Transcript: Robust Rollouts & Rollbacks for the Wasm Component Model
wasmCloud Weekly Community Call — Wed, Feb 19, 2025 · 57 minutes
Transcript
Brooks Townsend 03:53
Hello everyone. Welcome to wasmCloud Wednesday for Wednesday, February 19. Let me go ahead and share the agenda. We've got a couple of good discussions today. No demo that I'm aware of, but like I've said before, anybody's welcome to do a demo at any time, so I'll take an impromptu demo. It's all good.
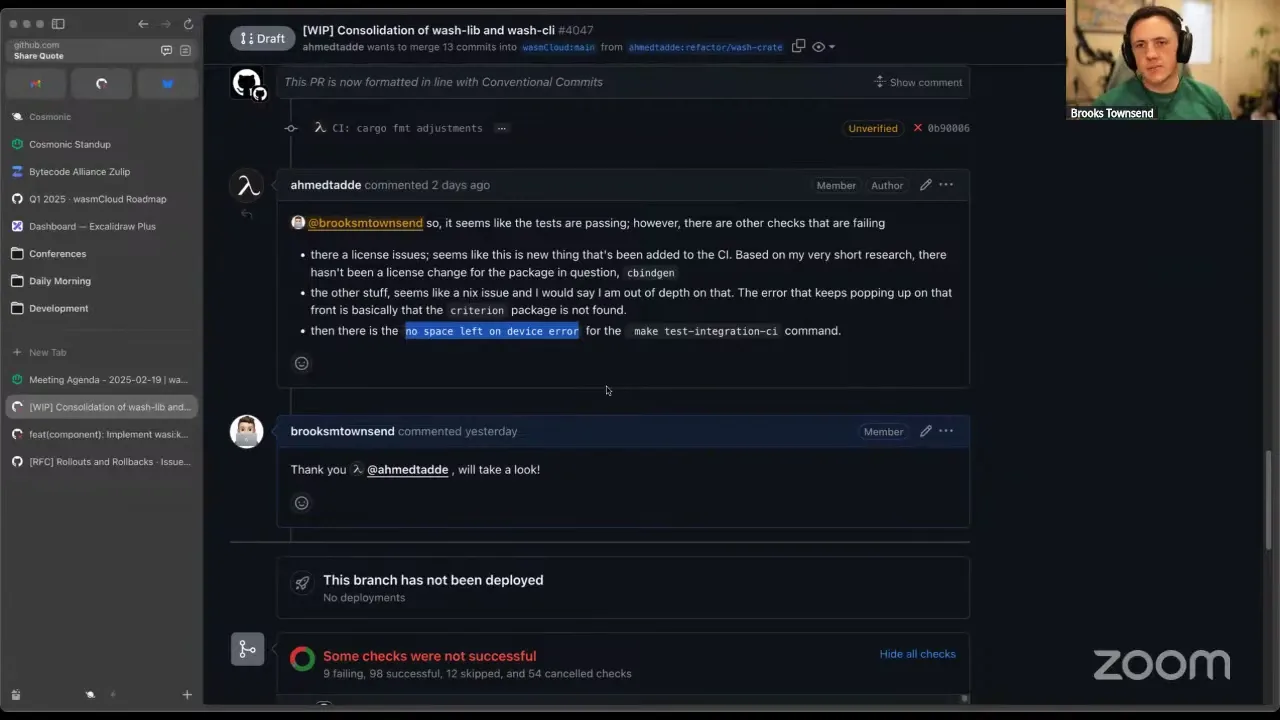
So I'm taking a look at the agenda today. There were a couple of things I wanted to discuss. The first one is an item we talked about last week, which is combining the wash CLI and the wash library — the two separate crates in our repository. Thank you again to Ahmed, who is a wasmCloud maintainer, for taking on this work. I know that it's like the yak shave of the century, but it's a huge help, because it's just going to increase our ability to release wash quickly and easily. Last week we mentioned that, for now, if possible, let's try and avoid making big changes in the wash CLI crate and the wash lib crate, just so we can get this refactor done and then port the changes over. If there's a critical bug fix or something like that, it's really no issue — I just want to ease Ahmed's pain on rebasing. This work is moving along really, really well. The freeze has been going great. I think the only change causing some conflicts is that we need to rebase off of main, but I've bumped wash to release 0.39, which, as far as we can tell, will be the last release before we combine everything and release that as a single binary.
I did, however, want to call attention to some of the things in the workflows that are failing, because these might be affecting other PRs in the wasmCloud repo right now. First of all, as a CNCF project and an open source project, we need to make sure that since we're Apache-2.0 licensed, we're using libraries that are all compliant with that license under the CNCF standard guidelines. They have a list of software licenses they're cool with, and then a list you essentially need to get approval for. The cbindgen crate is under the Mozilla Public License 2.0, which is fine — there are a lot of CNCF libraries that essentially have an exception granted for it. Roman did go through and remove one of our crates that was using cbindgen, so that should help the license issue. We're going to take a look and see if we can either remove the use of that crate for now, or start the process to get a license exception with the CNCF, which is not a huge deal. I just want to handle it out of band of this PR, because it doesn't feel related. So Ahmed, if you're listening — or if anybody's hitting a license failure — let me know and we'll see what we can do.
Other than that, there are a couple of other failures in CI that are not related to this change. It looks like there's an issue we've actually hit before, where the CI runner runs out of space when running integration tests. So I'm trying to take a look into this. I might tap Roman, who has designed a lot of the CI for the wasmCloud repo, to touch base and see if we can figure it out. And Adi — this is a separate contribution, but implementing the key-value watch in the host and in our capability provider for Redis — this is all functionally complete. It's awesome work. I noticed your PR is hitting a failure here, so in lieu of doing a ton of live debugging, I wanted to let you know there are a couple of fixes going in right now relating to how we deal with Cargo.locks, and there's one integration test on the wasmCloud host side that we're debugging. This is really all just a PSA that we're taking a look into these things. I'll let you know when you should rebase to bring in some fixes from main, but thank you so much for your patience. We should be able to get this approved, merged, and all that.
So, wrapping up the wash story: I'd really like to push this along as soon as possible, because the longer these branches live out there, the harder and harder they get to maintain. So Ahmed, I'm going to try and get back to you as soon as possible on some of these issues — see if we can reproduce them, fix them, all that fun stuff. But let's push this forward if we can. This is great. Do folks have any questions on CI? Do you have a pull request that's been blocked, anything like that?
Brooks Townsend 10:00
All right, everybody's favorite topic — talking about workflows and CI. Okay, then that's all that's really there. Let's continue to hold off on doing any big features or fixes in wash for now so we can get this across the line, and we'll go from there.
So, moving on to the next discussion item: upgrades and updates for wasmCloud applications. I'll come off of share for a moment to address all of you. We have some notion of updating components in wasmCloud today. We have a control interface operation called update component where you take a running version of a running component — let's say OCI version v1 from an image reference — and you can update it to OCI v2. What the wasmCloud host will actually do is download those new bytes from your OCI registry or image reference, instantiate the component to make sure it's a valid component, all the claims and signing verification passes, and then as soon as that new component is ready, we hot-swap in the newer version and complete the upgrade. So this does a zero-downtime upgrade. No invocations are lost, because we don't actually change subscriptions, we don't change configuration — we just update to a newer version of the component. And this works pretty well. We actually don't do this in wadm, and we don't do this in wash dev in order to upgrade to a newer version, but it is there and you can use it to go from one version to the other.
Now, doing this type of upgrade is often more complicated than just going from one version to the next if you are changing configuration — say, to listen on a different HTTP port or path, adding additional configuration, say your application now has the ability to work with a key-value store, or you're rotating the credentials to interact with a database. There are many different scenarios you can dream up. This doesn't really do that — you have to update the component and put the configuration, links, etc., separately. And herein lies part of the problem. It's really hard. There's not an official mechanism in wasmCloud right now to do this, and I think it's truly something we can have control over. When you get to running these wasmCloud applications in production, you don't want to be taking on an arbitrary amount of downtime. You want to be able to recover from failures and roll back, and you want to know that when you deploy a new version of your application or component — assuming you've already tested it — that rollout should complete, and you should have insight into what's happening there. So I have a fairly large RFC that I've written up in the wasmCloud GitHub repo, and dropped in Slack this morning. There are a couple of different pieces to this RFC, so I'd love to talk through, at a really high level, what's included, and then take any feedback, questions, and comments — especially from the folks running wasmCloud. This RFC details the work we need to do past just the update component operation, so we can have really robust upgrades from one set of components and configuration to the next, and then vice versa — rolling back.
Brooks Townsend 14:10
I've introduced the motivation here, but the work comes in a couple of different parts, and other than the last step they don't really depend on each other immediately. The first thing I'm proposing is that wasmCloud should report the status of running components and providers in its host inventory. Here's what an entry in the host inventory looks like for a component: you have the component ID, the image reference it came from, the scale it's running at, and some nice friendly information like annotations. But you don't actually know if the component is running, stopping, or upgrading — none of those are really valid cases for the component right now. It's either there or it's not. I think for capability providers and components especially, it would be very helpful to report the status of these things at all times. As soon as you send a request to scale a component on a wasmCloud host, I think it should immediately pop up in the host inventory as pending — as something that's downloading from OCI.
Right now, when you tell a host to start a component, you get an ACK that it was a valid request and that it's working on it, but then you won't hear any other information about that request until an event is published on the wasmCloud event bus. So you have to send the request and then listen for events. That's generally okay, but it can be a little more annoying if you're downloading something large, like a capability provider, when you're on plane Wi-Fi — though that's a really specific scenario. What I really want to surface is a general set of statuses in the host inventory: failed for when it fails to download from OCI, unhealthy for when a capability provider says "hey, I'm unhealthy." This is information you can kind of see in the wasmCloud dashboard today. This would all be backwards compatible — it's just a new field. So no real big changes there. But essentially, you, as a person interacting with wasmCloud, or as an operator like wadm, would have more information about what the host is doing in its internal state — figuring out more than just taking a look at the logs; you can actually query for that kind of information.
Second — and this sounds like a bigger change, but it really is just moving the separation of concerns — I think we should try to avoid using the control interface commands that instruct wasmCloud to write to the NATS KV bucket, which is the lattice-wide state. Every single host running in the same lattice, or the same networking namespace, connects to two KV buckets: one for information about components and links, and one for configuration. This has some really nice properties — I actually have a nice diagram. We can share information across all wasmCloud hosts running in the same lattice using this replicated KV data store, which is in NATS.
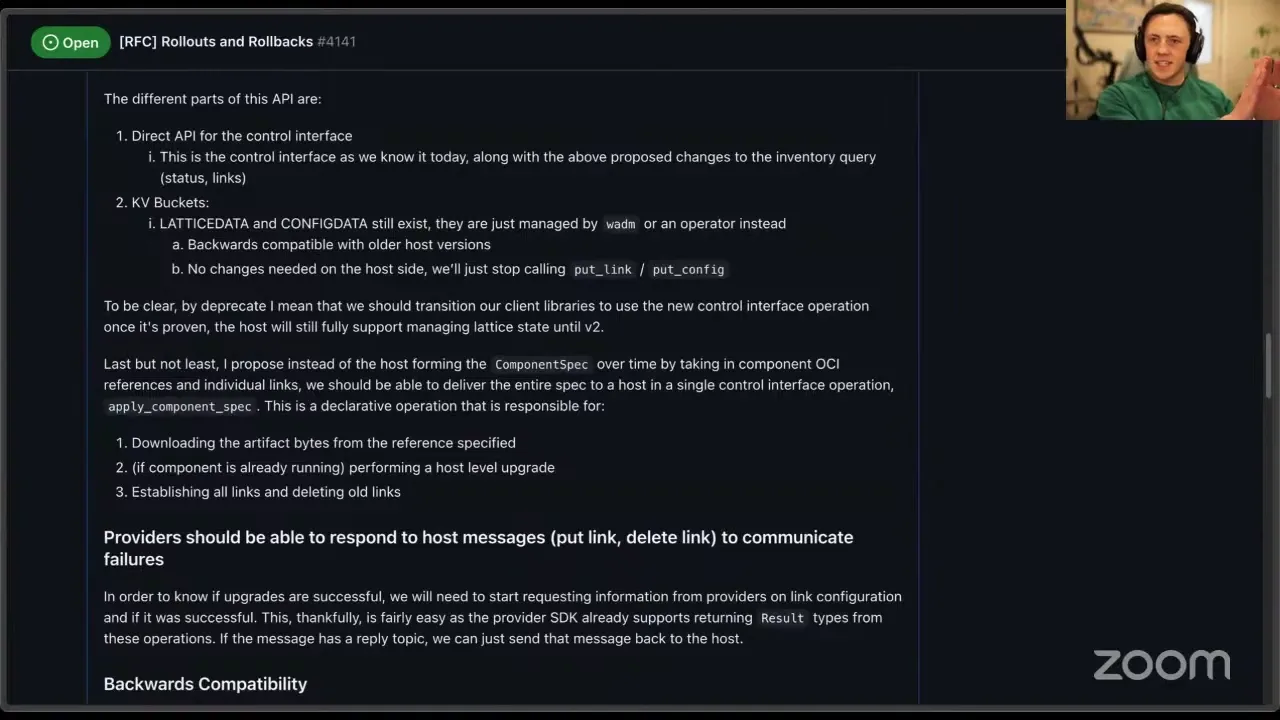
The problem is that these hosts actually write to the KV bucket as well. So if I tell host A and host B to start a component, and then I start sending out links or configuration, both of those hosts are going to be writing to the same bucket at the same time. This rarely ends up being an issue — NATS KV is pretty good about catching you if you try to write to a key that's been written to since you read from it — but it can still happen. A big downside is that when one host writes to the source of truth, the other hosts essentially have to respect that and don't have an opportunity to reject configuration or reject links. In theory it should all be the same for many, many scenarios, and it is. But what I'm proposing is that we keep the lattice data and config data buckets as they are — as a source of truth, something we can use to communicate things to hosts — but we attempt to stop using the link and config put operations where the host writes to the data buckets, and instead start introducing new wasmCloud control interface operations. I've dubbed it v2-alpha-1. We can call it whatever we'd like, but it would introduce some new operations that bypass this. This would also be a backwards-compatible change with older host versions, because the host can still support all of the old things it used to — we're just adding in some new operations.
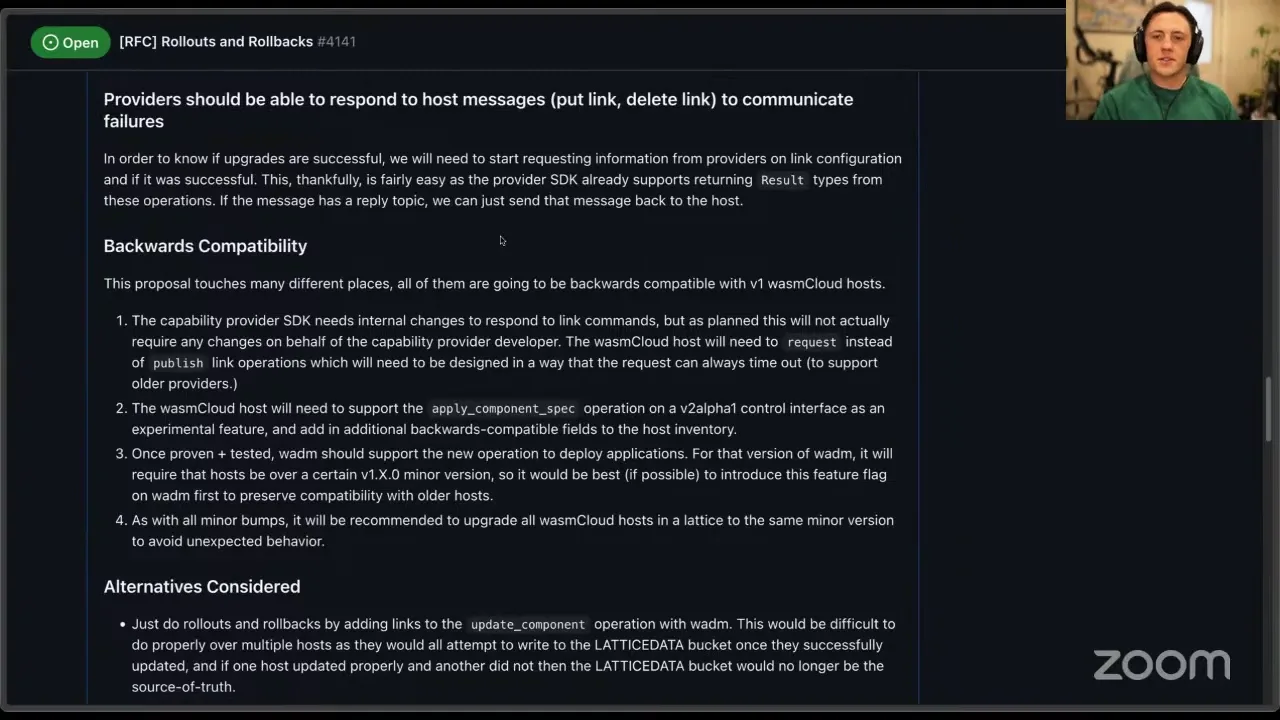
I think this one operation specifically — apply component spec (and I guess we should have a delete too) — should be something we experiment with. It should be an experimental command and we see how it works. All of this work is beneficial even if we don't like the design of a particular piece. So the last piece I'd like to touch on is something you may or may not know about the internals of how wasmCloud works. When you start a WebAssembly component and configure all of its links by publishing commands one at a time to the host, wasmCloud is essentially taking all of that information and creating a single spec — it's called a component spec — that has all of the component information, all of the configuration, everything it needs to execute at runtime. It stores that, and all of the other hosts get it. Essentially, all I'm proposing here is to shift the responsibility of forming that component spec to wadm, to wash, and to our client libraries, and put all of that together and ship it to the host as a single bundle. There's no real restriction — you could use both APIs — but what this does is let us deliver all of the information for a single component deployment at one time, and then the host can reflect its status based on that.
I'm almost done, so I'll pause for a question just after this last one, which is maybe a little less internal or abstract. Right now, when we tell a provider to put a link, to delete a link — essentially to configure itself for an application or component — those are fire-and-forget operations. The host sends the message out, hoping the provider is on the other end receiving it, but that's all it knows. The host actually does not know if the provider is configured correctly at all, and I think that's a big problem. The change I'd like to propose, so we can know that rollouts are working correctly, is making this a request. It really is not a big change. We're going to send a request to the provider, and then on the provider SDK side, in Rust and in Go, we can send the response back. The good news is this actually doesn't require any changes on the provider side at all — if you've built a capability provider using the provider SDK, we already let you return results. Previously, if you said "hey, I couldn't configure this because I couldn't reserve this port," we would log it; now we're actually going to send that message back to the host, and all of that is going to roll up into the host inventory or these queries. So you can say, "hey, you deployed your component fine, your HTTP server is running fine, but when you tried to configure your connection, we couldn't find the certificate you were trying to use for TLS, so this application has failed and you've got to figure that out."
About half the changes in this RFC are improvements on today's current system. So even before we get to the rollouts and rollbacks, observability on what providers are able to do, and shipping more information at the same time to the hosts — those are going to be wholesale improvements. We can start working on some of that even if there are other things we want to talk about. But the rollout-and-rollback piece is the end result of all of this. I'll pause to see if there are any questions before I show this big diagram. Yeah — is the data watch operation event-based or poll-based? This data watch is already happening today. Whenever there's a change in the KV bucket, the wasmCloud host is pulling updates off of that data watch. It's constantly watching to see if there's a change in the lattice data or config data bucket. Everything in NATS under the hood is a message on a stream, so anytime new messages come in — a new configuration is put — all of the hosts are pulling that off the stream immediately. If they go down momentarily and then come back up, they resume the watch from the last key they saw, and they'll catch up on information. Does that answer your question? Any other follow-ups?
ossfellow 26:59
No, thanks. So it's like a control loop.
Brooks Townsend 27:04
Yep, that's a good way to look at it.
Okay, so just to wrap up this RFC — I know there are a lot of points to it — I would greatly appreciate anybody who takes the time to look at the proposal. I know it's a lot to read, but I'm happy to address any feedback around clarity, or things I can describe better, because I want to make sure it's understandable by everyone, even if you don't have intimate knowledge of the internals like the component spec. So at the end of the day, the goal experience I have for a wasmCloud rollout is this. I have a user — bookmarked here as an entity. I have wadm, which is the application deployment manager, the reconciliation loop. I have wasmCloud, which is some wasmCloud host. And then, say, in this application there is a capability provider that has new resources it tries to reserve, because that's an important aspect of the upgrade.
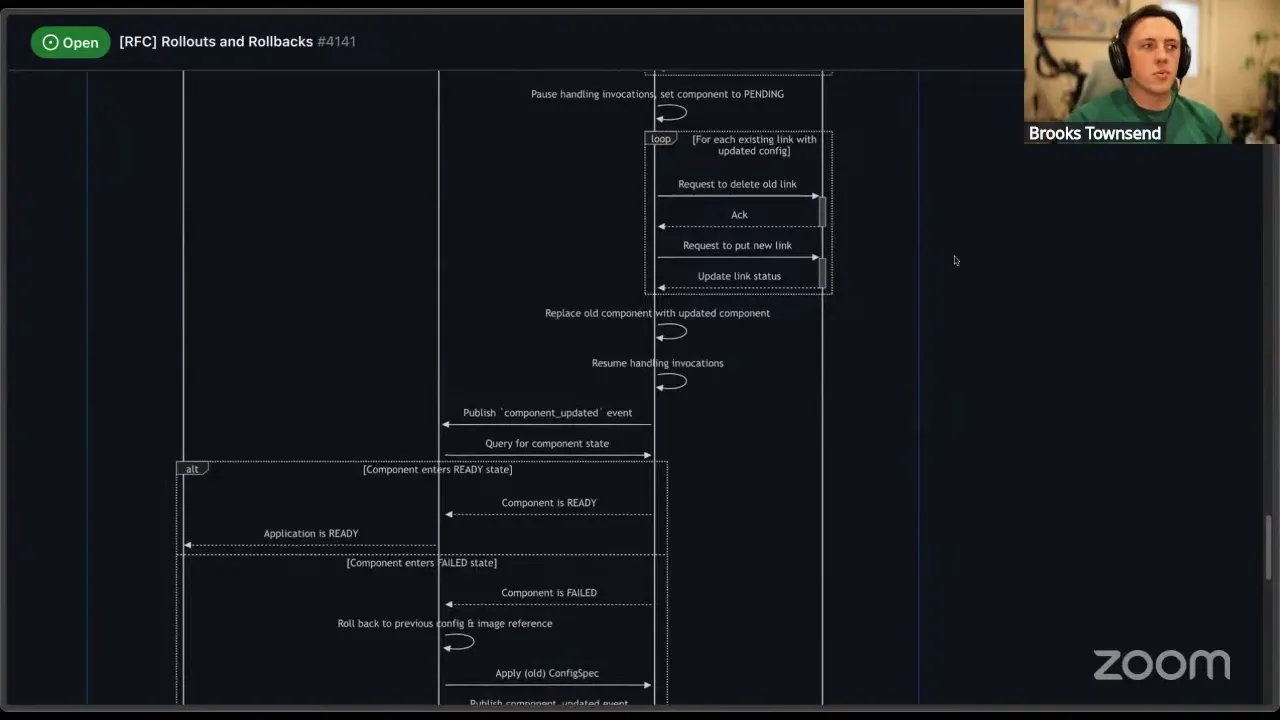
So me, as a user — or CI/CD — says, "hey, deploy a new version of my application." That request is sent to wadm. wadm internally will remove all of the control loop — we call them scalers, the little entities watching for events in the wasmCloud lattice and taking action based on that — so that we're not taking reconciliation action during an upgrade. We'll mark the application as upgrading, then transform the manifest where you're deploying your application into the component spec format. This component spec format will have the ID of the component, the image reference where it's pulled from, and then all of the links relevant to that component. That's the format it is today. wadm will then send apply component spec to the host: "hey, here's your manifest, you need to make sure this is the reality — here's your desired state, go make it happen." There's some older version of this component, the same ID, that's running. So what we'll do is fetch the updated component from the new image reference. Obviously, if this fails, we'll fail the upgrade and roll back. We'll instantiate the updated component — and this is actually a Wasmtime thing, so we'll pre-compile and instantiate the component to make sure all of its imports and exports are valid, that it's a valid component, all of that. So we do our validation, and then for each new link or piece of configuration, we send a request to the providers: "hey, get this configuration ready for this new component." The reason the new-link thing matters is that for each new link there's not going to be any additional state the old version of the component is using, so we can establish those without worrying about conflicts.
Now, for zero-downtime upgrades, this is a pretty critical piece of the upgrade itself. There are different strategies here, but what I've drawn out is: at this point, when we've validated the component is correct and gone through configuring the new links, we set the component to pending in the host inventory. We can pause handling invocations — we're actually still receiving them on the wRPC subscription, we're still receiving invocations, but we're not going to actually execute the old component right now. For each link that has updated configuration — to have the least amount of changes in the provider SDK — we can request to delete the link and then put the new link, so essentially changing the configuration. This one I think we could maybe optimize by having an update config operation, but that pushes a little more work onto the capability provider developer to handle upgrades properly, and that's okay — it might be a good alternative; I have it outlined as one as well. Once we've updated all the pieces of configuration — for context, the amount of time it takes for an individual host to send a message to a provider it's managing is somewhere on the order of a couple hundred microseconds; that's the NATS back-and-forth — the important thing that may take time is establishing connections or host resources. So there are still some scenarios to make sure this works well, but essentially it's not down, it's not missing invocations, it's just pausing on them. As soon as that all works properly, replace the old component with the updated component, resume handling invocations, and then return that the upgrade was successful. At the end, the important bit is that wadm can now monitor this application or individual component for success. If it all went into the ready state and everything got upgraded correctly, we can say the application is ready, complete the upgrade, and resume normal operations. If the component fails for whatever reason — failing to download, failing to establish new configuration, those are the big ones — then wadm can apply the old configuration, which is already hanging out (we formed it from before), and wasmCloud can deal with that rollback.
There are a couple of unresolved questions and conclusions here, but hopefully this super-verbose and tall application rollout diagram is helpful. This is a particularly sticky issue with the way wasmCloud can be so wildly distributed. I want to make sure each wasmCloud host is very focused on being its own agent — receiving a command to start a component and being very good at that — and I want to leave the lattice-wide orchestration of these apps to wadm, the scheduler, which can have that higher-level knowledge. I really do want to stop wasmCloud hosts from having the ability to affect the lattice-wide state. So, many different things there. Questions — Florian, go ahead.
Florian Fürstenberg 35:00
Yeah, many things. So, what was really interesting — and I was wondering, maybe I missed that point — you explicitly mentioned in the diagram the removal of the scalers in wadm in a non-destructive way, but you didn't include the re-initiation or recreation of these scalers in your diagram. Was this on purpose, and is it implicitly part of another step?
Brooks Townsend 35:25
Thank you for that comment. I didn't include it in the diagram, but mostly out of neglect. It does belong there at the end. After we've done the upgrade, we should reintroduce the new scalers, which are responsible for — you know, if I manually tell wasmCloud to stop this component that wadm is managing, then the scaler for that component will say, "hey, no, I do actually want this to be running, go start it again."
Florian Fürstenberg 35:58
Nice. Yeah.
Brooks Townsend 36:05
Do folks have any other questions, general comments, or suggestions for rollouts? It doesn't really need to be about my RFC specifically — if you have a use case you wish wasmCloud would cover in an upgrade, rollout, or rollback scenario, that's infinitely valuable as well. I took some scenarios from folks we're working with who are deploying wasmCloud as inspiration in this RFC, but I want to make sure I cover everything, so please feel free. I'll pause now — ask questions or let me know.
Florian Fürstenberg 37:01
Maybe a follow-up question, then. You mentioned you already discussed some use cases — I didn't read the RFC, so maybe it's covered. But usually people are asking — at least our customers are asking — about canary deployment, or blue-green deployment, something like that. Is this also in scope of the RFC, or something you keep for later?
Brooks Townsend 37:21
Yeah, this is mostly kept for later, essentially as part of the rollout strategy. I mentioned providers a couple of times as being a difficulty, but just to set the stage: it actually would be really easy for wasmCloud to run a blue-green-style upgrade. You'd say, "hey, upgrade, do blue-green, here's my new component reference," and it would be really easy for wasmCloud to take both of those components, run them at the same time, only send invocations to one, and then switch over to the other in response to a command. That only is easy if you're not changing configuration, and changing configuration is only hard because capability providers may contend for host resources. So, annoyingly, one of the ones that comes up a lot is if you wanted to switch your HTTP address from localhost:8000 to :8080, then what happens during the upgrade if port 8080 is already taken — and it is? It's truly a little frustrating, because it's hard for wasmCloud to control those host resources. But I think that once we have this pretty robust configuration swap in place — which will cover the hard case of upgrading with new configuration — introducing canary or blue-green or percentage-based rollouts at the host level would actually be really easy. We could say something like, "if your application contends on host resources, then you need to be careful." That's a hard thing to reconcile. I feel lame proposing that you basically just pay attention and make sure there aren't any problems, but that would be a really nice way to enable those. Does that make sense? wasmCloud is totally able to do this style of upgrade — it would just be something we could really tightly control the experience over, if there aren't changes that may break outside of our control.
Florian Fürstenberg 40:33
I guess so, to be honest. This port example is a pretty good one, but if we consider, for example, path-based routing, there would be fewer possibilities to break stuff — or actually everything is within the scope of wasmCloud, at least from my understanding. So I think it totally makes sense. As I said, usually the Kubernetes and container-based people are definitely asking about that, and I assume this is definitely possible, especially if they use a managed offering. My impression of wasmCloud is that it feels a little bit like a managed solution, because you don't have to worry about so much detail as a user.
Brooks Townsend 41:22
Yeah, that's essentially what we're trying to assert with the benefits of the component model — understanding what is happening inside of an application, and us taking on the difficulties of making it distributed, load-balanced, and highly available, so that you as a developer don't have to worry about the semantics of upgrading. We want to take care of that automatically. There's some level of pragmatism — you can't always chase it — but it would be great for this system to handle that, kind of like in Kubernetes where you don't need to write something into your container to say "if I'm upgrading, then stop handling requests and hang out."
Florian Fürstenberg 42:15
Yep. But also, to be fair, usually third-party tools are used for that. So Kubernetes is not handling that natively — here wasmCloud would definitely be pushing the product.
Brooks Townsend 42:34
I appreciate you bringing that up, your second question in general, because I think it would be great to introduce some really nice upgrade and rollout functionality with the guardrails to say, "hey, when you're updating this component from one version to the next, you have this set of strategies, but here are the things in wasmCloud that you can't update using this strategy." That might give us a lot of gain without losing much. I mean — how often do you really need to change the port you're listening on in production, when you're already behind a CNI and everything? Could be interesting.
So, you also had a question — shouldn't something like this be an add-on? Would you mind, I'm not sure if you're in a place where you can talk, but would you mind adding a little more detail into what you're thinking there?
ossfellow 43:49
I think Florian himself mentioned it, because if you take the Kubernetes model, you use different components for different purposes. In some sense it's like having an add-on or plugin to the core functions of Kubernetes to provide those additional infrastructure services. But going back to that suggestion — we talked about this some time ago; actually Bailey brought it up — about an extension model. And it was brought up also, I think it was Joonas, that if providers are filling that gap, or there are other things we expect in the communication or cooperation between such an extension and the host that doesn't fit the provider model — I don't know — but things like that, where people can extend the capabilities like they do on Kubernetes. And then, let's say if they want to have blue-green, they can use that model of extension to add that, and then it could be shared. You might even argue that providers can fill that gap, or that they need to be enhanced in such a way to fill that gap.
Brooks Townsend 45:39
Yeah, I think it makes sense, and it is part of our responsibility — the wasmCloud control API's responsibility — to have the right operations, the right API, so that a higher-level orchestrator or principal can actually extend wasmCloud. Right now, if you're a super-power user and you wanted to write your own mechanism to do this rolling update, you mostly can, through a bunch of different control interface commands and making sure that works. I think applying the one manifest will make it easier. But yeah — I'm saying exactly what Bailey is saying.
ossfellow 46:41
Sorry — and I want to mention something, to give you an example. Before Joonas gave us that fantastic news, at least from my perspective, that he's working on integrating SPIFFE, I was looking into it, and into that delegated-authentication agent. I was looking at the shortcomings in terms of the current framework we have for extending the host for such capabilities. We see that to some extent in the NATS secrets provider that is running independently, rather than being some sort of standardized extension that provides its own capabilities — such as the wash plugin, in some sense. Over there, one of the things was that sometimes you need that extension or provider to be local — basically enforce it through some policy that it needs to be local to the host, for example for security purposes. That's one of the requirements when it comes to SPIFFE: that agent communications with the agent must be local. They cannot traverse more than one hop.
Brooks Townsend 48:17
Yeah. So you're looking maybe at a combination of a couple of different things, but almost wash-plugin-style extensions for the wasmCloud host, so you can provide your own functionality, the way we've done for something that's well spec'd out and configured, like secrets or policy.
ossfellow 48:41
And it could be common between wash and the host. Because once you provide a capability for a provider for something, you immediately make that available to the plugin, to everything across the ecosystem.
Brooks Townsend 48:59
Yeah. We've definitely opted, for the plugins for wash, to embed components — we have a set interface you can implement. On the wasmCloud host side, some of this predates the component model, so essentially all of our host plugins are done over NATS APIs. We already have the networking infrastructure available; it's just an interface you implement over NATS. This lets you do things like — well, it cuts the dependency down to just a language that has a NATS library. So I think having those extension points at the host in a more WebAssembly-native way may be a good idea. We're not here because we don't like hard problems. I'd like to think about that a little more, because it would be great to extend the host functionality using a custom implementation in more of a WebAssembly-native way, over just having NATS APIs — which is fine, no big complaints there.
ossfellow 50:37
Roman has created all the examples. I have gone through his fantastic wRPC example for different transports.
Brooks Townsend 50:51
Yeah, there are some fun ideas to talk about that we don't have enough time for in the rest of this meeting. But everybody should definitely check it out.
Brooks Townsend 52:03
Do folks have any other things you wanted to touch on regarding the rollouts-and-rollbacks RFC? Like I said, all of this is essentially proposed. I'm planning on moving forward with some of the improvements discussed in the RFC — like providers responding to links, and then proposing a good way to report status — because they feel a little tangential. Don't let that stop you from commenting on those specific aspects, but I kind of view those as more like feature requests, things we should have fixed, maybe before the rollout mechanism. So, do folks have any other thoughts there?
Sweet. I know it's a ton of information, so hopefully the diagrams in there help a little bit. Feel free to tag me in Slack if you have any questions. The thing I was going to say before — I didn't want to rabbit-hole on it too much — definitely go check out the RPC framework we use for wasmCloud, which is wRPC. All of our components do their distributed RPC using this transport-agnostic RPC framework, which is awesome. We do it so components can compose with each other over the lattice using NATS, and you'll never have to worry about it. The cool thing is that wRPC is a protocol, but the transport-agnostic bit means we may implement and use this in wasmCloud today using NATS, but you don't have to. There are implementations for wRPC at the transport level over NATS, over QUIC, over Unix domain sockets, and I see one called WebTransport — which I don't actually know what that means. If this kind of thing interests you, I'd highly recommend checking out the talk Bailey just linked, which was, I believe, Taylor and Roman's talk where they showed off this framework. Always fun stuff to take a look at. I think I recognize everybody on the community call, but this is a live stream, so anybody could be watching at any time. So that's your nerd snipe of the day — make sure to go take a look at that if you're wondering how wasmCloud does some of its cool things.
Okay, folks — I know today didn't have the demo in the beginning, boo, and had a lot of discussion, aka me talking at you for like 45 minutes, boo — but I really appreciate you coming, listening, and taking the time to do that. I think we've got another couple of minutes. Is there anything else folks wanted to talk about on the wasmCloud side or the broader WebAssembly ecosystem that we haven't covered?
Brooks Townsend 55:03
All right, thank you everybody for coming to the community meeting. Again, looking forward to next week, where we'll be doing wasmCloud Wednesday on Wednesday, and we'll have our normally scheduled mix of discussion and demos — so tune in for all the fun that you know and love. Thanks, everybody. Have an awesome cloud day. See you next time.