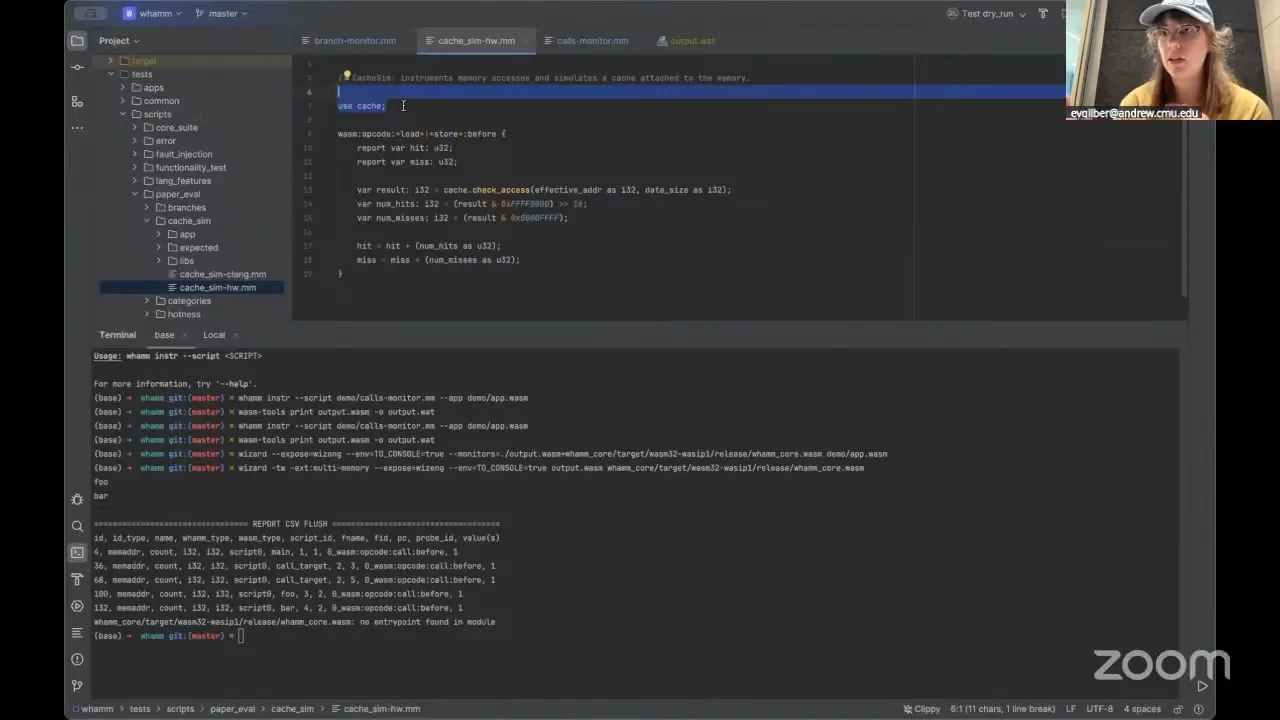
Oh yeah. Another cool thing we built out this past month was a cache simulator. If you want to see what would happen if you ran this type of cache on your program — since in whamm you can use libraries — you can use a cache library that you just provide as the Wasm module, and then call into this library, and the library does more sophisticated things for you. This is an entire implementation of a cache. This helps a lot with scope creep in whamm as well: the DSL does what it's good at, it helps stitch together your program and your logic and pulls out the program state you need, so you can really do whatever you want just by providing a really simple interface with this library. So you could do the logging you're talking about, where you pass the program state that whamm has readied for you to your library, and then your library does whatever you want. There are a lot of different sophisticated use cases that can happen, and as we gather more I can add more expressiveness to the DSL to make it not look crazy.
Bailey Hayes 19:38
Oh, this is so great. People building with wasmCloud are usually building out platforms, so I'd imagine this is going to be one of those tools in a lot of platform engineers' toolboxes, where they want to be able to instrument the types of components running on their system. They'll likely be doing this from a CI side of the world, but as you mentioned, you were able to do this with Wizard, so you can also potentially plug this in at runtime.
Elizabeth Gilbert 20:13
Another thing I'm trying to get working: right now this is very low-level, which you probably noticed — instrumenting Wasm opcodes — but it'll be good if there are higher-level, abstract events to make it more usable for non-low-level people who read WAT. Or if you wanted to make source-code events: if you want to instrument some location encoded in the DWARF, it'll be really powerful to expose those types of events to users, rather than it always being this low-level framework. If we can build on top of that, that's really awesome.
Bailey Hayes 21:03
And that's where I'm really excited about your work for adding component model support. Right now what you demoed, obviously, was with WebAssembly modules, but with components you'll have higher-level metadata that we can key off of, and it'll hopefully be a little bit more user-friendly even just by adding that one feature.
Elizabeth Gilbert 21:23
Yeah. So whamm on the backend uses Orca, which is this other Rust library we've been building, and Orca has the ability to instrument components. I know Victor — I don't know if he's on here — was using that to do some type of instrumentation. It's cool to see that this is starting to get people excited about doing instrumentation and building out a really nice suite of tools and frameworks. It's just going to make it better.
Bailey Hayes 22:03
I saw a wild Victor appear for a second there. Hey, Victor.
Victor Adossi 22:10
Hey, yeah, I just wanted to note that what I was working on was dynamic instrumentation. There was a little bit of work that had to be done to prevent basically all the optimizations that your code would normally do — like if you have five functions, they get inlined in a language like Rust. There are a lot of paths to getting automatic instrumentation working right at the function boundary, and that was what I ended up working on. This is another way there, which is really awesome.
Bailey Hayes 23:01
Cool. Anybody else on the call have any questions for Elizabeth? I'm hoping you'll update us as your work progresses and we can see some more Wasm instrumentation.
Victor Adossi 23:18
Oh, another group of people who might be really interested in this is the original crew that worked on DTrace. I know there's a whole bunch of them over at Oxide and places like that — they'd probably be really interested to see DTrace get revived, or its ideas carried on in a new platform.
Elizabeth Gilbert 23:41
DTrace Rides Again. Yeah. Did you have a question, Brooks?
Brooks Townsend 23:48
Yeah, I think I saw this in your reading, but just to ask — since most people who work in the wasmCloud ecosystem are dealing with components, does this tool have support for components? Is there any limitation there?
Elizabeth Gilbert 24:06
So part of what I'm going to be doing in the next couple of weeks is getting whamm working with components, because it does — there's no technical reason it doesn't. I just haven't added that yet, because it uses Orca on the backend, and Orca can do component instrumentation, so I just have to expose it in the DSL. It'll be nice to have access to actual components instead of me trying to figure out what a component really looks like, because I've been mainly working with modules this whole time. If you want to instrument a specific module within a component, what's the most expressive, intuitive way to say that in the whamm script to constrain these matches in the predication? I'll be able to expose the functionality pretty easily, but making it nice in the DSL may take a little bit more time. I can craft that as I start working more with them.
Brooks Townsend 25:15
Awesome. That's super cool. Wasn't even a plant question — I didn't know you were working on that. I can't wait to try to do fun things with this, with the components that we have for wasmCloud. Should be super fun.
Elizabeth Gilbert 25:34
Yeah, that'll be awesome. I got a blobby working an hour ago, so I'll be playing around with blobby.
Brooks Townsend 25:42
Little blobby tables. Awesome. Do folks have any other questions for Elizabeth? I did put a link to the repo in the chat, but I'm sure we'll bring it back up at some point if y'all want to take a look at the code.
Elizabeth Gilbert 26:10
Yeah, and as people start playing around with it, you'll probably hit bugs, and I will react to them and get them fixed — just as a caveat.
Brooks Townsend 26:23
Yeah, Elizabeth, once you add component support, if you want people from the community to bash on it or try it out, I think if you drop a message in the wasmCloud Slack, people probably will.
Elizabeth Gilbert 26:36
Yeah, sweet. Thanks.
Brooks Townsend 26:43
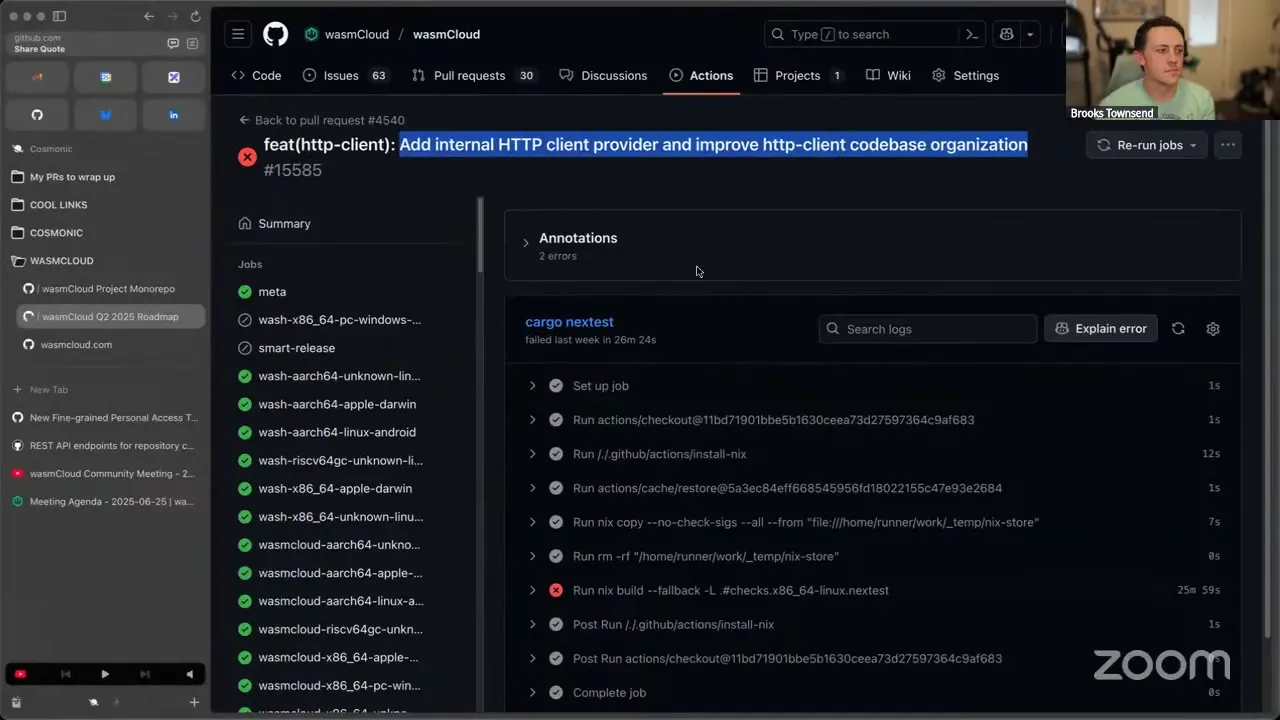
All right, folks, thanks. Well, that was definitely the more exciting part of today's community meeting. On to the next part, which is maybe slightly less fun: I wanted to talk a little bit about pull request bankruptcy. I tried to be a little cheeky with this, but really what it means is we have quite a lot of pull requests out in the wasmCloud monorepo — the primary repo — right now, many of which are either completed, ready to go in, or just stuck on a small integration test unrelated to the PR. We've been sitting in that state for maybe a little too long. I'll call myself out for the built-in HTTP server tests: when I added path-based routing, I added a test that's flaky. I don't know why it shouldn't be, but it is, and that holds back PRs that are unrelated to it. That's pretty frustrating, especially when we have folks like Aditya, who added a cron-job capability provider and support for constraining components by memory limits; community members like rebel, implementing fixes from the roadmap; and Massoud, who added the NATS Blobstore provider and the built-in HTTP client, both of which I believe are functionally complete and approved.
I really feel like we've been going for a little too long in this mode, getting blocked by some of these tests or CI. So I'd like to declare PR bankruptcy. By that I mean I'd like to spend some time this week taking a look at essentially all of the PRs out there. For a draft PR I opened in May, I'm probably going to either shape it up or close it to clean up the backlog. If there are any Dependabot changes based on failing tests, we can pull them into one PR. And for pull requests like the HTTP client provider that are failing on a test because of HTTP server, I'd like to propose that we disable that test, file a bug report that the test is flaky and fails on unrelated things, and merge it in. I don't want to take a drastic step like disabling all merge protections and force-merging everything and figuring it out later — that sounds bad. But I'd really like to spend some maintainer time to get these PRs in, because it's starting to stack up on the burden of the people maintaining the project. Especially if Dependabot bumps clap and then the built-in HTTP client test fails — it already spun CI for 30 minutes to get to this point. Most folks here are maintainers approving these PRs and saying, "Ah, that test was weird, let's rerun it," then it goes into the merge queue, fails there, and you have to re-queue it. Does anybody have any concerns with this approach? Are there any pull requests out there right now I should be concerned about? I plan on taking a look at each one, seeing if a test is failing, whether the functionality was affected by that PR, and if it's not, I'm going to file that as a bug and try to deactivate it.
Liam Randall 31:37
So Brooks, what's the total list — the enumerated list of things we want to disable for this?
Brooks Townsend 31:48
Okay, I don't have a full list, but I do know the one I'd certainly like to disable is — I'm not sharing anymore — this is the pull request that adds the built-in HTTP client provider. I'd like to double-check that nothing affected the server code in this, but this built-in HTTP path routing, the built-in HTTP server, is the one.
Liam Randall 32:30
I've wanted to eat that thing into the sun for a long time, because it always fails randomly for no reason and I don't get it. So yeah, okay, I'm all on board. I just want to make sure — you probably just say, "here are the tests," in a single PR, just go through and we say, "here are the tests for disabling," put them in there, and then open the bug report for it. Because, yeah, those are gnarly.
Brooks Townsend 32:56
Yeah, I know it's that one. I'm not really sure if there are others triggering this. If there are legitimate failures in CI — like the PR isn't passing a cargo build — then I'm not force-merging those. But yeah, maybe that's the best way to expose that list, Taylor: just open up a PR — "here are the tests we're going to disable, here's why, and here's the follow-up issue."
Liam Randall 33:27
Yeah, I think that'll make it clear. I'm not super worried here; I'm just trying to make sure we don't lose anything in the shuffle. For that one we're just going to have to comment out the test, or add an ignore to it. And actually, Massoud just gave a good suggestion too. I think that might be a good thing to send out, maybe in Slack and also from this meeting: just say, "Hey, if you have an open PR and it's been blocked on tests, can you check if it's related? If you're fairly certain it's not related to the PR's intent—" and then that should lower our burden, especially since a lot of the ones out there are from maintainers. So we comment out when we need to, label any checks we've disabled in the PR, and put that in the issue, so it's in both places and people can see the history when we go back and check. And we talked last week about changing up some of the way we're doing the tests, so it'll probably get addressed through that as well.
Brooks Townsend 34:42
I think that sounds like a great suggestion. It seems pretty fair to put it on the original PR opener. I honestly just kind of feel bad that it's possible some of these changes have been affecting people who spent their open-source credits and time to contribute a thing. But I think that sounds great.
Liam Randall 35:08
I get the feeling, Brooks, as someone doing said thing with open-source time. Brooks got my rage post — I was going through the whole "I did this, then I kicked this, then I had to kick this test, then I had to replace this, then I had to redo it after it failed the merge queue." So I get it. But I think we'll get any of the ones that aren't — I think we just say, especially maintainers, please go check your PRs and let us know. That'll make it easier on the rest of us, and then we can go through the rest of the PRs and take a look.
Brooks Townsend 35:43
Yeah, that sounds good. Okay. What I can do is put out a message in the wasmCloud Slack — pretty much everybody who's contributed something in the open PRs is in there. So I can tag some folks, or tag them in GitHub, or do both, and get folks to take a look at their PR to see if it's being blocked on tests. And — sorry, Taylor, was it you or Massoud? — the suggestion to add another commit to the PR to ignore or comment out the test, or a separate PR?
Liam Randall 36:29
I was saying separate PR, and we can rebase the stuff on that to unblock things — especially because now that GitHub has the rebase button instead of just the merge commit, we can hit rebase and not have to make people do it.
Brooks Townsend 36:47
Yeah, okay, that sounds good to me. My whole goal here is, one, to get in a lot of these PRs that have been outstanding, and two, it gives us a lot more ability as maintainers to give attention to the new issues and pull requests coming in. We have — well, I don't know who f4z3 are; Jacob has contributed a couple things on the current roadmap; Giancarlo came in and fixed an issue with the policy manager — and it's just been lost in my GitHub inbox because I keep rerunning tests and then getting mad.
Liam Randall 37:38
That's honestly the biggest thing for me. I have so many things in my inbox that if I go back and run a test, and then it doesn't merge, it gets lost really easily.
Brooks Townsend 37:53
Sorry — I asked if anybody had any concerns and then I just kept talking. Does anybody else have any concerns or suggestions? All right, if you're on the call or listening — hello, everybody home — consider this your official ask to go take a look at the PRs you have open. If there's anything getting blocked by a test or something that's not because of your contribution or control, let us know. We can file issues for it and get those resolved one at a time and help get the contribution done.
Massoud 38:44
Quick question, Brooks. Because you and Taylor talked about a new PR — do you want us to validate and then issue a new PR, or just comment on the ticket and say that I have validated and it's not related, or is related, or whatever?
Brooks Townsend 39:05
I think, if it's not too much work, I like Taylor's idea to have it as a separate PR, so we can see in the PR list "here's where we disabled this test" and have that linked in the bug issue. That would, of course, require that people who want to disable a test go back through and rebase onto main. I hope that wouldn't be too big of an issue. I slightly prefer the separate PR for trackability. But, Taylor, do you have any more to add?
Liam Randall 39:46
I can go open an issue right now. That's what I was thinking — we can tell everybody "here's the issue," and we're going to track everything there. It can just be a meta issue that we close, and we can fully compile it at the end. We just open a tracking issue and say, "Okay, if you see a test that you're pretty sure is just flaking and causing issues and doesn't have a thing, please comment it here," and then we drop it in there.
Massoud 40:15
Should we do this with a new PR, or just comment on that issue? Because, again, what I'm asking is — for mine, for example — should I close the existing PR and then issue a new one, and also comment on that mega issue you want to open?
Liam Randall 40:37
No, I don't think we want to close. I think what we do is: let's give this a week, have everybody comment in, and then open one PR that basically closes that issue to disable the tests, and then everybody can rebase on it once it's on main. That's my thinking of the order here. But does that work for people? I'm honestly not married to the idea — it's just throwing out what seems like it might be an okay process. Okay, I'm literally going to go do that right now.
Brooks Townsend 41:20
Awesome. Yeah, thank you, Taylor, I appreciate that. All right. Well, thank you, Taylor, for creating that issue, and we'll get on it. I do want to open up one more discussion item that I forgot about: I wanted to send a warm congratulations to Lachlan — longtime TypeScript maintainer, turned CI maintainer. Lachlan has contributed a ton of our CI pipelines and made a bunch of changes, and so he's now able to help out with some of the CI reviewing. And I wanted to extend a warm congratulations to Massoud for becoming a maintainer of — I believe capability providers is the specific area.
Liam Randall 42:28
Right there. You found it.
Brooks Townsend 42:31
Yeah, capability providers. This is an open-source project — the titles are made up and don't matter, whatever. But what really matters is how much Massoud has contributed to the wasmCloud project. As we just called out in this current pull request backlog, he's contributed the NATS Blobstore provider and the built-in HTTP client provider, and generally has been offering fantastic feedback and thoughts across the wasmCloud ecosystem for quite a long time. So thank you so much, Lachlan, for stepping up, and Massoud for being a maintainer and spending your time to be here and help out. It's my favorite part of working in open source for sure. I think we have about 15 minutes — if you've prepared your speech, you can go ahead and do that now. It's okay if we need to run over.
Massoud 43:36
Well, I just want to thank everybody. Again, this is community work, and I'm happy to be part of the community. I know that I labor a lot, so it takes quite a bit for people to just listen to what I say, and I appreciate that you're extending this opportunity to me. I'll try to be a better maintainer, so if I didn't do well, please let me know and I'll try harder.
Brooks Townsend 44:18
No, Massoud, you're doing awesome. Thank you. And thank you for dealing with my shenanigans — actually doing a maintainer speech.
Liam Randall 44:36
I only give speeches if I have a trophy I can hold while I'm doing it — like the various movie awards.
Brooks Townsend 44:48
All right, folks, I think that's probably all for today. Thank you so much, Elizabeth, for coming on and doing a demo and introducing whamm to everybody. It's always cool to see more Wasm projects come into the general community. Thanks everybody for coming out and hanging out for wasmCloud Wednesday. We'll see you next week — next week's not a holiday. See you then. Bye everyone, have a wasmCloud day.