Transcript: Hono on Wasm, Component Saturation Metrics & the NATS Statement
wasmCloud Weekly Community Call — Wed, Apr 30, 2025 · 103 minutes
Transcript
Brooks Townsend 4:48
Hey everybody, welcome to wasmCloud Wednesday for Wednesday, April 30. We have a pretty good agenda for you today — should be fun. We've got a demo, a couple of discussions, but there's something even more special than our planned demo, which is an unplanned demo that we'll get into in just a minute. So before we get onto the agenda for today, Milan — you've been active in the wasmCloud community for quite a long time, you've been in a community call before, maybe a little while ago. Would you mind doing a quick introduction, and then just talk about how you found us?
Milan Raj 5:40
Yeah, absolutely. Milan Raj, I'm in Austin, Texas, at National Instruments — Emerson test and measurement, most recently. I've been playing with WebAssembly on the front end for a long time. We make a graphical programming language and compile out to web applications — WYSIWYG drag-and-drop UIs for engineering applications — so we've been playing a lot on the front end with WebAssembly and experimenting more with using WebAssembly on the back end now that we have P2. That was a nice, exciting breakpoint. So what I've been doing for a couple of weeks is trying to see how much leverage we can get from existing libraries and frameworks within Wasm components. I've been focused on TypeScript specifically, and got pretty far. I was humble-bragging in the Slack about how I can render JSX components with JCO, so I got called out on it and put up my example, which I can share today. I could jump right into that.
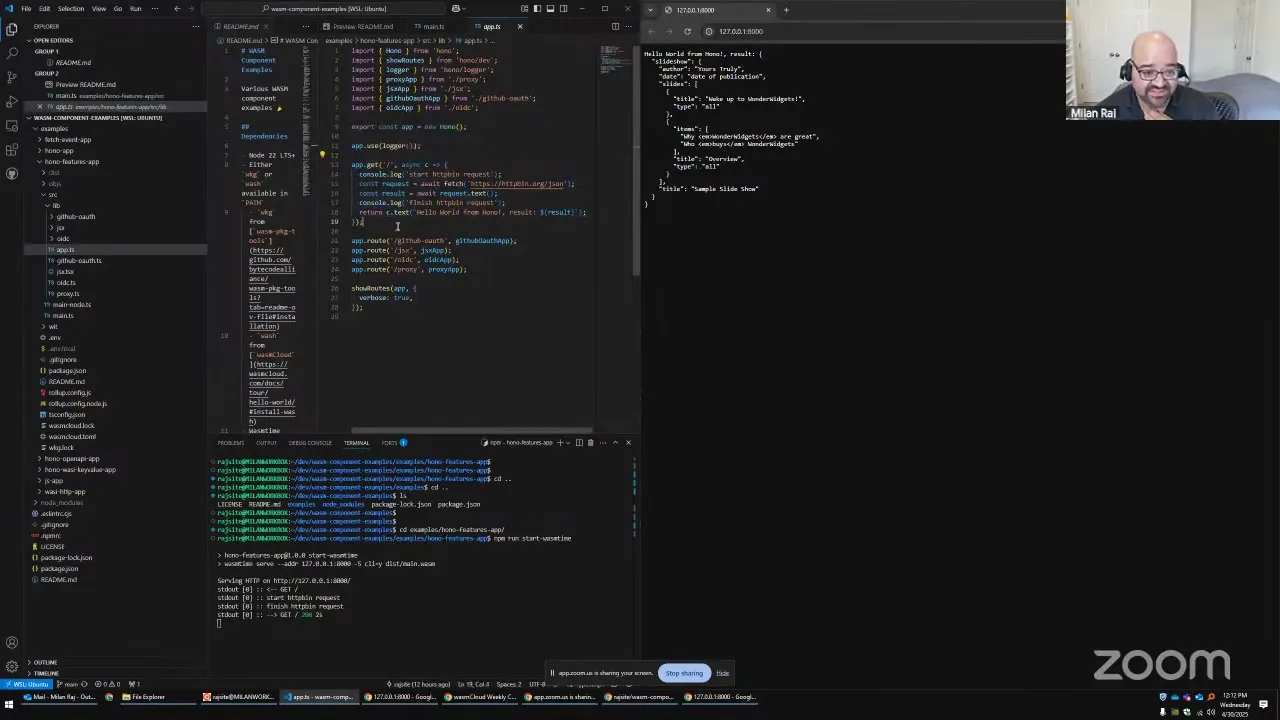
Milan Raj 6:48
So the repo I put together is hosted up here — wasm-component-examples. I was just in the JS community meeting where the library I was experimenting with, Hono, came up a couple of times too. Fermyon's blog has an example of using Hono with their JS SDK, and wasmCloud has an example of using Hono pushed a couple of days ago, which I just saw. There's a pattern I'm using in mine that we might want to update in there — we could actually simplify the adapter code that's needed down to a single line, which is pretty exciting. And in the Bytecode Alliance there was a sample project pushed there too, using a different router. Very similar ideas: we're able to leverage more and more things right from the JS ecosystem to make Wasm components with JCO and TypeScript.
The direction of this example is exercising more of the advanced features of Hono. The readme is pretty straightforward — there's a very new Node version notice, the out-of-the-box experimental TypeScript support, and the new node --run flag instead of npm run, which saves you 300 milliseconds. You'll need either wac or wash in order to fetch dependencies — it'd be great if that were part of JCO out of the box — and then Wasmtime, wasmCloud, whichever runtime you want to test against. One big thing I did for structuring the examples is that you can run them both in Node.js and with Wasmtime or wasmCloud, to help with the development workflow. I can set breakpoints, step through, and debug in both.
So I'll jump into the fancier demo, the Hono features app. If you look at the source, that adapters folder we had in the other spot — turns out you can replace all of that content from the wasmCloud Hono demo with app.fire. What app.fire does is register everything for you. Instead of calling into the WASI HTTP API surface area and building up objects to represent request and response, it's just calling into the fetch event feature that's part of ComponentizeJS, as a nice high-level wrapper. So you can code-golf it down to four lines, or even one line. And the nice thing is the Hono app itself comes from this import lib app, and I can use the same one from the Node wrapper — pull in that same import and have the whole application runnable in Node or as a component.
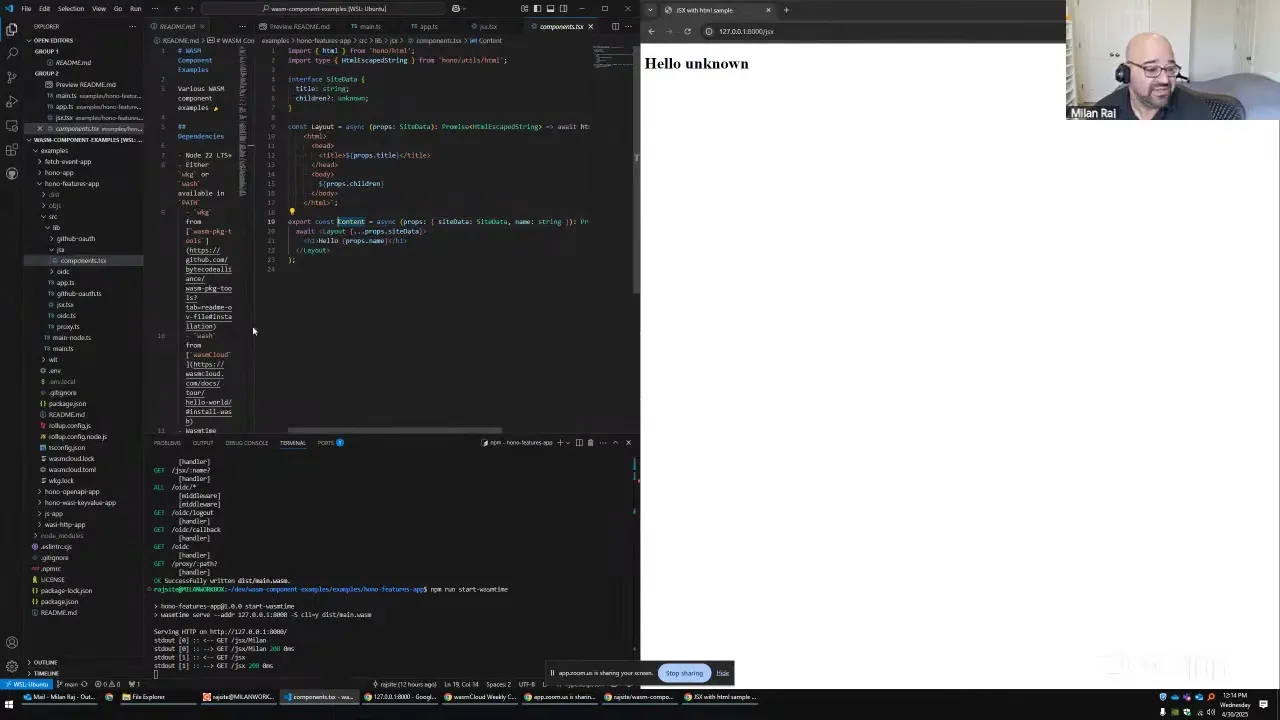
Milan Raj 17:58
This mirrors a JSX component, and you can see it has strong typing for props and everything — all TypeScript is wired up as you'd expect, but this is going into a JSX component definition. So I can have server-side rendered components and build up a web application that way, as an alternative to hosting static file content. Both are great, but the main thing here is that you can integrate it just by following the out-of-the-box tutorial from Hono. They say go in here, in the TS config, swap out JSX for React — and it all just works, which has been the most exciting thing about going through all these demos: they just work.
Milan Raj 18:50
This next one didn't necessarily just work out of the box, but now it does — I submitted some patches upstream to the OIDC middleware for JCO. This endpoint is plumbed into Google OAuth for OIDC, so it creates a couple of endpoints. The root endpoint is gated on having auth available. I'm not logged in right now, so it's going to redirect me to log into my OIDC provider — in this case routed out to Google accounts. I'll log in, approve the connection, and now when it goes to that same route it's authenticated, the middleware successfully passed, and it returns my current auth session information.
This plugin is particularly handy as a really bare-bones OIDC implementation, because it's designed to handle all the cookie and token management through cookies. I don't need to set up a separate store or rely on KV to persist that cookie state — cookies are the default workflow out of the box. I can log in, log out, and then log in again. I did a similar pattern for GitHub OAuth — those are different plugins, and this one didn't require any changes; the existing middleware worked out of the box. So this one creates tokens on GitHub, I made a GitHub app, I can authenticate against it and pull info about my GitHub account. And the last major demo there was that their proxy config worked out of the box too — it's proxying all requests here to httpbin.org, so I can hit the JSON endpoint and it proxies the whole API.
The last big thing I wanted to show is that it's plumbed up to run all the exact same demos via Node, so I can set breakpoints in VS Code and debug the application that way.
Taylor Thomas 22:34
Sorry — you're debugging the Wasm, or you're debugging the JavaScript?
Milan Raj 22:38
Debugging the JavaScript version of the Hono application in Node, yeah.
Brooks Townsend 22:48
I don't see any reason to stop here. Keep going.
Milan Raj 23:00
The other one that was fun is the Hono OpenAPI demo. Hono has another middleware package — a third-party package — that lets you do typing around your whole API surface area. Instead of creating a new Hono object, you create an OpenAPI Hono object. Now, instead of defining routes using the existing Hono API, you use app.openapi, and you get really strong typing of the context and all your parameters. The reason you get that is the way you define routes: you use Zod — Zod OpenAPI — to create your types of all the inputs and outputs allowed. The nice thing about this approach is it can include documentation, so you can see OpenAPI doc definitions and examples in here. And when I do c.request.validParam, I get strong typing back about the inputs and outputs — it'll complain to me if the type definition is supposed to return a field that's missing. So you get strict typing in and out.
The way this looks when it's running: on the root of the application I'm rendering a Swagger doc, and the actual OpenAPI documentation JSON is at this endpoint, so the UI points to that to render the docs. Now I can test out these different routes — test my stats route, send values across, get responses back, and if I'm missing fields the OpenAPI middleware handles all the parsing for me and tells me, "hey, you're missing your types." So it saves you a lot of boilerplate work.
On this example specifically, I also instrumented benchmarking — you can start the Wasmtime server, start the wash server, and then hit it with Apache Bench to get some high-level stats about how fast things are running. So I think that's most of the examples I wanted to share.
Brooks Townsend 26:37
Milan, I think we're going to have to institute a new rule, because I had a demo planned after this and it's just not cool to come in and do all this. Sorry for the jokes — this is awesome. This is really cool to see a fully featured JavaScript example. My one question: what about Hono makes it so special that all this just works when we bring it to Wasm?
Milan Raj 27:30
Hono's whole spiel is that they're built on top of web standards out of the box. Their middleware approach just passes around standard JS fetch-based request/response objects. They have built-in support for the service-worker fetch-event API, which happens to be the same API used in ComponentizeJS. Because they're hard-focused on being standards-oriented, it makes it really easy to plug into other runtimes. It's a project that came out of Cloudflare for their Workers, but they have adapters for Fastly, Cloudflare Workers, service workers, Node — a list of about 10 JS runtime environments. By being standards-aligned, I think it'll be cool at some point to get the ComponentizeJS / JCO runtime onto their list of supported runtimes. A couple of things — like their built-in env support for checking process environment variables — we'd need to contribute some code to actually get environment or secrets from whatever the back end is. It'd be cool to start integrating that first-class in those frameworks.
Liam Randall 29:25
Milan, wow. I know I taunted you on the demo, and man, talk about delivering — really loved that whole demo, start to finish. So much of what Cloudflare has been putting out lately has just been top-notch, and I love to see the alignment with WebAssembly. It makes sense given Workers, and it wouldn't surprise me if they're using similar tools on the back end, considering we're all converging on the same standards. My question is: what's the size of the artifact this compiles down to? And then cold start time — any testing there?
Milan Raj 30:22
I could have more numbers next time, but the start time is incredibly fast — a millisecond or two to service out and respond to the request. All the examples I've shown aren't well primed for a raw benchmark because they proxy out to httpbin, so that network request dominates the response time. On the stats example built on the OpenAPI infrastructure, I'd pass in 10,000 numbers and run a statistics calculation; type-validating 10,000 numbers in the OpenAPI infrastructure is kind of slow. If you start a Node process and do that first execution and then the first execution with the Wasm process, they're about the same. But the benefit Node gets is, because it's dirty and not creating a new instance per request, it starts JIT-optimizing and getting faster until it's about 10x faster. If you remove all the Zod validation, it ends up almost identical to the Node process — maybe about half as fast, but that's one millisecond versus one and a half. The component features one right now is about 13 megabytes. I was also experimenting with AOT compilation, and that blew up very large, so I stopped looking at it.
Liam Randall 32:32
Is that with all the assets compiled in as well?
Milan Raj 32:37
Yeah. The Hono features one was 14 megabytes snapshotted — it probably initializes more heap space when it snapshots. The Hono bare-bones one was 11 megabytes, and the non-Hono super-bare-bones one was 11 megabytes too.
Liam Randall 33:00
Thank you so much. Fascinating — lots of research there in play.
Lachlan Heywood 33:09
Yeah, it was fun to come across, because I thought I was doing this by myself when I added that example to the repo. It's almost like simultaneous discovery — we both came to the same conclusion. They basically did the one from the wasmCloud working-group meeting and were like, "oh, you didn't even need this extra stuff you've got around it," and Milan had already discovered that same thing. It's awesome to see how easy it is to run TypeScript compiled down to JavaScript that just runs inside of Wasm. I'm excited to see what tooling takes shape in the ecosystem. The environment-variables one is neat as well — we started the conversation in the working group around what it looks like to take environment variables, like config runtime, and have StarlingMonkey (the way JavaScript runs inside Wasm) automatically detect that and pass it through to stuff like Hono so it's ready to go. There's going to be rapid development on a lot of this stuff — even six months ago it was not this easy, so it's cool to see the progress.
Brooks Townsend 35:37
Amazing. Milan, would you mind posting the link to your repo in the chat, and feel free to cross-post it in the wasmCloud Slack? I'm sure folks would love to take a closer look. Around the OIDC example — I noticed there were some secrets. Are you compiling those into the component or pulling them from the environment provider?
Milan Raj 36:21
Currently I'm compiling it into the component, because that was the easiest way in my dev environment to run across Node, Wasmtime, and wash. It's not ideal. I did use the dotenv rollup plugin so it's at least not checked into source — there's a separate .env.local file — but it is compiled into the component asset. What was blocking me from trying something like wasmCloud secrets or env variables was: if I wanted it to run in the Node context too, how do I shim out those WASI env imports and polyfill them to process.env? So it was handy for the developer workflow locally, but not what I'd do in production.
Brooks Townsend 37:40
My intent wasn't to trap you into revealing it — I just see definite potential for integration with the wasmCloud secrets interface, getting that upstream as WASI secrets, doing it in a standard way from environment variables. Those are all really huge things we'd love to work on. Milan is in the wasmCloud Slack, so I'm sure we'll have fun JavaScript and TypeScript examples and discussion there, especially with the recent buzz around Hono. Thank you, Milan, for coming on and showing this — it's huge for the JavaScript ecosystem and for components in general.
Milan Raj 38:46
I appreciate the push to actually do it. I've been sitting on the examples for a while, so it's good to get them out there.
Brooks Townsend 38:59
Well, that's hard to beat, but let's go on to our regularly scheduled agenda. For today: I had a quick demo on component instance saturation — really the number of active instances metrics — then a couple of discussion items, one for a pretty large PR that came into the wasmCloud repo earlier this week, and then I think it's well worth taking some time as a community to discuss the statement on proposed changes to the CNCF NATS.io licensing and ownership.
The demo should be quick. This came about with a little collaboration with Milan, where we were talking about a question I want to be able to answer about wasmCloud components: how do I know how many instances of a component are running at any given time? How do I know what my max is? How do I know if I need to increase that number? These are things you run into when you start running components for real. You could bypass it by setting your limit to unlimited, but it's better to have a little more evidence. The best way to start answering these questions is to lean more into our observability implementation. So in this PR there are two new metrics: the component_max_instances metric — the max instances you set when you run a component — and component_active_instances, the number of components instantiated and running at any given time.
If I drop over to Prometheus: all I've done is launch the OpenTelemetry Docker Compose example from the wasmCloud repo and run wasmCloud with WASMCLOUD_OBSERVABILITY_ENABLED=true, which turns on traces, logging, and metrics, then deployed the key-value counter — the example app that's HTTP to a Rust component to a Redis database. An existing metric, invocations total, tracks total invocations over time. We can query component_max_instances and see this component's max scale is set to 100, and if we query active instances, over the last five minutes there have been none.
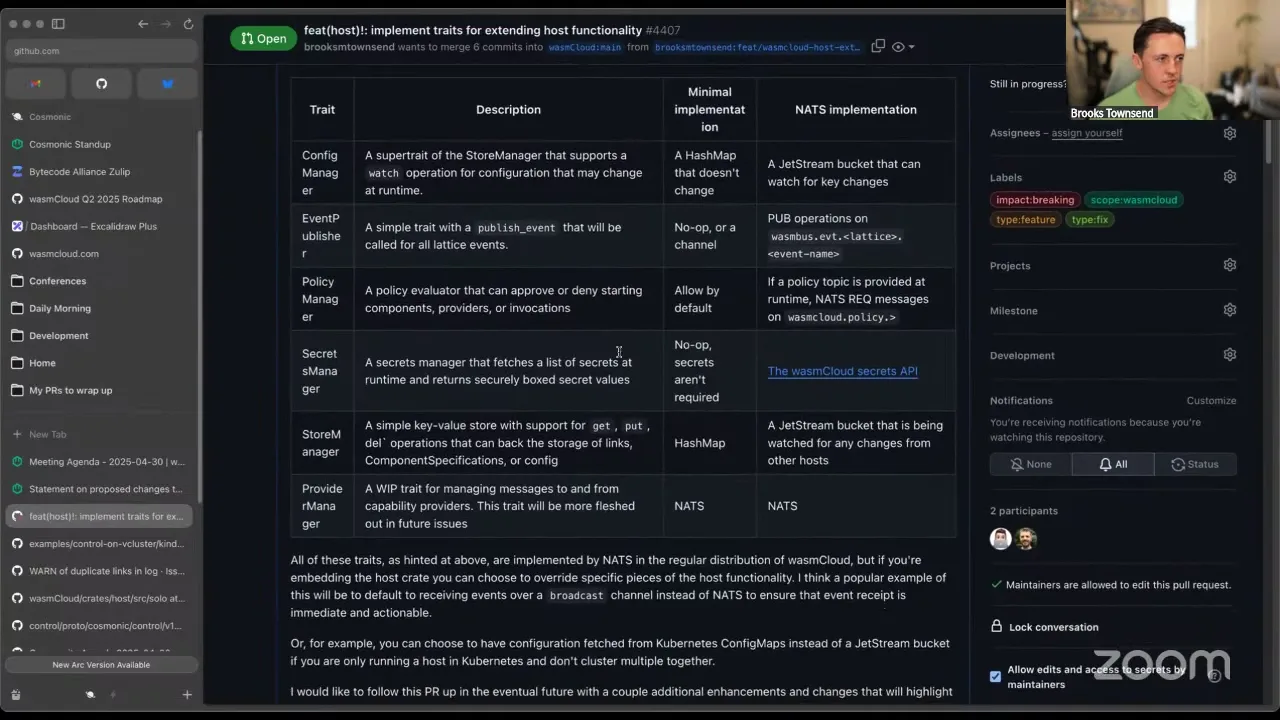
So if I throw a bit more load at this component — concurrency level of 100 at a time, 100,000 requests — then over the next couple of seconds, as the metrics get exported through Grafana with Prometheus, we'll see the number of active instances climb to the actual number, which is likely less than 100 because of how quickly Wasm opens up and completes execution. Our active instances metric shot up to about 22, so at the time we exported that snapshot we had 22 active instances. What's really neat is we can express active instances and max instances as a ratio — so it's no longer a strict number but a percentage of the max. You can see when we were getting 100 concurrent requests we reached about 22% saturation. You can also use this for alerting: set an alert to say if I reach 80% or 90% saturation, send me an alert — maybe something's going on, maybe we're just getting high traffic. That's really what this PR is all about. When we set up metrics for the host for 1.0, we shipped a couple of baseline metrics, so it's nice to get back to this code and enhance it. I like to frame all the open observability stuff as a way to answer production questions — "how do I know if something's going wrong with my component, how many things have errored" — these are the things I think we should lean really hard into OpenTelemetry for.
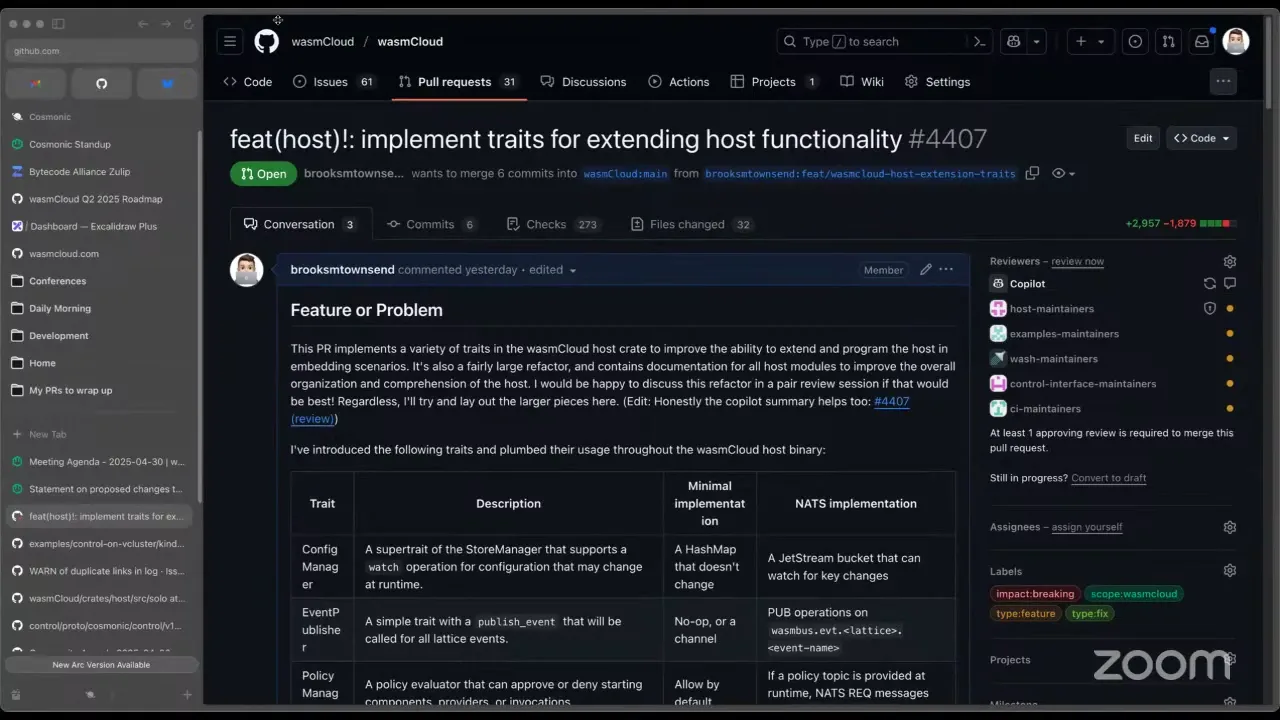
Brooks Townsend 46:34
Okay, on to the discussion items. The first is a fairly large PR I put in a couple of days ago. For folks who get scared about the number of lines changed — primarily this is a refactor. The intent is to improve the embeddability of the wasmCloud host. The wasmcloud binary you run in production, or download with wash, is actually a crate that just embeds the wasmCloud host library — and anybody in a Rust project can do the same: take the host library, embed it, run components, set up links, all of that. There's an issue, though: we haven't exactly designed our host API to be embedded — there are missing functions you'd expect to call — because we primarily lean on NATS for the control interface, for socializing configuration and links between hosts.
So the goal of this PR is to put some of the host behavior behind common, simple traits. For all the events we publish in wasmCloud, previously we'd publish to a NATS topic at wasmbus.evt. But if you're embedding this, maybe you just want to get a channel and have all those events fed directly to you. Now the host uses an event-publisher trait abstraction, and you can supply any implementation — a channel, or turn it off entirely if you don't need events. Same thing for configuration and for simple data stores: if you didn't want to store those in a NATS JetStream bucket, you can provide a hash map. A lot of this is framed from the guise of a NATS implementation and a minimal implementation, but I think about it as a distributed wasmCloud implementation — our default mode — versus a minimal, dumb embedded implementation where the goal is to remove as many dependencies as possible and get down to the basics of running components.
I was really inspired by the generics the wRPC library gives us. All the transport we do over RPC uses the wRPC transport abstraction, so feasibly, as we add support for a more pluggable host that supports multiple transports, you could have your workloads communicate over TCP, or over Unix domain socket — you get to program the wasmCloud platform the way you want it to work. TL;DR: a lot of lines change, but there are no breaking changes and no functionality changes from the binary perspective — when you just run wasmCloud, it does exactly the same thing as before. But when you're embedding the host crate, you have a lot more knobs. This also comes with improved host-crate documentation. Do folks have any questions on this one? I know it's a big one and didn't want it to look really huge and out of nowhere.
ossfellow 52:49
Hello, Brooks — this is awesome. I want to ask about something that's kept my mind busy: a bit of inflexibility in the runtime that basically hard-codes the wRPC implementation. Obviously it has a good impact on performance, but it's limiting, and in this embedding, what we're really embedding is that limitation with it. At some point this needs to provide a bit more knobs in the runtime, because I have use cases that want to do an alternative implementation of wRPC, but the runtime does not cooperate unless we change it.
Brooks Townsend 54:05
Yeah, exactly. These were really low-hanging-fruit implementations — of course we can't do it all in one PR, but that's exactly the same motivation. The areas of the wasmCloud runtime where you don't have that customization knob should be few and far between, especially with wRPC. I know we can change the wRPC transport, but I'd love to do additional thinking about how we make that generic and implementable by anything. My initial thought when coming up with this PR was that it'd be really cool for the host not to manage links and targets and where everything is living in the lattice all at once — that's a lot of computation for the host. It would be great for the host to consult a simple abstraction: "hey, this component is trying to call a function on this interface — where do I send it?" We have the option to have that call a component in memory, give back a wRPC NATS transport to send the function over NATS, or return an error and say the component isn't allowed to invoke that target. Is that the kind of goal you're hoping for too, or something a little different?
ossfellow 56:08
The choice in transport is quite important — I have use cases that would benefit from alternatives. But also, similar to this, if we could allow alternative implementations of those interfaces in the runtime, I'd have more control about how my custom host behaves. For example, if you implement an all-in-one NATS provider — object store, key-value store, and other things — it unlocks a couple of use cases. It's less setup for use cases that don't need a lot of separated bandwidth, and it gives you the option of doing things you can't do when implementing them separately — because at the moment we don't support provider chaining. That means I can't just pass something from one provider to another for further processing, unless I put a plug component as an adapter in between. So that makes implementation more complex just because of the way it is right now.
Brooks Townsend 58:24
Yeah, lots of good ideas there. I'd love to look all the way down the wasmCloud stack. It's part of our whole value prop that you can extend wasmCloud at runtime with components and providers, providing all your own functionality, so let's keep adding more where we can. Vince had a question — is wasmCloud becoming more polyfill over time?
Vance Shipley 59:30
It does seem there's a bit of a trend there — as wRPC becomes a standard and really moves out. It's a positive thing, right? More and more, let's have a bunch of standards accomplishing this communication and enablement of what we're trying to do.
Brooks Townsend 1:00:09
Yeah, I agree. I think wasmCloud should strive to be a pluggable, extensible platform wherever we can — without making it intentionally obtuse with the abstractions — just to enable more use cases and people customizing it. We should lean into what we do well as a project. I think we definitely should be going in that direction.
Brooks Townsend 1:00:54
All right, I'll transition to the last discussion item. Thanks for letting me talk about the big chunky PR. The last item is around our blog post earlier this week, our statement on the proposed changes to the CNCF NATS.io licensing and ownership. I'd highly recommend folks give it a read. We put it together as org maintainers first, to make sure we stayed on top of the story, because NATS is one of the only things wasmCloud really took a stance to integrate tightly with. If you look at our ADRs, ADR 0003 uses NATS — we've used NATS as a core part of our platform for quite a long time.
The whole point of the blog post is to say that we're not worried. We're dedicated to the CNCF as a project — that's what makes this such a powerful community, having all these open source projects that work together. There's lots evolving about where the licensing and ownership is going, but it's worth noting we plan to support NATS as a way to do transport and distributed communication no matter what. Obviously I'm preferring to keep it as something Apache-2.0 licensed so we can stay all open source. We have precedent — our Redis key-value provider works with Valkey and Redis, or our Vault secrets provider that you could use with OpenBao. From our perspective this is just to reassure that this is not a threat to the wasmCloud ecosystem. We're going to keep building the best project we can for running WebAssembly in a distributed way. And we've been designing our platform around these pluggable abstractions that give folks options if they want more control over their infrastructure and routing — so it'll be completely valid to use wRPC over TCP to hit another container in your Kubernetes cluster, or wRPC over Unix domain sockets if you're running everything locally and want raw performance. I'd recommend the talk we did last year on wRPC if you want more on the fundamentals. We're already working on making the host slimmer and pluggable so you can choose the NATS implementations — which aren't going anywhere — or different default implementations. So, want to reassure everyone that NATS isn't going anywhere; it's still a core piece of our distributed story. Folks have any questions?
Milan Raj 1:06:47
How close do you feel you could run completely decoupled from NATS at this point? What are the pieces that are still coupled?
Brooks Townsend 1:07:02
Not yet — there are two main pieces we're tightly coupled to NATS for. This is my attempt at drawing a wasmCloud architecture diagram. In the wasmCloud host we have things like basic configuration, OTel traces/logging/metrics, our runtime (where WebAssembly is), and our native binary provider API, which sends links and config updates over NATS to capability providers spawned by the host process. Then we have all the different pieces of infrastructure — watching for links in a KV bucket, subscribing for control interface messages from NATS, our secret store, and our policy service — all messages that go through the NATS message bus.
Now, after the traits PR, the story is a little different. Inside the host all the basics are exactly the same, but all those pieces where we were using NATS APIs directly — but maybe didn't have to — are now abstractions: the data store, the control interface server, the config store, secrets, policies, and events all have lightweight abstractions. Really simple — the data store is just get, put, delete, and watch. The NATS implementations are still in-tree, and by default when you run the binary we use those NATS implementations, working exactly the same way. The only two things we're still tightly coupled to are the native binary provider API — sending messages to capability providers for links and config — and wRPC, for all the messages that flow over RPC. As we called out, the wRPC transport is already a pluggable abstraction, so instead of a NATS transport client we could give a TCP transport client; but none of the existing providers are quite in a place to listen over TCP yet — we just don't have a mechanism to flip a switch so a provider listens on a socket instead of a NATS subject. And the native binary provider API leaves some functionality to be desired; ideally we'd run capability providers in a couple of different modes. The biggest part we need to address is routing to different targets in a world where you can't just publish directly to a topic and have it routed magically. For folks running wasmCloud at big enterprises, often they're inside Kubernetes with some Istio or Envoy service mesh addressed over HTTP that they can already hook into for routing, so being able to hook into that is a desirable property at large scale. Milan, I hope that answered where we depend on NATS and what's left.
Milan Raj 1:12:25
Yeah, absolutely. Thank you.
Florian Fürstenberg 1:12:35
Brooks, do you plan to add these diagrams to our docs, or are they already part of the docs?
Brooks Townsend 1:12:42
Not part of the docs yet, but I would love to get them up. A flat architecture diagram of what the host is would be valuable for sure.
Florian Fürstenberg 1:12:59
Actually, I was looking for such diagrams when I started revising wasmCloud, so it would have been quite a help.
Brooks Townsend 1:13:13
Thanks for the call-out. I'll make sure we get this into pull requests, take any comments and reviews, and then I think this can go right into an architecture section in the docs.
Jochen Rau 1:13:38
I just want to comment that, after the first shock of the announcement, from the perspective of wasmCloud I think over time it actually makes it a better product, because putting in such an abstraction layer forces a clear separation of concerns. In the end it's for the benefit of wasmCloud. And thank you for all the work being put into that aspect right now, although it sidetracks other things that were probably higher on the to-do list.
Brooks Townsend 1:14:28
Thank you, Jochen, for some positivity. I'm very eagerly watching what's happening, and I think all of us as wasmCloud maintainers will just keep in mind the best thing we can do for the project. We're doing some exploration on abstractions and confronting assumptions, but rest assured that for wasmCloud the defaults don't change — we're doing everything over NATS just like before on the implementation side.
Jochen Rau 1:15:18
I can just speak for us — for machine metrics, we're going to stick with NATS, obviously, because it's the best technology by far. There's really no alternative on that front for IIoT; it's very hard to replace, and we would choose it again no matter what the outcome is here.
Brooks Townsend 1:15:41
Thank you for coming and talking about that. It's really useful to hear from the power users — it is a very unique technology.
Vance Shipley 1:16:05
I have a probably unique take on this. This is the world I've been living in for 25 years, and in all that time I've always been an outlier, because that's not a mainstream community. So the challenge in working in that community has always been creating low-impedance bridges to other technologies. A lot of the effort we end up spending is on creating those bridges, and I'm looking at this as a great opportunity for creating a great bridge between the Erlang distributed, concurrent environment and wasmCloud and WebAssembly. I'm quite enthusiastic about it.
Brooks Townsend 1:17:19
Thank you, Vance — I'll take the enthusiasm. wasmCloud Elixir host v2, baby. I did actually see that the library we used when writing the Elixir wasmex does support WebAssembly components now — you can run Wasmtime in the Rust NIF in your Erlang app, which is pretty cool.
Brooks Townsend 1:18:10
All right, everyone — I know we're over time, and this was a really important discussion to have. I appreciate everybody taking the time to come in when this is the agenda item, just to chat, get together, and realize it's all going to be okay. It's just software at the end of the day. Let's keep this conversation as open as possible — if anybody has questions, please ask in the wasmCloud channel: interest, direction, where we're going, what we're planning. We want to be as open as possible. We just had our roadmap planning in the last community meeting, and I don't think this changes anything about what we need to focus on over the next two months. The Q2 roadmap remains about the same, and I'm looking forward to doing more planning later in the year. Thank you again for coming today. We'll pick everything up in Slack as usual. And Milan, special shout-out — thank you so much for the introduction and all those awesome demos. Good to see everybody on the call. Have a wasmCloud day; we'll see you in May.