Transcript: WebAssembly Workload Identity with SPIFFE/SPIRE and NATS
wasmCloud Weekly Community Call — Wed, Feb 12, 2025 · 66 minutes
Transcript
Brooks Townsend 08:02
Hey, everybody, welcome to wasmCloud Wednesday for Wednesday, February the 12th. I don't really have a big preamble. We've got a pretty good agenda for today. Let's go ahead and get started. I'm just going to share here.
Okay, so I know that I am going to kind of leapfrog the agenda here — I mislabeled things as I was coming in. So we're going to get right into some discussion, which should be fun. The first thing is proposing JSON Schema for CloudEvents and structs. This came up as one of the things on our wasmCloud roadmap that we identified as a gap in what we have today. There are two, maybe three, issues that relate to standardizing some of our field names and correcting inconsistencies with the way we specify host IDs, for example. But the big problem is that we don't have our CloudEvents and our protocols for wasmCloud specified in a way that's usable outside of the wasmCloud project.
There are different layers here, but the first one is that our CloudEvents — which are meant to be something anybody can subscribe to on a NATS topic to have this observability layer into the wasmCloud system, the same way that wadm does to actually run the whole scheduling and orchestration bit — you should be able to just subscribe to this message bus and get all of the events. And if you wanted to take actions, do autoscaling, things like that, you're welcome to. Our CloudEvents are currently defined in the wasmCloud Rust codebase, essentially as these JSON objects. These structures are documented on our website — you can look up events, go to "component scaled," and see a whole example CloudEvent for what it would look like. So if you're hacking something out or writing a script, you can synthesize this and deal with it fine.
The main problem is that's a chore — if you're working in some other language, you have to define this JSON yourself. But it's also a problem because if we make a change to some event — add a new field, deprecate an old field, add a new event — we then need to go update the documentation. That can be really easily forgotten, especially when an open source contributor adds a new field, we all say it's great, and then all of a sudden our documentation is out of date. So the feature request was to define specifically the CloudEvents in some kind of language-agnostic IDL — something that can be code-gen'd, that we can keep up to date and auto-generate documentation for.
I did a little bit of an investigation here. First at the top of the list, we can think of WIT as this language-agnostic IDL where we can define structures — records, enums, optional fields. There are actually things you can express in WIT that you can't express in CloudEvents, like resources and streams, which of course don't really make sense in the context of a CloudEvent, so we'd just ignore them. You can wit-bindgen those interfaces into language-specific code, so we could do that — we'd be using it outside of the WebAssembly context primarily, but it would help if you ever wanted to create a component that handled all the lattice events. There's also protobuf, which is a really well-known IDL that extends into using gRPC to publish, subscribe, and create services. Right now we send these things over NATS encoded as JSON, so we wouldn't be using protobuf encoding for this. I did some experimentation, and it actually looked pretty nice — it's really not hard to define services in .proto files, and you can code-gen structures for Rust easily. There's no support for generating services that publish over NATS, but we wouldn't need that.
At the end of the day, after some thinking and talking with a couple of other people on the wasmCloud side, what I want to propose is that we not commit to an IDL in order to do this. What I'd like to propose instead is something very similar to what we do in wadm: we have our structures written in Rust — like the wadm manifest format, which is just a Rust struct that we deserialize from YAML — and any time we build and release wadm, we use these nice Rust derives to convert that struct into a JSON Schema. In a JSON Schema, you can see this is the manifest: it has apiVersion, kind, metadata, spec; you can see the title is the name of the struct, the comment we had in the code, the required fields. It all works out really nicely, and JSON Schema plays really well with the general structure of the CloudEvent payload.
So what I want to propose — and this is totally up for discussion, no decision has been made — is that making a switch to something like protobuf would add a lot of friction for not a lot of benefit; you'd need protoc installed to build wasmCloud. I'd either rather define these events in WIT and then code-gen them and work with regular Rust structures, which would be a little bit of effort — or, what I think is the lowest amount of effort for all the gain of auto-generating documentation and syncing across the language boundary, just generate JSON Schemas for our events and structures. Other languages can do the codegen from that, match a structure against the JSON Schema to make sure it's valid, things like that. I truly think this is probably the lowest-effort way for us to get in the motion of keeping this updated automatically — done whenever we make a change to the struct itself. So I'm curious if folks have any thoughts here. This is still in triage because it wants a little discussion. Let me stop — yeah, Frank.
Frank 16:16
I'm just wondering — can you define mandatory fields? And how extensive was this?
Brooks Townsend 16:29
Yes. In JSON Schema you can define mandatory and optional fields. You also get the type of the field. So for example, here are the required fields for a manifest — the apiVersion is a string. Here's an example of something optional: you can either specify a shared application component, properties, or nothing; it can be an array, things like that.
I'll say one more thing — please feel free to raise your hand and ask questions. One thing this does for us specifically is it doesn't really require any behavior or code change on the wasmCloud side. It's pretty much just an extra output from our release, and we can take that output and bring it into our documentation. That would be the ideal pipeline for a lot of these structures, just to keep everything up to date. Yes, Masood, great question. Masood asked: isn't the CloudEvent schema already published? Is this about the data payload schema? That's exactly right. The CloudEvent schema — the top-level JSON payload, where it needs an ID, a type of event, the source, the data content type — all of that is already specified; that's the CloudEvents standard. We'd just be generating the JSON Schema for the inner payload, the inner data type. So for the "component scaled" event, we'd have a JSON Schema for that inner structure, which would include the host ID, the image reference, the instances, and so on. Leading on from that, I'm not sure that when we get into publishing these we'd need to publish them with the same outer payload — that seems very verbose. I think it'd be better if we could just publish it for the data field. That'd be my intent.
ossfellow 19:52
So Brooks, I'm sure you know, but CloudEvents now has mappings for NATS, which basically converts CloudEvents types to NATS CloudEvent types, so it takes care of the translation for you — how to encapsulate that message as a NATS message. That would simplify things, because in wasmCloud today that mapping is done by hand, by code.
Brooks Townsend 20:39
Yeah, you're right. We basically use the CloudEvents library and then publish out the whole payload on our NATS event subject. This is really interesting — I saw this on the CloudEvents crate and just thought, oh, great, they have support for publishing on NATS, but I'll take a deeper look. It seems like there might be an aspect where it takes the CloudEvent fields and puts them on the headers or in the subject. I don't need to read the spec right now, but thank you for bringing that up — I'll take a closer look.
All right, happy to take other questions. If there aren't any other concerns, then the next step would be for us to show a demo of using this to create that CloudEvent JSON Schema structure, pull it into documentation, see what it looks like. The next step would just be to do the thing — I can leave a comment on that issue pointing back to this community meeting, but I think this would be the simplest way to get it done. All right, we are moving right along. That was the first discussion for today. I think we can actually go back to the demo now, which — just to give you a show on the agenda — is workload identity in wasmCloud. So Joonas, you came on last week and gave us a run-through of what you were thinking about for workload identity, and now you're going to show it to us, right?
Joonas Bergius 22:58
Yeah. So I'll set the stage. I went through some slides last week to level-set with folks. I'll show you a diagram describing — oh, can you all see this browser window?
Brooks Townsend 23:26
You might just want to zoom in on the diagram, but that looks good.
Joonas Bergius 23:34
So, workload identity specifically. As part of the proposal, I'm proposing that wasmCloud adopts SPIFFE as the standard. It's quickly becoming adopted across the cloud-native ecosystem, and there are commercial offerings starting to pop up that are centralizing on SPIFFE — which is really nice, because if you don't want to run the backing infrastructure yourself, you have the option to use a commercial vendor. But there's also a very good open-source reference implementation called SPIRE. So we're going to be adopting SPIFFE as the standard, and for open source there's the SPIRE implementation, with commercial options downstream. And most importantly, I'm proposing this as opt-in, not as a hard requirement. This is a feature you can enable for your deployments, but it's not required for running wasmCloud.
Just to illustrate the flow before I show you the thing in action. This diagram represents what it would look like to use workload identity for the purpose of establishing or securing your NATS connection. When the wasmCloud host comes online, the first thing it does is connect out to the SPIRE agent to request its own workload identity. The SPIRE agent then talks to different platform APIs depending on what you're running on — bare metal or VM talks to the local kernel; Docker talks to Docker; Kubernetes talks to the Kubelet APIs locally — to validate that the wasmCloud host asking for identity is in fact who it claims to be. Once it can attest that the workload is who it says it is, it reaches out to the server component of the SPIRE deployment, which is responsible for issuing the SPIFFE verified identity documents. It creates a cryptographic document representing the entity, and propagates that document out to other SPIRE agents in your deployment so they can validate it later.
Once the host gets that document back, it initiates a connection to the NATS server. In NATS there's a concept called auth callout — the idea is to offload authentication and authorization from the NATS server to an external component. There's a whole doc for this that I'd highly recommend reading even if you're not using workload identity. So once the wasmCloud host has its workload identity issued from SPIRE, it presents that to the NATS server, which in turn calls the configured auth-callout service. The auth-callout service asks the local SPIRE agent to validate the SVID — the SPIFFE identity it was presented — and assuming the SPIRE agent says yes, this matches expectations and it's in the trust domain your cluster is in, the auth-callout service issues a user claim representing that connection and sends it back to the NATS server, which responds to the host allowing it to connect. So this is the handshake that happens when you first connect to NATS — we first talk to the SPIFFE/SPIRE ecosystem and then present that to NATS.
So what does that look like in practice? I'm doing this in Kubernetes because it lets me run all the components locally without a whole lot of hassle. I'm more or less using the upstream SPIFFE/SPIRE documentation's Quickstart examples and their upstream-provided hardened Helm charts, so there's very little configuration on your part, but lots and lots of opportunity for customization.
Brooks Townsend 30:07
We just still see your browser window — I don't know if you get your terminal.
Joonas Bergius 30:12
Oh, I'm sorry — yes, thank you. I forgot I didn't share my whole screen. Let me reshare. You can hopefully see this. Let me bump up this font size a little bit. Let me tell my system I need to be in dark mode — sorry for the flash bang, I should have given a warning, especially with my Excalidraw in dark mode.
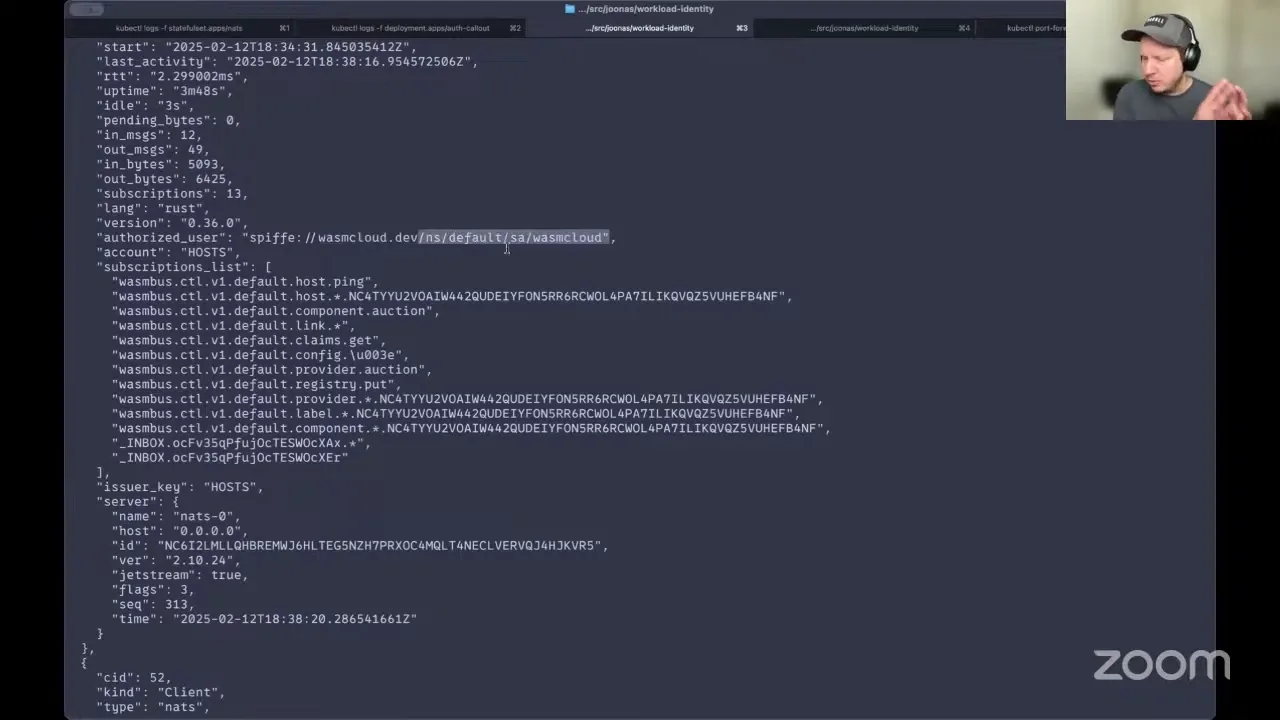
Okay, so this is just the local kind cluster I provisioned just before this call. What I have deployed is the upstream SPIRE Helm charts — there are a couple of extra components you probably don't need by default; I just didn't mess with the variables, so it's a "give me everything" default deployment. All I did was configure the trust domain for this demo. What's running here that's pertinent: a single-node NATS deployment (obviously we recommend three or more replicas for quorum, but for the demo it's a single stock NATS server configured with centralized auth). I have another pod that implements the auth-callout protocol, based on the upstream example applications, with the one customization being the logic to verify the incoming SPIFFE identity token as valid. And on the back side, I've added support in the wasmCloud host code to request that identity from the local SPIRE agent and supply it as part of the connection parameters to NATS.
When I run this command, it brings up a single instance of a wasmCloud host configured to use an experimental feature called workload identity, which initiates the workflow I described in the diagram. Let me kick that off. When it first comes online it'll crash a few times — in the background the SPIRE ecosystem has a component that automatically creates identities for pods when they're brought online. It takes a while for the system to propagate that identity through, so it fails a couple of times. Hopefully I've stalled enough — now you see the actual wasmCloud host coming online. The logging I added shows a method called connect-nats responsible for handling the connection; there's no JWT or key configured for the host to connect to NATS securely, but it does have the workload-identity flag passed in. So now the host is up and running, serving traffic.
If I look at the auth-callout side, this is the custom auth-callout code I wrote for this demo — mostly I'm just logging the incoming request to see what's going on. You'll see there's an auth token here, and what this token represents is the actual SVID provided by the SPIFFE/SPIRE ecosystem.
Now, I have a port-forward to the NATS server. If I ask the NATS server to report its connections, you'll note there are two connections to this host account. What I set up in this NATS deployment is an account for hosts where all the wasmCloud hosts live, an account for the system, and an account for the auth-callout side. You might wonder why there are two connections — the reason is that when a wasmCloud host connects, it actually has a separate connection for RPC and a separate connection for control (CTL), and we're using workload identity to establish both. The control connection is used when the host is told to run stuff or when there are commands for the host; the RPC connection is the one the host hands down to the providers it starts and supervises. So this is the separation between the two connections.
I really wanted to show you the identity. So here's the authorized user. If you've never seen SPIFFE before, the SPIFFE identity is in this format: it starts with spiffe://, the scheme, then the trust domain — here I've set the trust domain to wasmcloud.dev; usually this could be something like useast.production.acme.com. Then you get the path part, which describes the workload however you want. In this case I'm letting the agent automatically assign the platform-specific implementation, so what you're seeing is ns (namespace) default — the default namespace this workload is running in — and I've given it a custom service account, in this case wasmCloud. So this identifies it as the wasmCloud host using a wasmCloud service account inside this Kubernetes cluster. And this is the other connection — I can tell from the timestamps and client IDs which is which: the control connection is client ID 45 because it happens first, and the RPC connection is 46 right after. Both are currently using the same workload identity, though we have room to make them separate, or let the providers establish their own connections. The point is, what you're seeing is a SPIFFE identifier belonging to the connected host, and the host is happily connected and able to serve workloads. That's a lot of words — any questions?
Frank 40:07
Yeah, so you showed the happy path. Have you also looked into the failure modes for all these different components? Everything is probably running in containers, so if a container fails, or a connection gets dropped — I'm just wondering, since this becomes a key component on the infrastructure, making sure it survives all the failure modes. The other thing is versions change from different parts, so what's the migration path as things move along?
Joonas Bergius 41:14
Great question. From a failure-mode standpoint, the plan is to have all the components handle retries well, in a configurable way. If your NATS connection fails for the host, the host will retry automatically, and at the time it retries it'll request an identity if it can; if it can't, it'll retry requesting the identity a configurable number of times. So there are multiple levels of retries built in, so a blip on the network can recover to a degree. If you're hard-down or network connections are split, it's just not going to work — but that's true today regardless; if you can't talk to your NATS server, you can't talk to your NATS server. The first line of defense is retries on every level, and if it can't get its identity, then it should fail closed, meaning it will not be able to connect to NATS. That's the desired behavior, because if a host is partitioned from the deployment, I don't think it should keep running on its own.
Just as a general point — and Liam noted this — this is a production-level system. At Adobe we use this in our FedRAMP clusters. SPIRE and SPIFFE are real technologies used in enterprises. Some examples: Uber has something like 16 million identities under management, refreshed every few minutes. The whole point is that each host has a cryptographically verifiable identity proving it's supposed to be part of that cluster, and when it talks to other services it can present that identity to be validated. This use case is connecting to NATS, but you can imagine using the same identity for pulling images from a registry — writing policies on the registry side to say only hosts that belong to this trust domain, with this name, can pull images. So this lets you start writing policies on the receiving end of the token to make verifiable assumptions about who's talking to you. I'm planning on opening a GitHub issue describing the initial implementation, and I'd love for you to bring any of those concerns there.
Brooks Townsend 45:58
Yeah. I was just thinking about this — I know this is an opt-in feature, not something you have to use. If you have some automation already set up, you can still provide credentials to hosts and have them authenticated against the network. But beyond that, it's really interesting that right now, whenever you start a wasmCloud host, it generates its own identity — the NATS nkey, public key — and it's like, "here I am, I'm unique." It doesn't seem like this changes any of that. So just to drive it home: the whole point of this work is that now we know that host's identity, its connection, is verifiably supposed to belong to this NATS cluster, using that existing standard so we can build on those tools. Is that right? I want to make sure I understand it correctly.
Joonas Bergius 47:18
That's exactly right, yes. And to that point — we could have kind of done that before, but this will not require any secrets. This is a secret-less approach in that it reuses the existing primitives from the platforms you're already running on. You don't have to add any secrets — you don't have to provide a NATS credentials file or a TLS certificate; this automates that process. The whole point is to solve the secret-introduction problem, and even alleviate secrets in the OCI case where you can write policies on the other side to decide whether something should be authorized based on the cryptographically verifiable identity presented. There's also — I haven't fully explored this — a way to request an x.509 certificate, which also represents the entity. So there's the opportunity to use that for establishing a TLS connection to the NATS server, killing two birds with one stone: secure the connection and establish the identity of the client. I've gone with the path of least resistance using the tokens because that's the path we employ today with the creds files, but there's a future opportunity for automating the mutual TLS connectivity.
Brooks Townsend 49:37
I just had a super quick follow-on. If I'm a platform person deploying this and enabling the workload identity bit, where do I actually add the decision logic? Is it in the NATS auth callout where I decide if it should get in, or is it configuration to the SPIRE server?
Joonas Bergius 49:58
Great question. For what I demoed, the auth-callout service implementation is responsible for deciding whether a given host is allowed to connect. The NATS server presents all the connection information it received — you essentially have the same JWT on your side, and you can make decisions with that. My plan is to provide a reference implementation once I clean up the code a bit — it's not in a very pretty format, and there's some new tooling from the NATS folks to make it more concise — but the idea is to provide a reference implementation as part of the initial experimental feature so everybody can run this demo locally and then make it yours. Go ahead, Liam.
Liam Randall 51:01
So to wrap this all up — if we wanted a complete end-to-end story, if we were starting wasmCloud nodes and wasmCloud had some sort of TPM integration, it could boot on a piece of hardware, check that it's downloading a signed wasmCloud host process, and that would be enough to bootstrap this thing from random hardware all the way back to secure end-to-end identity, right?
Joonas Bergius 51:34
So Bloomberg actually has a TPM-based node-attestation piece that lets you know that a node is allowed to be part of the cluster. So yes, you can integrate it into things like cryptographic identity from your underlying hardware, or bake something into the hardware itself as part of the process. One thing that makes the SPIRE ecosystem really appealing — that I didn't talk about — is that it's extremely pluggable. They've done an incredible job exposing the surface necessary for establishing the whole process end to end, so if you want to customize it for a specific deployment, you can write a custom plugin — they're not a lot of code, and there are plenty of great examples in the built-ins and the broader community. There's the TPM one from Bloomberg, and a couple of others I came across. So there's a ton of flexibility from an integration standpoint to existing systems that might be proprietary to your company. What they give you out of the box covers probably 95% of deployments, but they have the escape hatch of a ton of plugin surface. That, I think, is one of the key benefits of why I'm really confident about moving forward with SPIRE.
Liam Randall 53:27
That's awesome. We've had a number of people chat with us about a TPM implementation, or TPM support for wasmCloud, so you could boot from Intel architecture into their TPM set. Apple has always had their secure enclaves on their hardware, and ARM has a general project here — secure enclaves — that's a very similar idea. That would be an interesting thought exercise to spin some cycles on. Thank you, Joonas. Appreciate it — awesome work. I can't wait for this to land.
Brooks Townsend 54:11
Yeah, awesome. I won't say your timeline on the call unless you want to say it, but looking forward to seeing the PR.
Joonas Bergius 54:19
I'll just say it out loud. I have an initial draft PR that I'd like to land upstream today. I also have an RFC describing the flow at a higher level that I want to open up. The draft PR implements what I'm describing in the RFC as a way to open up the conversation, and then we can build on it. It's certainly not the end-to-end story — there are still lots of other places we'll want to integrate — but we have to establish the foundation first at the host level for the other layers to make sense. That's why we're starting with the host: it's the foundation for everything else. Then we can rapidly expand once that foundation is in place.
Brooks Townsend 55:12
All right, well — thank you, Joonas, again. Awesome demo, awesome questions and conversation. We've got one more thing to talk about today, which has been kind of fun to look into. I guess you can call this the tiniest little demo — actually, since I'm not doing it live, it's not a demo, it's a discussion. I wanted to talk about something else on the roadmap: using conventional commits for release notes and changelogs. There are tons of conventional-commit tools that generate changelogs for releases, but I started looking into this, and I want to show you the end result and then talk backwards from there.
So I open a PR into wasmCloud where I wrote this super-cool new feature. It's a breaking change, and it's related to wasmCloud. So I write my conventional commit, which has the type "feature," the scope "wasmCloud," and a little exclamation point in the commit message, which means: hey, this is a breaking change — needs to be at least a minor version bump. What we almost have now is that when you do this, we have a little script in a GitHub Action that reads the commit message and automatically adds labels to the pull request regarding the type, the scope, and whether it's a breaking change. All of that culminates in this PR — and thank you so much to Lachlan and Roman for working with me on this; there were a ton of considerations and changes. Essentially, in the Action, after we validate that a commit is a conventional commit — we use the conventional-commit CLI to validate — we look at all of the commits in the PR and scan them for whether the impact is breaking, the type is a fix, the type is a feature, CI, things like that.
The cool thing is it's not just something we keep track of for a bird's-eye view of what a PR is about. We can use this in GitHub's automatic changelog generation feature, so we don't need to adopt an additional tool to change how the release notes are formatted. We have options like excluding authors, including certain labels, excluding certain labels — here's an example release.yml. This ends up doing two things. One, we can ignore Dependabot from being in our release notes — sorry, Dependabot, we love you, you're the number one contributor to wasmCloud now, but we don't want the chore version bumps to be a big part of our notes. Two, we can nest breaking changes, new features, and fixes under their own markdown headers, so we essentially auto-organize our release notes. Now in our wasmCloud repository we have a release.yml that just excludes Dependabot, but once we land this and start labeling all the PRs automatically — you can see in our recently generated wasmCloud 1.6.1 release I didn't have to modify this at all, but it excluded the Dependabot commit messages.
So this is all just to say we've found a really nice balance of being able to use conventional commits the way we do for our repository — we enforce them on every commit, and on the maintainer side we'll reformat if needed. When new PRs come in, this little bot — lol, it's a bash script — will label it for the scope and whether it's a breaking change. In addition to nice changelogs and bookkeeping, this addresses a big concern around surfacing breaking changes, especially in the provider SDK and the libraries other people use in other places. I think this will be a huge help, and we'll see it in our first provider-SDK release after we land the whole Actions bit. We get to use all the same GitHub tools we've been using for generating changelogs — we just get to use this extra little YAML file, and it makes everything nice and formatted and better. Do folks have any questions on that one? Changelogs, yay.
Brooks Townsend 1:01:29
All right, I know we're at the end of the call, and I apologize for going a little over — if anybody needs to go, please feel free. There's one more thing I promised we'd talk about, and I'll make it really quick. Ahmed, who is a wadm maintainer in the wasmCloud community call right now, has taken on a fairly large chunk of work to combine the wash library and the wash CLI into a single crate. As we saw over the past week, this is going to get really difficult to manage the more changes we make to the library in the interim. So what I'd like to propose is that we release wash 0.39 — that's the latest version — and then any changes we need to make for fixes or new features, I propose we do in a feature branch. So basically freezing code changes for wash on main. This will give Ahmed some breathing room to finish the migration, and then we can do one more version bump where we deprecate the old crates and start publishing just wash.
This is mostly a socialization thing — I don't think anyone would take offense. Please let me know if you're working on something you need to get into wash right away, but unless there are dissenting opinions, I'd propose we hold off on merging new features or bigger changes to wash for the next week, and then hopefully get to releasing the new project by next week's community call. So please reach out — raise your hand now if you don't like that — but I think we should just rip off the band-aid, get it done, and then look back and laugh at all of this. Do folks have any questions, anything they wanted to add there?
Joonas Bergius 1:04:00
I'll just say that as part of the work I demoed, I learned that when you pass a credentials file, we actually read it only once — but if that file were to change behind the scenes, we never re-read it, so your host will fail the next time it tries to use those credentials. So what I'd like to do is have that be passed through all the way. I think I was waiting for some of the washboard work to land to make that change happen.
Brooks Townsend 1:04:36
So do you just need it when we release the latest version? The washboard can update independently from wash now, right?
Joonas Bergius 1:04:46
Yeah, actually, yes. We don't have to get into the details here, but I'm happy to talk you through what I was thinking offline. I was just waiting for the wash stuff to merge, because I didn't want to create more rift.
Brooks Townsend 1:05:01
Okay, no, it's great to hear. I just want to double-check before we start telling people in PRs, "hey, wait, do it somewhere else." Cool — well, then that is what we will do. Thank you all for coming to the community meeting today and hanging out for a little while. I figure folks have to dash, but thank you so much. Have a great rest of your week. We'll see you next week. Thanks, everyone.