Transcript: Compiling Go to WebAssembly: Embedding NATS in wash
wasmCloud Weekly Community Call — Wed, Apr 16, 2025 · 60 minutes
Transcript
Brooks Townsend 03:47
All righty, hey everybody, welcome to wasmCloud Wednesday for Wednesday, April 16. We've got a pretty fun agenda for everyone today. We are going to be doing something wild, which is starting with an item and then doing a demo — new, unexplored territory for wasmCloud Wednesday. We'll see how it goes. The first thing on our agenda is to talk about some of the research and findings that one of our wasmCloud maintainers and community members, Masoud, has been working on for quite a while. We talked about some of it in Slack, but it's time to bring that into the community call.
I have a little bit of a demo around the story about embedding wadm and wasmCloud and things into wash to make a single, static binary — a little more interesting hackery coming out of that. And then we're a little bit overdue: we tend to overshoot the beginning of the month for the roadmap planning, but I'd like to call attention that we will likely be doing that planning next week during wasmCloud Wednesday. We have a GitHub discussion, and now is essentially the time for you to make your voice heard.
So why don't we go ahead and get started on provenance and attestation research and findings. This is a pretty large — not issue, but RFC — of changes that's been proposed. Masoud actually originally opened it. Masoud, would you like to give a quick background on your original intent and kind of where you are now? You're welcome to share your screen, and I can drop this link in the chat.
Masoud (ossfellow) 05:53
Sure. The spirit of the RFC is about bringing in some of the supply-chain security stuff. We all know this has been looked at before — last year I believe Joonas and Carlos did an investigation, and they talked about the certificates and the assurances that are produced via different tools in the build process in order to attest to whatever is being built. When we're talking about that attestation, it simply means it attests that what it says built it is the one that built it. It doesn't really mean anything about the nature of the content. These are different things that have different scopes for different tools.
And then it was getting into other things — workload identity — and thankfully now workload identity has its own full-fledged RFC that Joonas and Colin have put together, with demos. So we know we have work happening there. This RFC is just about the build process. If people remember, there was an executive order after the SolarWinds incident.

Masoud (ossfellow) 07:17
And then the Linux Foundation got involved, and out of that came a kind of specification that was widely adopted across the industry — SLSA. It's about setting forward a number of practices, as well as measurements: putting checks and balances in place for your build process. And there is a rich set of tooling there. But as this experience shows — and if you go to the cloud-native security conferences they talk about these things — the maturity is still lacking in some areas. For example, here I have used three different tools in order to produce SBOMs for different languages. Rust doesn't work with one, and another doesn't work with Python, and Python doesn't work with Go. So there's a bit of complication just right there.
Nevertheless, a paper came, and GitHub put together a number of actions based on it, speaking about putting official GitHub actions in place that people can use in their pipelines to do attestation and then do measurements. In that paper, they said that if you do this in a reusable workflow, then you certify SLSA Level 3. Level one means manual builds. Level two means automated builds. And then after that, you're producing attestations for the build binaries, and by adding those layer by layer you go up to level four, which is the final one. The way I interpreted the paper was that if you do the attestation part in a reusable workflow, you reach level three, because we already have an automated pipeline.
Then I had a cloud-native security friend meeting in January, and one of them highlighted my misunderstanding: that the isolation requires both the attestation and all of it to become encapsulated into a reusable workflow. And that's something that, in the current pipeline that we have, wasmCloud doesn't — it's something we can gradually build towards but it's not what we have. So I said, okay, let me at least finish this and show that if we do this, what will be produced — because if you look at the job results you see the attestations, you see the SBOMs, you see the certificate. You can click on the links and go to the GitHub panel and look at the attestation records. So we have everything you could see at any level.
But because you do this in different steps and different parts — we build different pieces in the pipeline — that means there are a lot of insertion points for calling different actions to produce an SBOM, produce attestation, back them up, put them into an OCI package, do metadata enrichment, and so on. All of that is already built, but the complexity of the pipeline goes up a lot. So the question is: this is the result, those are the actions; if the maintainers and the community decide it's still worth it and we want this, then there will be some massaging needed to reflect the latest pipeline. But maybe we can delay this until we have, let's say, a version-two pipeline, and do better engineering by reusing a lot of things and reducing the boilerplate we'd have to put in place every time a build or OCI packaging is happening. That's the whole story.
Brooks Townsend 15:11
Thank you for doing some background and catching everybody up to speed. I know you posted a long message in the wasmCloud Slack, but it's good to air it all out here.
To my own perspective: I know we have a pretty complex set of GitHub pipelines, which generally comes down to the fact that we have a monorepo. We have a lot of different targets and languages that we're building for, so we try to do the best thing we can around building for lots of different architectures and OCI images. And it does definitely make the pipelines complex. I hesitate, generally, to make it more complex, especially around new things that I think we know would be important to have — like having SBOMs get generated and being able to verify that. I don't know if this is something we have to take on right now, or if anybody is actively trying to do this. I don't see it as something we have to make our build pipeline more complex with now, but that's not a strongly held opinion.
Joonas, I'm not sure if you're in a good place to chat, but I was curious of your thoughts about whether you think this is something we should go down the avenue of right now. Masoud, I think you brought up everything but didn't really offer your recommendation, so I'm interested in what you think is the best path forward too.
Masoud (ossfellow) 17:48
About pipelines — to tweak them — for providers and such, sometimes I have to adjust the wasmCloud pipeline just to publish something. You have to turn knobs in different places, and you kind of need to know your way around. And this thing that I have built — again, somebody might be a better designer or engineer and do something better, but this is my creation — what I have built is complex. I made multiple mistakes because I had to insert this everywhere. I built special jobs and a repository for it that embeds wasmCloud and then runs the jobs in order to assess them, and in that I had to modify things. Long story short, the pipeline gets kind of unruly, and I'm not comfortable with that myself.
Joonas Bergius 19:05
Maybe to echo a little of what Masoud said: if this is a goal we want to go after, there's probably an opportunity — we will probably have to step back and look at our pipelines as they are today and think about how we could make them easier to work with, so it doesn't feel like we're retrofitting a bunch of stuff on top of an existing, already fairly complicated system. So I don't think we're in a good place, from a CI perspective, to just drop this in right now. I think it would take a bit more work, and really building with that in mind, because we've organically ended up in a place where it's maybe a little challenging to get all these things in place. It might be possible to put it in all the right places as part of the monolithic workflow we have, but in reality, to make it part of everything we do, I think that would take more planning to do effectively. If we don't have an immediate need for it, I would probably not rush into the existing system. But I also don't have a clear line of sight of what a redesigned pipeline should look like in order to better support this yet, so that's something I'd defer to someone with a bit more experience designing and working through a pipeline like that.
Masoud (ossfellow) 20:53
I totally agree with everything you said. In terms of the last part — what it looked like from this — it means there will be more cycles to build because we have to separate things, and it's already long.
Brooks Townsend 21:20
Yeah, I really like the idea of figuring out — sorry, Lucas, just reading your comments — figuring out what we need to do really commonly in our CI: building a component, building a binary for wash or wasmCloud, building a provider. This feels like a good opportunity to start making common actions that we maintain: given a specific directory, build an artifact, and what comes out is the SBOM and the artifact itself. This work would feed directly into that — the requirements and how we implement it. But I think we do need to spend a bit more time looking at how we're doing pipelines in the monorepo, because that's one of the bigger challenges. We need good tooling there; we can't just keep adding a bunch of stuff.
Okay, well, everybody's welcome to offer feedback here. Please, if you are actively waiting on this — if you're really looking toward the SBOM and provenance and attestation features in wasmCloud — this is something that helps inform the roadmap, just like workload identity and some of the other things we've implemented. Community and potential people who are going to use this in production asking for it is really, really important, so please let us know. I would propose, for now, that we take all the learnings from this, certainly save all the work you've done, Masoud, and keep this in mind as we look forward at how we're going to do CI.
Masoud (ossfellow) 24:19
My personal suggestion is that we set a time — I don't know, a week, or whatever you think is reasonable — for the community to comment on the ticket. The issue we opened has all the links; they can go and examine all the results, see everything that's been produced, see the pipeline, see the job, see the complexity, and decide for themselves. After that, we can see how the community has voted, and if everybody's in favor of parking this for now, we just archive it and leave it for the future.
Brooks Townsend 25:03
Yeah, that sounds good. Not to bring the stale bot into another place, but thinking about it — if we're not coming around to it by the Quarter Three roadmap planning, then perhaps we should just archive it. But that's just a straw man; I'm picking a number out of thin air. I'm very interested in what Bailey just sent — there are some upstream things happening in the Zulip under the Bytecode Alliance SIG Packaging. It looks like there's some work happening with wackage and some of the Wasm tools for embedding that stuff in WebAssembly. Definitely a different approach, but interesting that this is happening in a couple of places.
It's worth mentioning, too, that some of the stuff that came out of your original RFC — with the SPIFFE identity and connecting to NATS — has already made its way into the host. We talked about it a little at the last KubeCon, the one that happened about two weeks ago. So it's not like we're starting from scratch — we're really excited to see the end of the implementation on the SPIFFE/SPIRE identity side.
Masoud (ossfellow) 27:20
And it's awesome — I'm already putting the markers in my queue, because the API is kind of known.
Brooks Townsend 27:33
Yeah, thank you so much for being the champion of this RFC. I can tell you put a lot of time into it, and I really appreciate it. Well, I guess we can roll into the next section in the agenda, which is a demo from yours truly.
I want to go ahead and pull up the original issue — the reason I was looking into this, which was published quite a long time ago: the idea that for wash up and wash dev, if we could bundle the wasmCloud crate and the wadm crate — the two libraries — inside of wash, then that would reduce the amount of binaries we need to download when we run wash. It would essentially make wash more of a static binary. I did an investigation into this a couple of months ago. There are three different binaries that wash downloads when you run wash up or wash dev, which bootstraps your local wasmCloud platform. It runs wasmCloud, which is the actual host; wadm, which does the orchestration and management of the application you're working on; and NATS, which is the backbone — the messaging and RPC layer and control layer for wasmCloud. So it downloads all of those from GitHub. It respects proxies, and you can run them on your own — you don't have to use the one that wash downloads — but there's a lot there in terms of supporting that. If we could just embed it as a library, that gives us a lot of leverage to make the experience better on the wash side.
Now, the sticking point is NATS. Because wash is written in Rust, and the NATS server — the thing that actually implements the messaging backbone — is written in Go, we don't really have a lot of options. You can't take that binary and embed it as a library inside of wash. So we've tried a couple of different things: compiling the server to a dynamic library and then linking it, dynamically or statically, when you run wash. But that introduces quite a lot. Right now we're cross-compiling the NATS server and shipping it with wash.
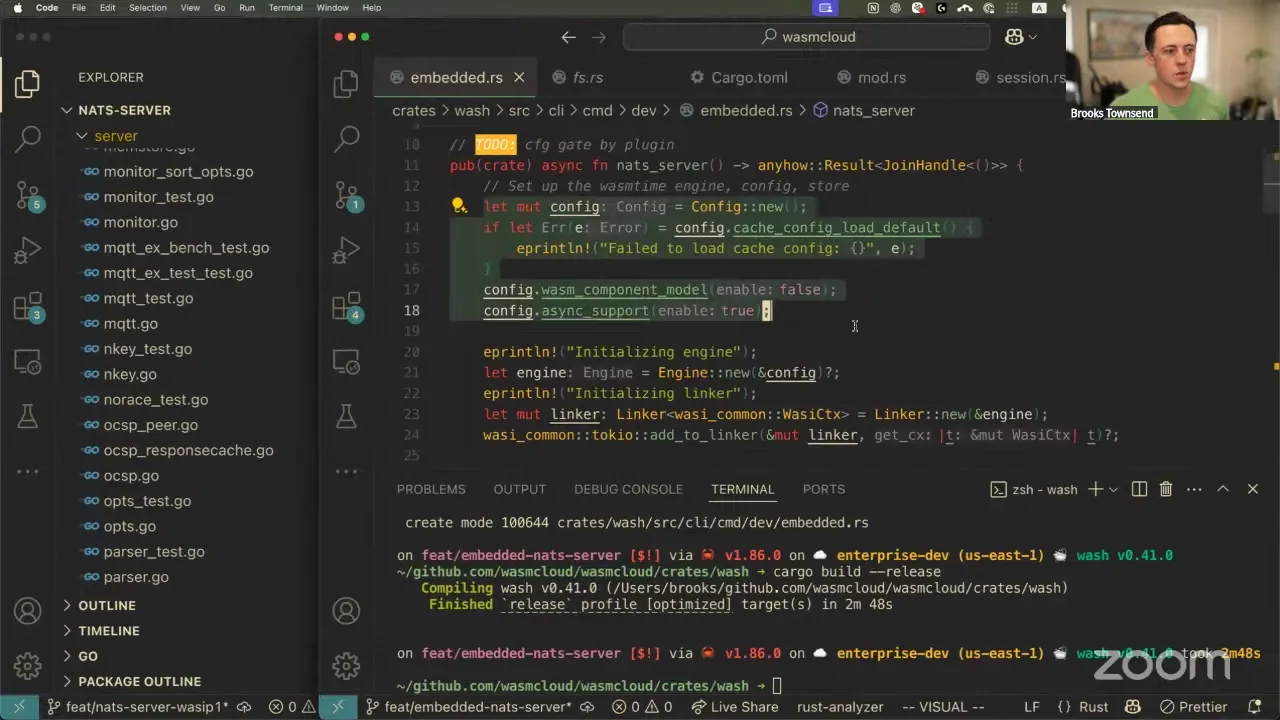
Brooks Townsend 31:00
I just want to show the result of a little experimentation. It would be really nice to be able to embed NATS in wash somehow. So I'm going to run wash dev here on our HTTP key-value project — this is the one where you hit an HTTP endpoint and it increments a counter. Very simple. wash dev does what you expect: you get the application, you can interact with NATS JetStream, all that stuff.
Now, this may seem like normal wash dev stuff, but there's something incredible happening here. If I take a look at my process list, I'm actually not running NATS at all. It's not executing as a dynamic library. It's not getting spun off as a binary. There are no tricks — I don't have it running in Docker. So what's happening, if it's listening locally?
When we think about all these issues of embedding and cross-compiling — wouldn't it be nice if we had a language-agnostic, platform-agnostic compilation target that we could take code and compile to, and then embed on any application, on any operating system, any architecture, and securely sandbox access to the capabilities it needs at runtime? I know you're probably thinking there's no way this will work, but it does.
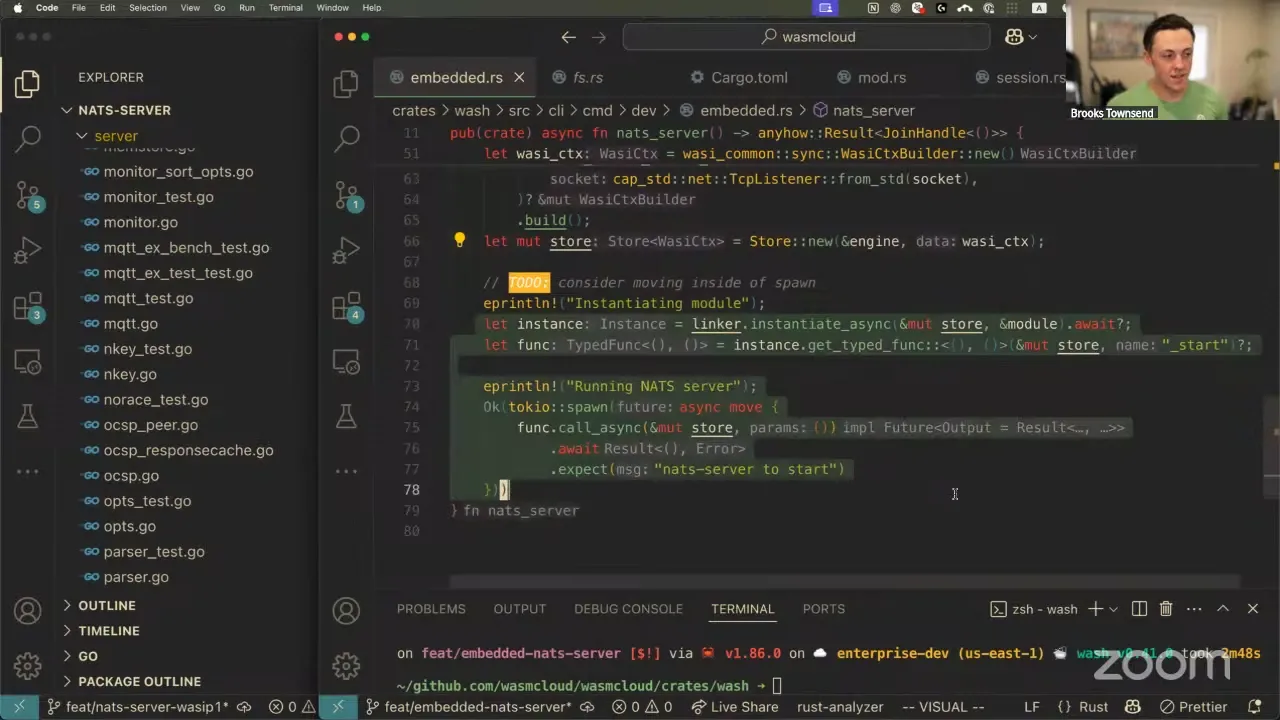
Brooks Townsend 33:30
What I've actually done — and this is entirely to the credit of Jeremy, formerly on the Synadia team, who put work into making this possible — I had to make one change to the NATS server. It turns out you can actually compile the NATS server in Go, compiling to wasip1. So if you run this, NATS is compiled to WebAssembly. This is a P1 module, so it's not a component — I can talk about why — but it is a WebAssembly module, and it's 28 megabytes. Not that bad, right? How big is the NATS server binary? About 16 megabytes. So it's a little bigger, but that's because you're bringing in the Go runtime and everything.
So you have the NATS server as a WebAssembly module. I had to make one change here, which is inside the NATS server: where you would normally — and this is using big Go, not TinyGo — open up a TCP listener to listen for client connections on 4222, instead of opening the TCP listener, we receive the pre-opened file descriptor for a socket and turn that into the net.Listener in Go. That is the only difference, and it's because in wasip1 you are not able to open your own sockets. This is actually something you can do in WASI P2 — and it gets even cooler in WASI P3.
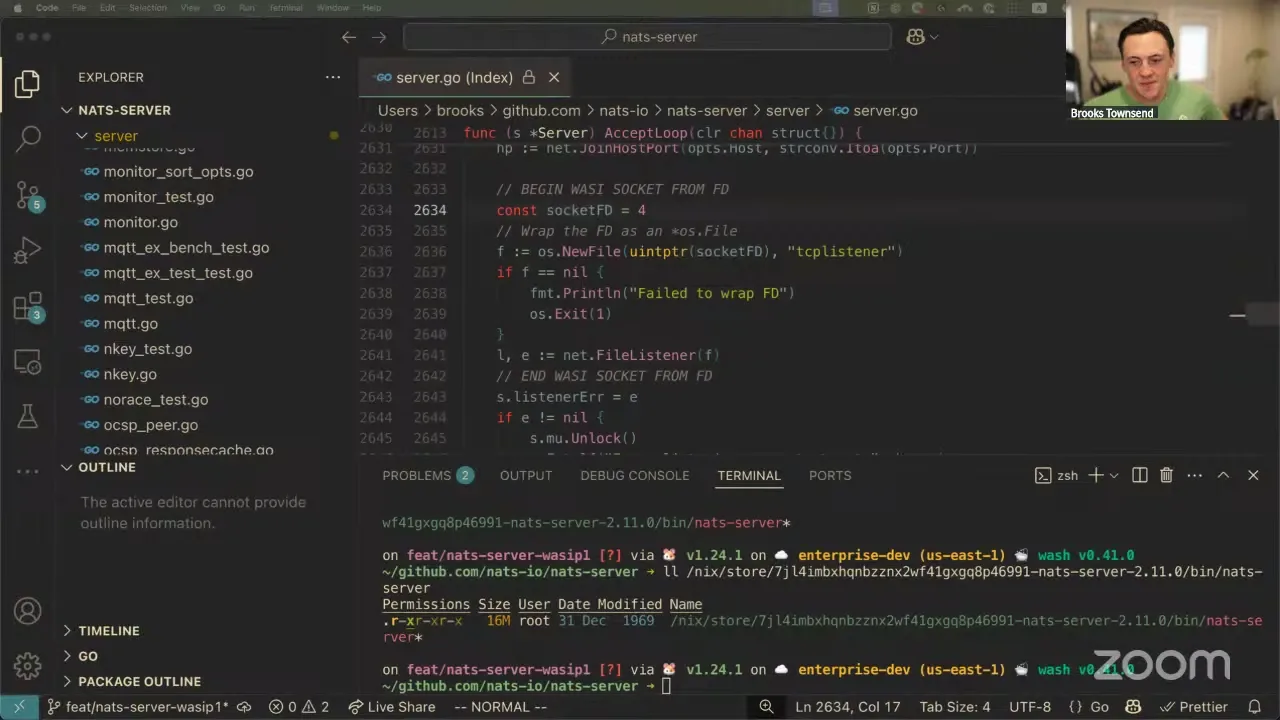
So inside of wash, what we can do is all the same things with Wasmtime that we've already been doing to embed it for plugins and to run components in the first place. We create a new Wasmtime engine and linker for this NATS Wasm. I think this is setting an interesting precedent for doing more embedding within wash. I can bind the TCP listener — here it's hard-coded, but it can be whatever we need — and I create a JetStream directory, because that's also something NATS needs access to, and store the NATS configuration in that directory.
When you run it — this is a nice preview into what everybody would need to do with WASI if you're using P1 and embedding it on your own — I create a context where I've pre-opened the JetStream directory, so it maps this local folder on my disk to the base folder that WebAssembly is allowed to access. So this NATS server can only access the JetStream directory where its config is, plus the pre-opened socket already configured to listen on 4222. Then we spawn a background task to run the NATS server. This is exactly what's happening in this wash dev pane — I just inherit the standard out and standard error, so you can see the NATS server output inline with wash. We'll change that to push it somewhere else, but it all just works.
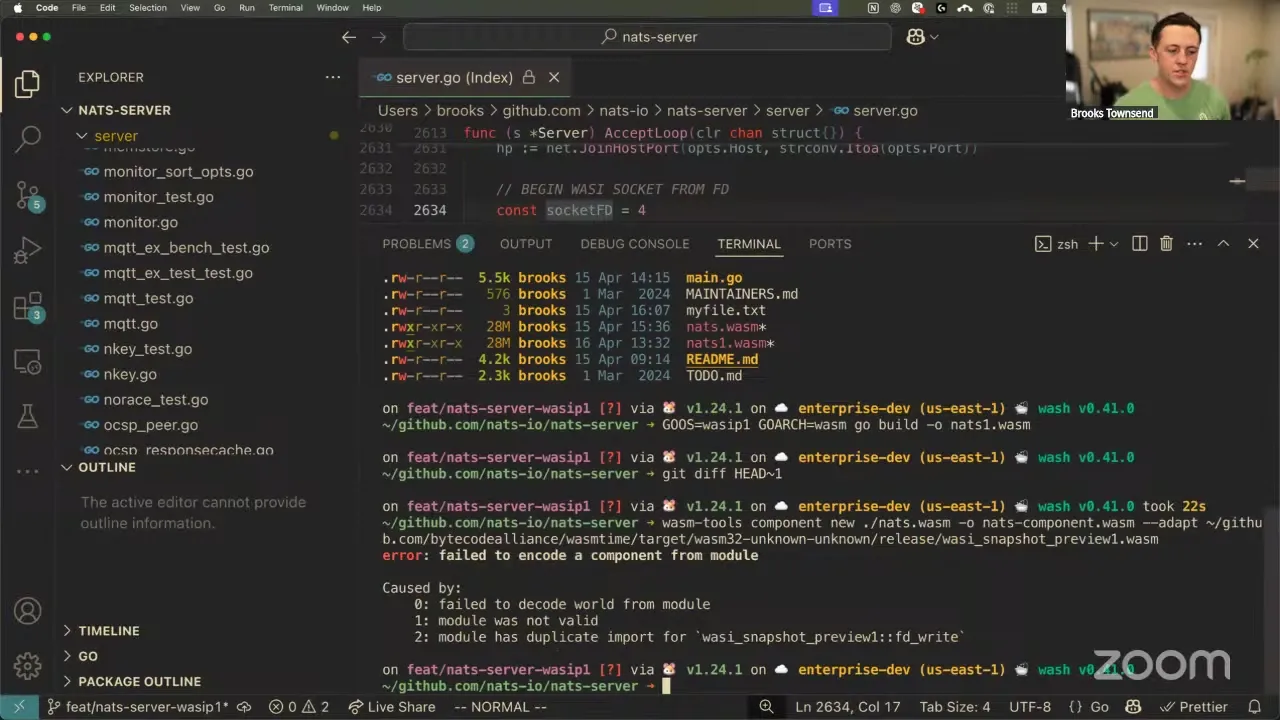
Brooks Townsend 37:19
What's pretty incredible is that I expected this to be significantly slower, because Wasm is single-threaded and it's executing as a Go module. But really it's not that bad. You can run the NATS benchmark tool locally, and I can throw 100,000 messages through this one module and I'm getting like 15k messages a second. Not that any of this really matters — it's probably not going to be recommended to do this in production — but we sure as heck can do it for development. So this is a path forward to either embed or load a WebAssembly module for the NATS server, and it works: when it hits this curl request, it goes to the HTTP server, sends the wRPC request over NATS to the components, and so on.
I would love to do a bit more testing with this. This was a lot of hackery on my part yesterday, but I'd like to see if this would work, because I think it'd be an awesome way to reduce the number of dependencies you need to run a local benchmark. Anybody is welcome to — we'll essentially need to make this small modification to the NATS server source code. Maybe there's a smarter way to do this, but it's pretty cool.
A couple of things on why I'm compiling to wasip1 and running it as a module. Joe just mentioned it — compiling to wasip1 because that is the supported WASI OS target in big Go. Regular Go WASI support is coming along, but it's not quite done enough that I could build Go from source right now and use it out of the box. And if I attempted to use TinyGo to compile the NATS server, it doesn't quite work for similar reasons — there are some missing implementations in the TinyGo standard library that the NATS server depends on. I didn't really see if I could rip all of that out; it felt like too much modification. But this one — let me show the full change list I did from upstream regular NATS to this — it's just switching out this TCP Listen to accepting from a file descriptor instead. There's a little indirection here, so I want to review this with a couple of folks to make sure it's fine.

The other piece: I did attempt to componentize this with wasm-tools component new to bring it over to be a component, and I saw a little friction. There are a couple of duplicate imports in the wasip1 module that Go builds here. If you take a look at the import list — for example, fd_write is defined here, and fd_write is defined here as well. We'll have to take a look at why; there are a couple of upstream issues, but it looks like the fix has landed in main. I'm interested in doing some hacking, but I don't want to ship a WebAssembly module built with a special version of Go. Ideally I'd just use what's out there. So, curious what people think. In the spirit of making wash simpler and not requiring downloading new binaries, I think it would be really cool to either embed this Wasm into wash — which would more than double the size of the release binary, which is kind of funny — or at least support an easy download path and running with this for up and dev. I'd prefer to have this change officially supported by the NATS server before telling folks to run it like this in production. Realistically, when you run it in production, you're probably using some kind of container orchestration anyway, so you may as well schedule the NATS infrastructure that way. Okay, I've been talking for a while. Do folks have any questions, comments, or concerns about embedding NATS inside of wash as Wasm?
Brooks Townsend 43:09
Florian, your comment is great here — feel free to come off mute, but I know you're on vacation. "Would we offer two flavors of wash, one with embedded NATS so people can choose?" That's a great question. When we looked at embedding wasmCloud and wadm into wash, the functionality to download the binaries from GitHub doesn't need to go away — we don't need to remove it entirely. I don't see an issue with giving people the option to run a binary NATS server, or the Wasm, or a container. We do have a couple of flags that support this — if you don't want wash to launch the NATS server for you, you can run it and tell wash, "hey, just connect to NATS."
Lucas, exactly what you said — I think we'd want to offer the hooks for people. If they want to run their own thing, they can. But some of the complexity and places where we fall short on developer experience come from offering too many options. Especially for the local developer experience, which is wash dev, I'd really love to have a standard experience where people don't need to worry about what binaries are being downloaded, or having a network connection at the time of running wash dev. It would be great for it to just stand up the wasmCloud platform. I could certainly see an argument for making it optional — having a flag to disable it — and I'd prefer people do that if they have a more advanced setup. The other point: downloading binaries from GitHub is fairly fickle and has a lot of edge cases that, if we didn't do it, would make our job a lot easier. And "would we offer two flavors of wash" — I'd really prefer to avoid having multiple different binaries to choose from, for the same reason. You come to wasmCloud, you're checking it out for the first time — what do I need? I need wash. We don't want anybody to have to think about which one.
Masoud (ossfellow) 46:34
One option would be to put it behind a compile flag, and then give the people who want to use it the option to compile wash with it embedded, and they can have the reduced footprint. That might be an option.
Brooks Townsend 46:57
Yeah, I'm very game to do it as a compile flag — if you're building it from source, then we can offer some additional options there, for sure.
Frank, you had a good question too: other than the size of the binary, anything else you'd expect to change between regular Go and TinyGo? I think there are quite a lot of differences, but I'd primarily expect the binary size to go down. And primarily, if we could get this into upstream NATS — I think we have a great relationship with them, so if there was a path to do it without affecting anything else they do, I think they'd be fine with it. I would love, with TinyGo, to be able to take advantage of the WASI P2 APIs here, instead of creating a socket from a file descriptor I have to pass at runtime. I would much prefer to just call net.Listen and have that get translated into a WASI P2 socket-open call. I'm probably oversimplifying, but that's what I'd expect to change. I'm also hopeful that as the Go support improves and adds the GOOS/GOARCH for WASI P2, we might be able to yank this out entirely, componentize it, and interact with the NATS server in a more robust way. If we wanted to run this as a leaf node or a cluster node, that's another two or three TCP sockets to open, so we'd have to make a couple more changes for that specific thing. But just for local, I think this could work for now.
Brooks Townsend 50:41
Masoud, you asked about the wasmCloud embedding. That's actually already done and not bad at all, because wasmCloud, the host, is just a crate that I can add a dependency on — and wash, same with wadm. Both of those support creating a host structure in memory instead of building a binary and executing it. It does all the same things. So that was the more sticky point — because NATS is written in Go and we're using Rust. So how I'd like to move forward is to combine those two aspects, put together an end-to-end POC, get some comments, and then move forward. I think this would cut out quite a lot of code we're maintaining on the wash side, and we'd still give folks the option — if you have your own instance of wadm or wasmCloud or NATS, you can disable the in-process one and run your own.
Frank, you asked how much effort it would be to use WASI P2. I think there are two ways: either a more comprehensive look into the NATS source code to see if we can adapt it to work with what's available in TinyGo — I spent a bit of time on that yesterday but didn't give it full due diligence, mainly because I went straight to the NATS source code, ran go build with the Go wasip1 target, and it just worked instantly, and I was like, "okay, this is close, we can do it." And the other side is largely WASI P2 support in big Go, which I'm not up to speed on. Bailey, you're sitting right there with your mic off — do you know how things are going for Go and P2?
Bailey Hayes 52:15
I know that one of the engineers who had been leading that effort took family time off for a little bit, so that slowed down a little. But I know folks are super interested in it, and there's a lot happening, even in the upstream standard space and core WebAssembly, that will make the design effectively performant and better. I think what you ran into — since I got a preview of your demo this morning, which is awesome — was the net package in TinyGo. The reason TinyGo doesn't compile here is a known issue where the net package for TinyGo is not what we want it to be. The TinyGo maintainers want it to basically be upstream big Go. It's one of those ways where we're coalescing into "this is the way to compile WASI for Go." So if we were able to compile — basically pprof was the dependency that got brought in from net, but when you compile big Go that had already been stubbed out correctly for wasip1 in big-Go land — so it's totally possible. If folks are interested in doing that work, I can connect you with the right maintainers to get started on it.
Brooks Townsend 53:44
Yeah, especially — everybody here who's working on wasmCloud is donating time to the open source. It's worth mentioning that if you're willing to sponsor some of the development of this in the upstream, we are certainly willing to help make the connections. We really love making these kinds of contributions and making the Wasm ecosystem bigger and bigger. The fact that we can do this is incredible — I love it. So please reach out if we can help, or if you're interested in sponsoring some of that work.
Brooks Townsend 54:35
All right. I had a feeling that demo would spawn some discussion. What I'll be taking on — it may not be immediately, but I am very interested in doing this work — so you can expect to see a PR from me on the wasmCloud side that upstreams this code as part of wash. I had to add one WASI dependency, but we were already embedding Wasmtime for our plugins in wash, so it really isn't going to change the footprint very much. We'll be able to discuss the pros and cons — binary size and all that — of embedding the NATS Wasm versus downloading it or supporting the binary. I think we can expect to see that pretty soon.
Speaking of things coming soon — next week. We've been a little overdue because of conference season and then recovering from conference season. But I'd love to give a heads-up that we'll likely want to do our Quarter Two roadmap planning next Wednesday. As a reminder, and for anybody who's new: we always do quarterly roadmap planning in the community call, a special edition of wasmCloud Wednesday. The main goal is to prioritize a couple of issues that are important on the open-source roadmap, define what we want, and set a couple of goals for the next three months. We'll do a bit of a retrospective on the current roadmap, which I think we've done really well at — we've done a ton of work in the past couple of months, and maybe bit off a little more than we could chew on some issues, and that's okay. Planning is an imperfect game.
So if you have anything you'd like to bring up for discussion there, it would really be best to leave some comments on this GitHub discussion — if there's work you're interested in doing, or work you think should be one of our biggest priorities. I'll do my best to consolidate feedback I've gotten at conferences, from people running wasmCloud at a larger scale. The reason it's best to throw it in the discussion ahead of time is that, if I'm leading the session, it's really nice to not have to parse a feature request and prioritize it on the spot. So, that's really it. I wanted to call attention to the roadmap planning and solicit everybody's feedback.
Hey, that's all we had for today, and we're right up at the end of time, so probably a good time to call it. Thanks everybody for coming to wasmCloud Wednesday, your weekly favorite Wednesday community meeting that happens at 1pm Eastern time, every time. All cheekiness aside — thanks everybody. We'll see you in Slack, and we'll see you next week on Wednesday. Have a great week. Have a wasmCloud day. Bye.