Transcript: Custom Interfaces, Distributed RPC Errors & the Wasm Component Model
wasmCloud Weekly Community Call — Wed, Feb 26, 2025 · 41 minutes
Transcript
Brooks Townsend 01:56
Hey folks, welcome to wasmCloud Wednesday, for Wednesday, February 26. Let me go ahead and share the agenda really quick, then we will get started. So get everything arranged on the screen. You should be able to see my Arc window, which is nice and good — at least, I think so. Yep, that looks right.

So today I did want to do a little bit of a demo and a discussion around custom interfaces and failures in distributed RPC, which should be a pretty interesting thing to noodle on and talk about. I want to talk a little bit about our team's focus — the wasmCloud team — and how we are going to be pushing towards some big things at KubeCon EU, which is going to be in April. And then talk about some of the maybe more lame demos that we've shown in previous community calls around CI and conventional commits and auto-generated release notes, and then show the actual fruits of our labor there. So that should be pretty fun to wrap up the call with.
But for now, why don't we go ahead and get started with a little bit of a demo and a discussion on custom interfaces in wasmCloud. Right now, whenever you start a component in the wasmCloud runtime, anytime there is an interface that's not something like WASI HTTP or WASI IO or wasmCloud messaging or wasmCloud Postgres — these well-known interfaces that we know about — we call it a custom interface. So this is something that you've defined in WIT; it expresses an interface or a contract that you're essentially wanting to either call or implement on your WebAssembly component somewhere in your application, and wasmCloud doesn't know anything about it. But when you do that at runtime, when you start the component, wasmCloud will basically create this polyfill for you, so that when you call that function, instead of the WebAssembly runtime saying "well, I don't know what that function is, so I'm just going to panic," we will attempt to send an invocation over NATS to a component or a capability provider or something that is running and listening and implements the other end of that interface. So this is how custom interfaces are supported today, and it's how you can write your own custom capability providers using an interface where the provider implements that interface — so you can provide that capability to your component, and then you can call those functions in your code.
There is a very important piece that we don't currently implement right now, and that's surfacing transport-level errors in that distributed RPC call to you. If you try to invoke another component using a custom function that you've written, and you're temporarily disconnected from NATS — now there's nothing that you need to do as the application developer to compensate for this, but if NATS is down, then we can't send the RPC message. In this case right now, we will actually panic in the component. The function call will fail. This is represented in different ways in different languages, like trapping or panicking, but we don't actually have a mechanism right now to surface that kind of error to you so that you can handle it and then continue. And this is partially by design. Distributed computing is complicated. We want to live in this world where, when you're writing your component, you aren't thinking about load balancing and different components talking to each other, and scaling, and whether or not NATS is connected, things like that. But of course, we can't ignore those aspects of a possibly failing distributed system.
So I have a little bit of a demo — more so a proposal — on a strategy we could use to address this problem. Let me go ahead and share my whole desktop. We'll go through a couple of different VS Code windows here. Let's take a look at this WIT. So this is our example hello world component that's been slightly modified so that I have a custom interface and a custom function that I want to be able to call at runtime, which I expect to give me a string. So previously, before this proposal, I may have written something like this: I'm going to call a function at runtime and it'll get a string back — if I'm doing hello world, it may be the name of the person who's greeting you, or whatever.
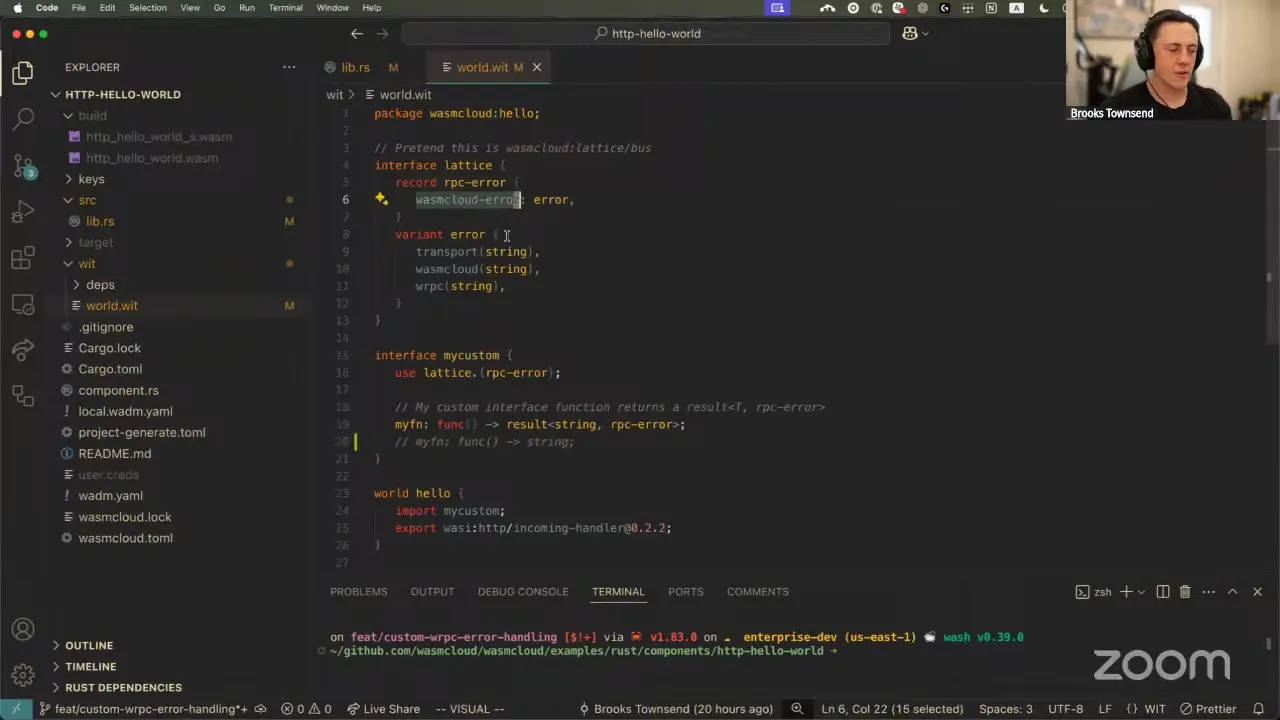
Now the proposal for this strategy is that in wasmCloud, we can actually distribute — as part of our well-known WIT interfaces — a structure like this. (This is totally an example, so take the naming with a grain of salt.) We can have a record called RPC error. This is like a struct where, internally, we can have a wasmCloud error, and maybe we could have different variants of this error, kind of like an error code, but surfacing different possible places where the invocation could fail. It could fail as part of the transport. It could fail as part of wRPC — these are kind of the same things. Maybe it fails because of something that you didn't know about — it's not really in your control on the wasmCloud side, like a link didn't exist, so an operator hasn't given permission for your component to invoke the other end of this custom interface. The important thing here is that we can have a well-known type that we support, that custom interfaces can then implement functions with — any return type, any number of arguments — as long as they fit the exact structure of a result with any internal type and returning the error type as an RPC error, this custom error type that we know about. We can actually surface wasmCloud platform-level errors to the component user.
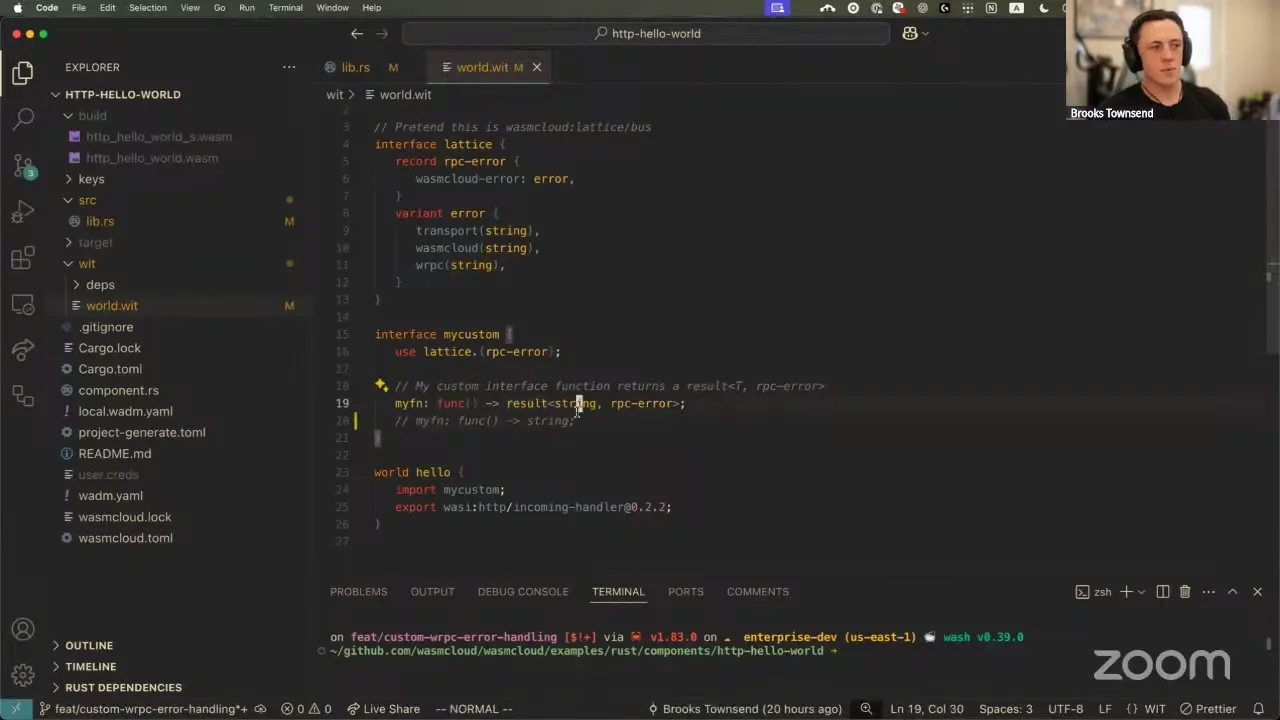
So inside of this component, here's an example of what the code would look like as part of handling the HTTP request. I will essentially call my custom function. Today this either works and I will get a string back, or it will panic and the execution of my component will stop right here — your HTTP request will hang, things like that. But with this implementation, what we can do is use any component language's error handling and say, "hey, if this was okay, then I can return a response like, okay, hello from Rust or Bob or whatever." Now, if there's an error, we can actually return — well, normally you'd want to return a 500. I'm returning a 200 because of a test, it's a little easier to reason with here — but you return a 500 error response and say, "hey, I wasn't able to call this other microservice, this other function that I depend on, because it wasn't running, or I was disconnected." So this long-winded spiel is just getting to the point where this custom interface function now can surface platform-level errors that we wouldn't be able to handle previously — things that happen outside of the WebAssembly function call context.
Brooks Townsend 11:51
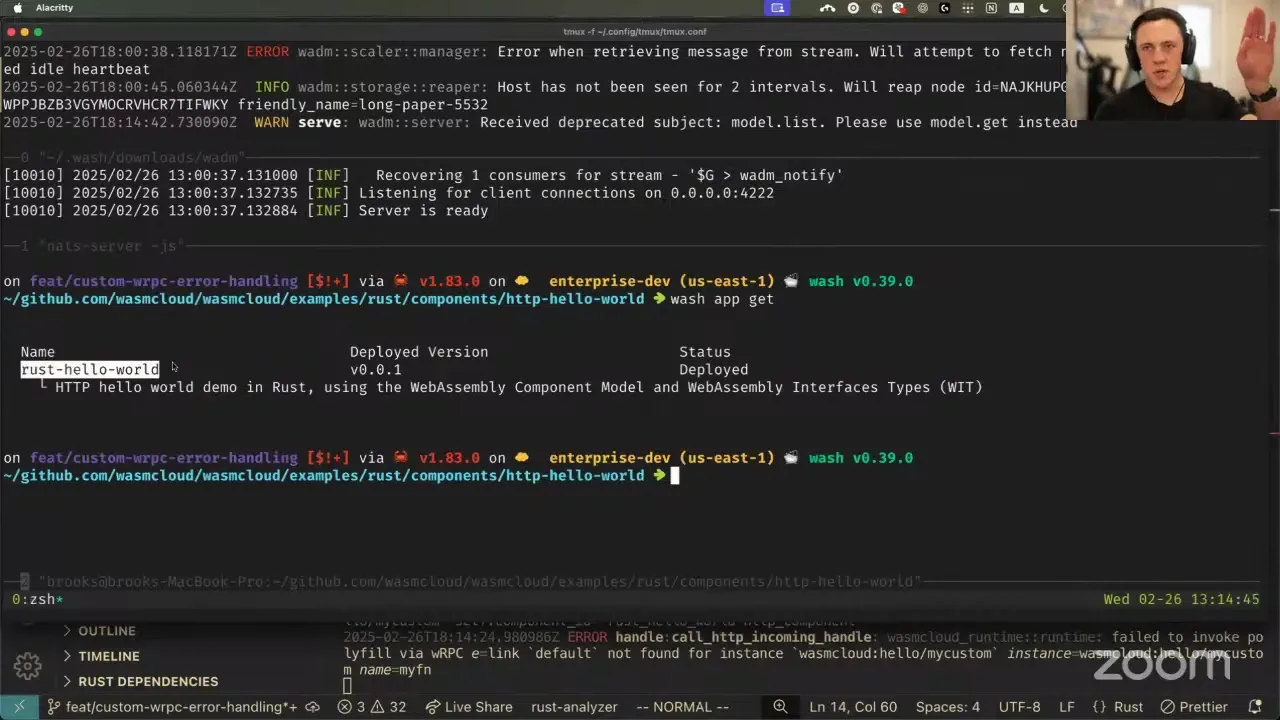
Let me show you what this looks like. I'm going to start a wasmCloud host, and this is going to enable the built-in HTTP server — that's what I'm going to use for my capability provider — and set the max execution time of a component to one second. So if it's executing for longer than a second, then we will kind of time that out, and you'll see why in a second. I have lots of debug logs. I'll be clear that this is essentially a user-experience proposal more so than a feature that's ready to land right now, but I'd rather talk about it first.
So let me set the stage a little bit better. I have a single application, which is just Rust hello world, and in this app it's taking an HTTP request, but I don't actually have a link or any other component that's implementing this custom call. So when I make the RPC call at runtime, it's not going to resolve to anything. There is no target. So previously, this would panic. Now the super cool thing I can do here is send a request, and the response I get back is essentially my error-handling response in the component, printing the whole thing out. But the feedback that the component gets is: "hey, you actually don't have a link to be able to invoke this function. You cannot call this instance. You're not allowed to." So what I could actually do here, if I know as a component developer that this custom interface may fail, is have backup plans, handle that, and then move on.
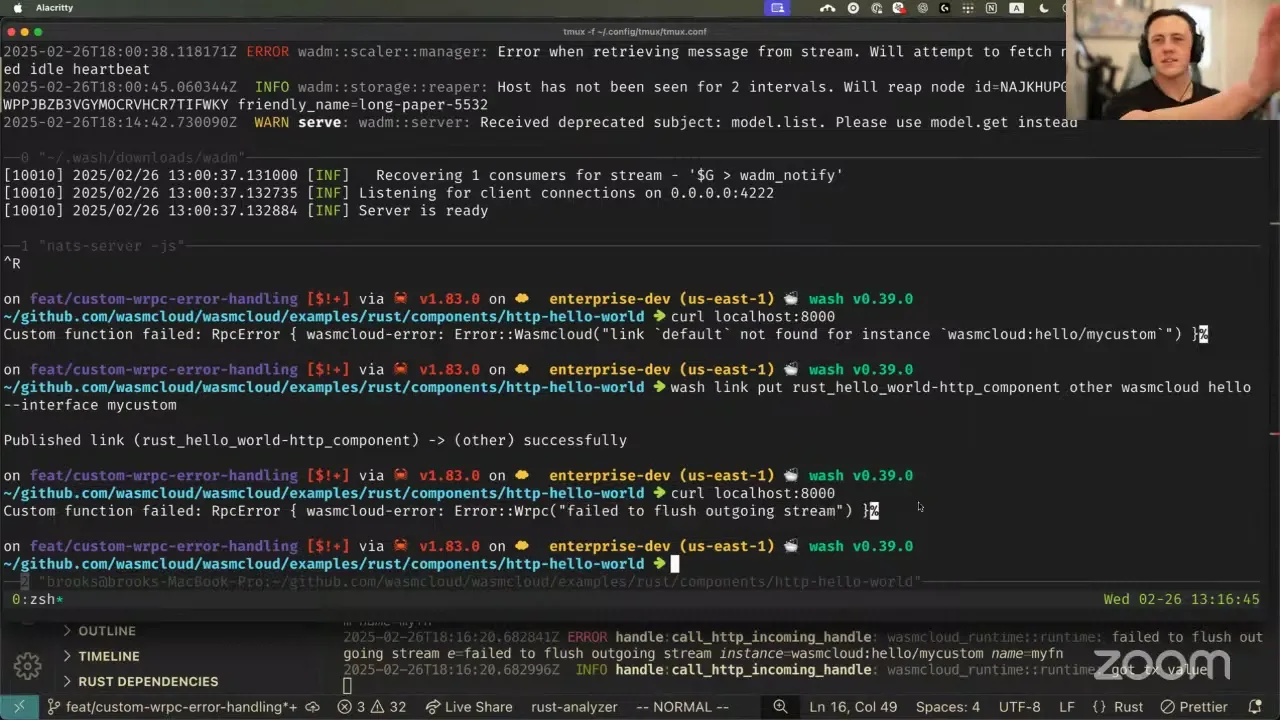
Now there's a variety of scenarios we can catch with this. One is that this link doesn't exist — I wasn't allowed to talk to that entity, and I can handle that. I can also handle the scenario where I have a link, so I am allowed to talk to this other component, this other function, but it's not running. In that case right now, what you'd essentially see is the same behavior — we would try to invoke a component, but you would not be able to actually handle the error that it wasn't running. This is totally just the error that comes back from the current handling process: "failed to flush outgoing stream." But knowing this about our distributed invocation process, we know that if we're failing to flush the outgoing stream — to send arguments to a target — then it's probably not running or not connected or not listening. So I'd like to update this error, but you can now in your component match against an error case and say, "okay, if there was no target for this dependency or this function, maybe I try again, or maybe I wait half a second, try again, exponential backoff," what have you.
There is another case we can actually catch with this, which is really cool. Right now I'm using the built-in HTTP server, which does not transmit the HTTP request over NATS. I can actually quit NATS entirely. You can see at the bottom that wasmCloud is going to keep trying to reconnect to NATS, and I can try to curl this. After a second — which is the timeout — we will return the error that transmitting data has timed out, and that's because when we called this function, it went for a second, totally timed out because we couldn't connect to NATS, and then we can return that result back to the caller. So this is pretty resilient. I think this would go a long way to making custom interfaces really resilient on the wasmCloud side. We can bring back up NATS and wasmCloud will reconnect and all that fun stuff.

But really, I think the reason why we need this today is: if a custom interface fails for reasons that are outside of its standard interface — such as RPC — then we really want to be able to surface that information to the component, to be able to handle it, try again, things like that. One other important design piece here: something we want to make sure we preserve with this feature is the ability to compose components together — not just with wasmCloud, but with the WebAssembly composition tooling, or with wasm-tools compose. We really want to be able to preserve that, and we don't want this to be so tightly tied to running in a wasmCloud environment per se. Now, if you're making your own custom interface and you want to handle RPC errors, then you probably are running it in wasmCloud. But we don't want to preclude you from optimizing your components later by composing them together, and this will actually work totally fine with that. So across the component boundary, this result of string, RPC error — or result of T, RPC error — isn't going to really be anything. It's just going to be immediately unwrapped. When you compose these things together, you would just always return the okay result. This RPC error would essentially only get surfaced when you're running the component in wasmCloud and there was a problem during the actual invocation process. So that was one important design consideration there.
So this is totally a demo that is homegrown, freshly written code meant to spur some discussion or thoughts. Do folks have any questions, comments, things they'd like to see out of the custom interface implementation that we have in wasmCloud that we should discuss?
Brooks Townsend 18:15
All righty, that sounds good. I know this may be one of them quiet community calls. This is definitely going to come up again. Oh, Colin, go ahead. Oh, I can't hear you.
Colin Murphy 18:32
Just trying to unmute myself.
Brooks Townsend 18:34
Yeah, thanks, I appreciate it. You know, this isn't an open PR. It's not really getting merged in immediately. I'd really like to talk this over with Roman on the wRPC side, just to see if this belongs in wasmCloud. This may belong as a part of wRPC, something that is kind of well-known and handled there. I want to make sure that we're following all the best practices. The only other thing to mention is that wasmCloud being able to handle this special well-known RPC error — you essentially opt into this in your custom interface by making it the error variant in your result. If you didn't do that, if you just had a custom interface that returns a string, that's totally fine — you can continue to work with the custom interface support as it works today. Thankfully, WebAssembly is pretty flexible with that, so we can add this at any time without breaking previous workflows.
Brooks Townsend 19:58
All right, well, I think if there's nothing else there, then I'll probably be throwing some of these ideas around in the wasmCloud Slack over the coming week or two, just to get some extra feedback. Maybe tease out some example use cases. This would be really useful for things like maybe even the wasmCloud Postgres interface, to catch RPC errors, which would be pretty interesting. But probably more to come here — we'll talk about this one again.
All right, then we can go ahead and move on. I had just two fairly quick discussion items for the rest of the call today. One of them is a call-out that KubeCon EU 2025 is coming up probably really fast. It is almost March, and that happens like the first week of April, so kind of wild.
Colin Murphy 21:08
Oh, right before it too — Wasm I/O, the week before. Just, you know, if you want to come, you're right. I'm going to be there. Bailey's on the speaker list — at least she was. I don't want to speak out of turn, I'm not going to speak for Bailey.
Brooks Townsend 21:46
Wasm I/O in Barcelona, which would be great. I don't think I'm going to Wasm I/O, but I will be at KubeCon. I can't search this session list for "wasm" because, well, everything comes up. But on the KubeCon list, there is a ton of stuff on the Wasm front, which is exciting — everywhere from TAG Runtime efforts in the CNCF, which Taylor will be talking about. I'll be talking a little bit about wasmCloud and our journey to WebAssembly standards, which should be fun — an overall retrospective on wasmCloud as a project. Liam will be there talking; Joonas and Colin talking about SPIFFE and workload identity for WebAssembly workloads. So that's pretty cool, very topical.
So tons of stuff coming up here. There are two real call-outs, I guess. One: if you're going to be in Barcelona slash London, please let us know, because we'll be there and would love to come grab a coffee, beer, grab a high-five, whatever — you should come by the booth, come hang out. It's always great to meet people in person. And since we are coming up on the last month before the conference, I think it's pretty likely that we're going to be really busy. So in the coming weeks, the wasmCloud community meetings may be a little bit shorter, or some of the demos might be quicker — maybe little previews of our talks. But this is a general call for help, maybe the wrong word: if you all are working on things and want to fill out the demo slot in the wasmCloud community meeting, that will always be appreciated. As a reminder, everybody is welcome to demo. Is there anything else I'm missing on the conference front?
Bailey Hayes 24:08
I just want to give a shout that we can also play video recordings if you want to demo but this time slot doesn't work for you. Thinking of folks like Ahmed, who are just awesome and have made lots of really cool things — we would love to highlight you. On the conference front, I've seen Luke's slides for his Wasm I/O talk. It's a classic Luke presentation, insert-meme-there, but it works, it's really good.
Colin Murphy 24:43
That's just shorthand for "you need to watch it again after he gives it." At least that's how I interpret that, in a good way. It's so pithy.
Brooks Townsend 25:05
I'll watch it five more times sitting in a nice chair. We gotta get back into doing live streams at the conferences — it's pretty fun. Of course, we'll do the wasmCloud community meeting there.
Colin Murphy 25:21
Yeah, that's always fun, and short usually — unless people don't want it to be.
Brooks Townsend 25:28
Yeah, no, we're always gonna do it. Okay. Other than that, the only other thing I wanted to show off a little bit is — I'm not sure if you all have submitted PRs into wasmCloud over the last week or so, but all of the efforts that we went through to update our labeling process have landed, and they're in main in a super cool fashion. Essentially, what we're doing now is when you create a pull request into the wasmCloud repo, our conventional commit bot is parsing the commit message to make sure that it's conventional. This is something we do across the entire repository, and we enforce this — and you all have been awesome for helping us do that as well.
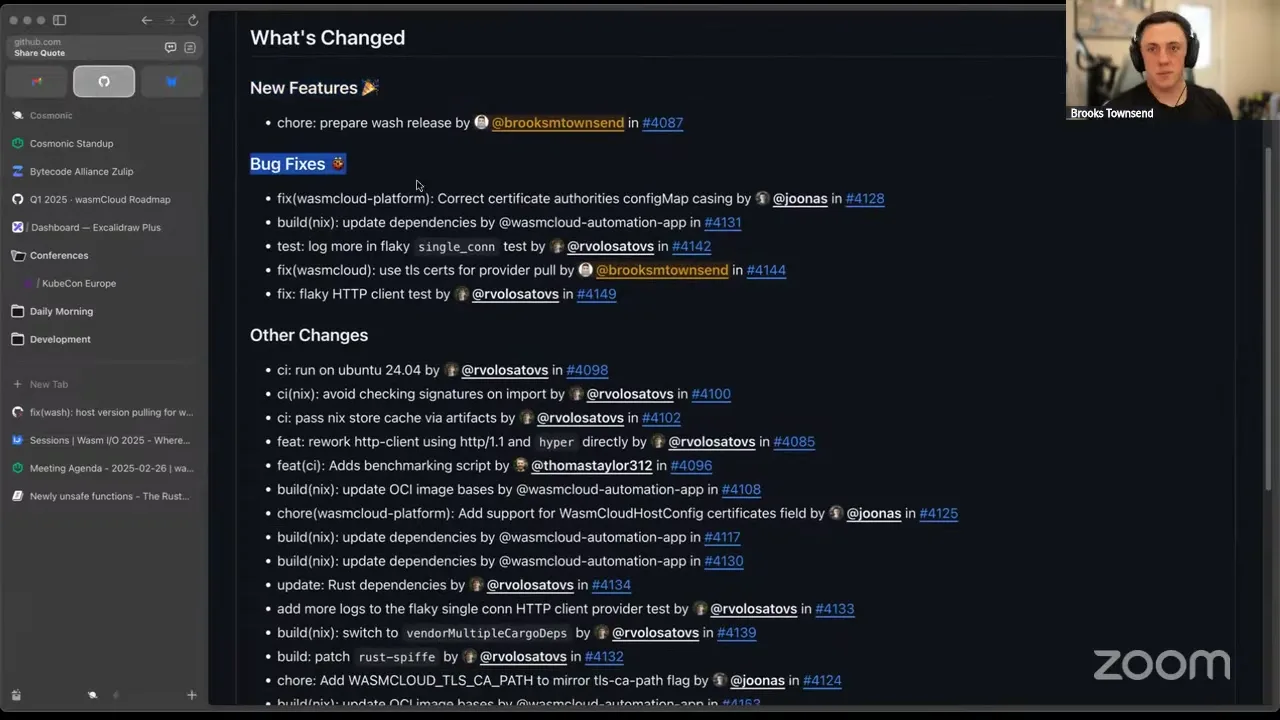
So Aditya comes in and makes a commit and says "hey, this is a feature add for the host, adding runtime support for the cron provider." The GitHub Actions bot can parse this and say "hey, the scope is wasmCloud, and this is a feature," and that's really nice — just at a bird's-eye view for us maintainers who are reviewing things, we now know what the pull request is about. We can also know, here's one from Victor for example, if it contains a breaking change — which, of course, is elective, something you have to put into your commit message, so it's important to show rigor there, but it can be important for us to know when we need to do releases.
What is cool about this is, once these PRs merge and we cut releases — like, for example, the 1.6.2 release notes — we now have a formatted release notes section. What's auto-generated by GitHub now is a section for new features, a section for bug fixes, and then all other changes roll up under a more bulk section at the bottom. If there are any breaking changes, that actually comes all the way up to the top. There haven't been any — this is a patch release — so that'll be good for keeping us honest. Essentially, that gives us a really nice view into what changed in a release, and that is all driven by the labeler, and then also this release.yaml, which GitHub uses whenever you generate release notes for a repository based on labels of a pull request to stick them under different categories. We are going to be ignoring things like CI changes in our release notes and dependabot version bumps, which should just generally result in a lot cleaner release notes.
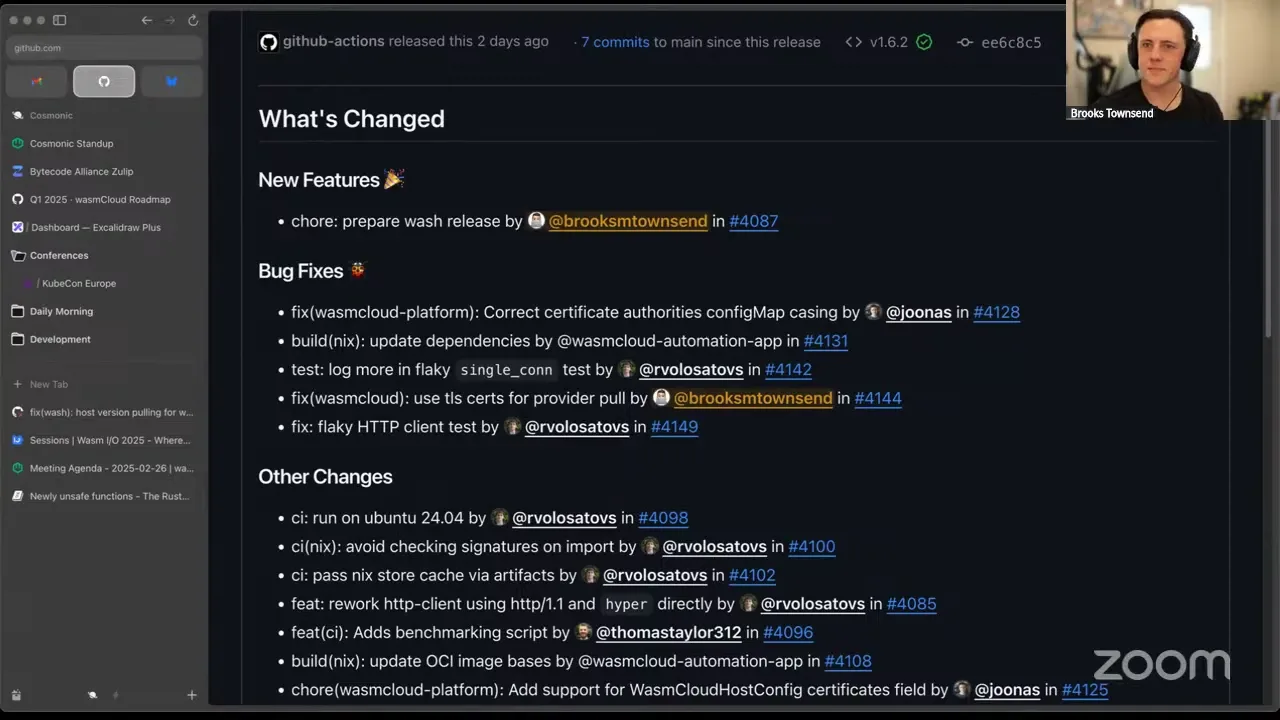
The only thing I think we need to keep an eye out for is the title of the pull request. I kept this in to make a full example of myself — you can see under "new features" this is really weird: why is there a chore for a prep release by myself in here? That is because in this pull request I had a bunch of different commits. Three of them were just regular version bumps, and the other one was a feature where I said "upgrading these versions." So this is a lesson to myself and maybe others as well, that the title of the pull request is going to be really important in our generated release notes. Here I probably would have altered my commits just to make them all chores. But this should be really helpful for general parsing of release notes by regular people. This should happen automatically for our releases from now on. Happy to take any feedback on this process or the release notes. Do folks have any questions or comments on that one?
Bailey Hayes 30:22
Yeah, nice.
Brooks Townsend 30:26
All right. Well, we kind of rolled through the agenda pretty quickly today, but that's okay. I had a fun time talking to everybody here today. Now we have a lot of extra time, though — is there anything that folks wanted to bring up from the wasmCloud side, questions that they had, things in the broader WebAssembly ecosystem they wanted to discuss? We got some free time. So, ossfellow, go for it.
ossfellow 31:02
Hi Brooks, question about internal and external providers — how that differentiation is made, both in the manifest as well as by the host, that you're referring to an internal provider and not expecting an external provider.
Brooks Townsend 31:28
You're saying like when my demo used the built-in HTTP server versus the... okay, yeah. So I really like the way that this determination is made now. We actually treat the built-in providers — and you may or may not know, we just have two, for messaging and HTTP server — we treat them the exact same as the discrete or binary capability providers. The only difference is the image reference. So instead of referring to the ghcr wasmCloud HTTP server, here we refer to the special syntax as wasmcloud+builtin.
ossfellow 32:24
I want to start on that HTTP client, and I was asking myself, how can I test this thing?
Brooks Townsend 32:36
Yeah, that's great. I'm glad to hear that work is starting. I would recommend just following the same convention and doing this for the HTTP client. I'll have to see — nope, that's in the test. That is also in the test. If you look for this built-in syntax, here it is.
ossfellow 33:07
I know what to look for now. Thanks.
Brooks Townsend 33:10
Yeah, sure. So this is kind of how we've been doing it, and then the important thing is just configuration matching up one to one, so that there really is no difference between it. Great question.
Colin Murphy 33:28
Yeah, there has been a lot of work that's been done on the wstd standard, and I know in the past we've talked about it, especially around HTTP — it's actually very useful now. I'm even going to talk about it in Barcelona a little bit. I didn't know — should we update examples to use it, or do we want to wait? I know we can use it in wasmCloud. Let me see — yes, that crate.
Brooks Townsend 34:04
Yeah, wstd — "worsted."
Colin Murphy 34:08
It's kind of like reqwest. On the issue that you filed, the reqwest PR — Brooks, people have mentioned it, talked about it a little bit.
Brooks Townsend 34:15
Yeah, I've gone back and forth on that one. Just to give you an update on where that work is: I haven't really been able to find the time to go back and update that reqwest PR. I think it was good, if not maybe a little misguided, because it was basically a synchronous implementation mixed in with the asynchronous bits of the reqwest library. So there was definitely a need to change that PR to make it fit into the crate more properly.
Colin Murphy 34:59
Yeah, I mean, within the last few weeks, work's been done on the wstd that you would probably want to use.
Brooks Townsend 35:06
Yeah, I'm interested to check it out. I actually haven't gotten a chance to play around with a lot of the wstd stuff, especially around HTTP, so I'd be pretty interested to play around with it, just to see how it feels to use it for a component to just run in wasmCloud, straight up. And it could be the underpinning of reqwest too.
Colin Murphy 35:35
Yeah, I think I've made a bunch of recent PRs in the last week using it, in ctpa. But obligatory: if it uses a reference — yeah, I don't really, I'm not a self-promoter, but all I've done is promote my talks and the things I've done.
Brooks Townsend 35:57
Oh, no, that was on YouTube.
Colin Murphy 35:58
So I think I'm in the right place. Please, like and subscribe.
Brooks Townsend 36:05
I was saying "obligatory" because I was gonna say, hey, of course, if it supports wasi:http, it works in wasmCloud — so I was gonna self-promote too. Like, comment, and subscribe. So I'd love to get a couple of examples going. I think maybe the example was the HTTP Rust thing that Bailey just sent — probably just works out of the box. We really could just start changing some of our examples to run the same.
Colin Murphy 36:43
Oh no, it definitely works out of the box. I just was looking at the examples, and then Bailey put up an example.
Brooks Townsend 36:54
Yeah. Bailey, I'm not sure if you had more on that topic, or if you were queuing up another thing.
Bailey Hayes 37:01
Basically, what I was going to call out is that within the Bytecode Alliance, we've been working on building out some more canonical examples. Yash, who's also the creator of the wstd crate, owns this Rust wasi:http example. It's got a lot of other goodies in there that I think is really worth looking at — like how to have a generic approach for building your OCI images for your WebAssembly components, and then that whole workflow is sort of integrated in if you use that template, and it also has signing built into it as well. And a dev container — there's so much stuff in that one that if you haven't seen it, please do. And if you have a favorite language that we haven't yet represented in the Bytecode Alliance, which is all of the other ones, please come and talk to me — and SIG Docs would like a word, because we want to expand that suite out. So thank you.
Brooks Townsend 38:06
Spreading the good word, nice. Yeah, Aditya, go ahead.
Aditya 38:15
Hey Brooks, so as you know, I've been working on the cron job provider, and I was just wondering what the chronology would be for getting the WIT package released as a tag and the actual provider getting implemented. I just wanted to know which comes first.
Brooks Townsend 38:35
Yeah, I think what you should be able to do is just implement the capability provider using your local implementation of the cron capability. This is what we did for Postgres as well, which is basically a custom interface like cron. You should be able to test it in the repo just fine with that. And then once the PR merges — which we can help with — you might want to look at the Postgres release WIT action for inspiration. But once essentially all of this gets merged, we can release the WIT and the provider basically at the same time. That's what I would think, at least. You should be able to implement the provider, prove it out, and then we can release the WIT once that all lands. Does that make sense? Is that what you were looking for?
Aditya 39:47
Yeah, it does make sense. I was just taking a look at the secrets workflow as well, and I'm seeing that it was done after it was implemented. So yeah — get it working locally and do the rest.
Brooks Townsend 40:06
Okay, yeah, that sounds great. I saw that capability provider — the cron job provider PR — is in draft, so just let us know whenever you want us to take a look.
Aditya 40:23
Yeah, sounds good.
Brooks Townsend 40:30
All righty, we did pretty good, right? We did the thing. It was great. Thanks everybody for coming to the wasmCloud community call today. It'll be very hard to wait a whole week before the next one, but we'll all find a way. We'll do some more demos, more discussions, and talk more about fun WebAssembly things. So thanks, everybody. We'll see you next time. Have a good day.