Transcript: Workload Identity (SPIFFE) and wash Plugins as Wasm Components
wasmCloud Weekly Community Call — Wed, Feb 5, 2025 · 58 minutes
Transcript
Brooks Townsend 01:47
Okay, hey everybody. Welcome to wasmCloud Wednesday for February 5. Let me go ahead and share the agenda for today. We've got a couple of things to go through, and I expect to have some really good discussion across the community call today, and then we'll do kind of a regularly scheduled check-in. So we are going to pull the rug out from under this agenda and reorder things. We're actually going to start with the discussion on workload identity. Joonas is going to take us through lots of things about workload identity — what it means, what it may look like for wasmCloud, things like that. I don't want to spoil too much. And then Taylor is going to take, I think, this demo — at least a discussion of some updates and upgrades to wash plugins. You'll remember that Taylor authored the original RFC on wash plugins. So without talking any more, Joonas, would you like to go through? All I've said, basically, is workload identity. I think you have some educational material, so take it away.
Joonas Bergius 03:09
I put together a few slides just to talk through this a little bit more, and I will press Share. So, workload identity — for anybody who's not familiar with it, workload identity is essentially this concept of providing your services, your applications, a form of identity from the platform that they're running on. It's becoming known as non-human identity, I guess, to contrast it with the actual humans. There are many forms of workload identity across the industry, and it's fairly common now for different cloud providers, for example, to have a built-in set of primitives that they offer you. And platforms like Kubernetes and Nomad also have a form of workload identity built into them. So it only makes sense that wasmCloud would also start looking at providing a form of workload identity.
A couple of important things to call out as workload identity pertains to wasmCloud. We want it to be infrastructure-agnostic, because wasmCloud runs across many different environments — from edge to cloud to on-prem to IoT — and so we don't want this to be tied to a specific type of infrastructure. We can't make use of the identity issued by a given platform we're running on; for example, we couldn't make this something that depended on AWS or Google Cloud or Azure, because we want this to work across all of them. We want it to be based on standards. It's important that it's interoperable across platforms where we might be running in multiple different places — let's say we had a cluster spread across edge and cloud; we want those two to be able to talk to each other through this form of workload ID. It's important that it's cryptographically verifiable, in that you can validate that the workload, as it presents its identity, is actually the workload it says it is. That's kind of a core tenet of workload identity. And to the extent possible, it should be fully automated, in that the workloads themselves running on wasmCloud should not have to do anything other than request the identity for it to be available to them.

Joonas Bergius 05:20
So let's talk about the immediate use cases that might come to mind when we're talking about workload ID. The first place is securing the NATS connectivity for both the wasmCloud host itself, but also providers, because they both need to talk to the NATS that powers your cluster. There are a couple of different ways we can handle this, but as a foundational thing, in order to get anything else going, you basically need that NATS connectivity, and it would be fantastic if that were secured by this workload identity.
Then, a use case that came to mind — something we have some open issues around already — is the ability to do dynamic OCI artifact pulls. When you're deploying a component or provider, it'd be fantastic if the host didn't actually have to have a hard-coded set of credentials stored for those pulls, but instead could present the workload identity it has been issued as a way to authenticate with the OCI artifact registry. Similarly, for accessing third-party resources: you could imagine you're running on AWS and you have a blobstore provider that wants to talk to S3 — it would be fantastic if the blobstore provider could present its workload identity to AWS, and that would be the way it gets access without having any kind of secrets stored in the definition for the provider. And then down the line, there are use cases such as establishing mutual authentication between the host and the providers — establishing a foundation where we can have mutual TLS, essentially a cryptographically authenticated tunnel between the providers and the hosts. And then, when we step back and think about having multiple clusters deployed across clouds or different environments, it'd be wonderful if those clusters could establish a trust relationship with each other through presenting their respective workload identities.

Joonas Bergius 08:00
If you've spent any time in this space, you might have come across something called SPIFFE. SPIFFE is essentially the standard, if you will, in the CNCF space for workload identity. It's been around since — I think work started on it around 2016 or 2017 — and it's one of the CNCF graduated projects. It presents a standard that you can implement for workload identity, and there's a reference implementation in open source called SPIRE. So my proposal is that we adopt SPIFFE as the standard that we build our workload identity around, and for getting started easily, the SPIRE ecosystem of projects will be very helpful as a way to bootstrap workload identity for wasmCloud.
How do we go about workload identity? There are essentially three areas we need to cover. For any of this to be possible, we have to start with the host. The host itself has to have a way to obtain workload identity, both for itself but also for the workloads running on top of it, such as components and providers. So that's the first step. After that, components and providers aren't necessarily tied to each other, but from a use-cases perspective, it makes more sense to start with implementing workload identity on the provider side, because there are some ready-to-go use cases there. And then components themselves should also have the ability to request workload identity, because there will be similar use cases there.

Joonas Bergius 11:43
In terms of what's next: initially I'm working on getting a proposal together and presenting it in the wasmCloud issue tracker, and then following that up with a POC demonstration of how the initial host integration might look. I'm already working on a proof of concept that shows how we establish NATS connectivity using workload identity. And then, once we have agreement on the proposal, also create a tracking issue with the work that needs to be done outlined on there. I'm sure as we get further along, new things will pop up, new use cases will come up, which is great, but I think it's important to lay out what it would look like to initially roll it out across the host, provider, and components.
As an extra motivator — OWASP recently published a Non-Human Identity Top 10. This is a set of non-human identity risks, machines doing things. I haven't gone through the entire list and qualified whether each would be addressed by workload identity, but I will certainly include a section motivating this in the proposal. A non-trivial number of these — probably over half — can be addressed through workload identity. So the idea is to say, hey, these are known problems that plague the industry, and if we introduce workload identity, we can start solving for these risks across wasmCloud deployments. So, yeah, that's workload identity. I'll follow up with an RFC, and hopefully next week I can actually show a lot of the host in action doing this. I should also mention that Colin and I are going to be talking about this at KubeCon, so a little bit of extra motivation there.
Liam Randall 14:05
Gotta get it done. It has to be done completely, and XDS as well. Let's add it all. So SPIFFE is something that has solved a lot of problems professionally for me in the past. It was a big thing when Istio came out — if we all recall the before-times with early Istio, one of the key features of Istio was that it provided workload identity into Kubernetes, which had no concept of workload identity. Where the real strength of wasmCloud can be is — it's nice for small companies, but I really feel like it's huge for big companies, because this is a problem that, if you're using manual certificates, if you're using service IDs with certificates that need to be rotated for every microservice-to-microservice transaction... I know this is something Istio solves, but most people don't actually use Istio for this. So I feel like with this blank page of wasmCloud, of getting people to move workloads into wasmCloud, it's a real benefit to have this just included. I don't have to worry about service tokens. And it ties into how we might want to integrate with things like Envoy with XDS. If we get it right, it's going to be awesome. And we will, because everything we do is awesome — especially you guys.
Joonas Bergius 16:29
We have Florian next.
Florian Fürstenberg 16:32
Yeah, many things. First of all, thanks for this great idea. I'm really interested in that as well. It's still, I would say, not completely standard in Kubernetes — it's actually well established but not broadly used. But the question is: would this be optional? Because if it's mandatory and not optional, it would introduce a huge dependency for operating wasmCloud. And then the follow-up question would be: would your RFC also cover some best practices on how to operate SPIRE? Like we have it on wasmCloud for NATS — there's also some guidance there.
Joonas Bergius 17:22
Great questions. The goal is to definitely make this optional — if your deployment doesn't require workload identity, that's totally fine. I agree that this has a fairly sizable footprint in addition to what your core wasmCloud deployment might look like, because there are a lot of moving pieces. So we definitely aren't planning on making this a requirement; it's added on as an additional feature that you can turn on if you want, similar to how you can do this with other platforms.
As far as operating SPIRE, I think we'll have to defer a lot of that to the SPIRE community. We'll certainly include as much guidance as we can out of the box, but a lot of the deep knowledge lives within the SPIFFE and SPIRE community. There's a fair amount of community documentation and talks from people who've adopted SPIRE at scale — for example, Uber's entire identity plane is operated on SPIRE, and they issue about 160 million active identities. So there's a lot we'll lean into there as the experts. But certainly we'll do our best to provide the guidance for getting it going and operationalizing it — and where possible, I think we'll also recommend offloading some of the harder things, like database management, to a managed provider if that's an option, so you're not taking on a whole lot of operational burden on top of running wasmCloud itself.
Liam Randall 19:21
I think Istio has done a pretty good job with it, so I don't know where we're going to end up, but people have been using Envoy and Istio — in Istio there is SPIFFE, and if you do nothing, it's a self-signed certificate, which isn't going to be great for a real production deployment. But I think they've done a pretty good job. It's just that Envoy is not part of Kubernetes the way that wasmCloud... there's enough here. I'm just trying to reiterate that if we do it well, people are just going to have this thing, and it's going to be super easy to get going, so it'll almost be the default. I mean, at some point we might not have NATS be required for wasmCloud, right? But NATS with wasmCloud is nice, and it's a good way to do it. So I'd like it to be similar to SPIFFE as well, eventually.
Brooks Townsend 20:22
Okay — sorry, Florian. That was actually going to be my question for Colin or Joonas. In the spirit of non-breaking changes, this would be something additive that you can opt into from the initial feature. And then, in your ideal world, do you see this being something that's just on by default, or required in, like, a wasmCloud 2.0, potentially? Spicy thought, but I'm curious on your take.
Liam Randall 21:08
I think, yeah — like an auto-generated certificate authority that just out of the box runs with wash up. Istio has done a good job with it, so that's what they do. Not everybody likes Istio, so maybe — but at least in terms of this, I feel like they've done a good job. I think we'd want to follow that path unless there's a good reason not to. But that's just my personal opinion.
Joonas Bergius 21:39
Yeah, I'm going to focus for the short term on introducing this as an optional feature. I think our experience getting this out there and getting people using it will inform how we want to move forward as a project, in terms of broader adoption — whether it becomes an ambient capability that's always on regardless of whether you use it, or something you have to opt into. Something that makes sense to keep an open mind to: by adopting SPIFFE as the standard, end users will also have the option to potentially offload SPIFFE management itself to third-party services, because there are a number of companies working on managed options that provide SPIFFE as a foundation. So if that's an option for folks, they might go that route. But certainly in the open source, it's my goal to minimize the footprint in terms of what you have to maintain while still getting the benefits from the platform.
Brooks Townsend 23:06
Yeah, that totally makes sense. We certainly have the initial need — as soon as you move off local, because we do it for you on local — to set up NATS infrastructure, so there already is something you need to create and configure. It seems hard to want to add more and more into that; it starts to wade into needing a provisioning-type tool.
Liam Randall 23:40
Yeah, I think it's a problem that's really an enterprise kind of problem. Once you have lots of services, you do need to manage what can talk to what, and then integrating with things like Envoy or other proxies — you're going to have to have some sort of workload identity. It solves a lot of things that we have aspirations for. But maybe there's an enterprise-only angle.
Joonas Bergius 24:16
Yeah, no, I think you're right. I'll say the nice thing about building specifically against SPIFFE, as opposed to SPIRE, is that it allows us to also implement additional or alternative back-ends for the implementation. So we could have something more local-host-friendly or development-friendly that's much more lightweight and fully integrated. The goal is to start with the SPIRE ecosystem of software, because I wouldn't reinvent that wheel lightly. But as we get a better understanding of what parts are hard about operationalizing it, and what parts could be integrated more directly into wasmCloud — for example, I think the SPIRE agent is primed to be completely integrated into the wasmCloud host, where the host takes over the responsibilities that the SPIRE agent is normally used for. That's one of the opportunities for simplifying the operational burden. Then we can assess what the control-plane side of it might look like down the line, but I'd want that to be fully motivated by the experience we get from end users.
Liam Randall 25:29
And I think we also have to differentiate OIDC, too — I think we do explain that concept in our KubeCon talk, because this is a broader thing as well. So just a note to self and Joonas.
Brooks Townsend 25:47
Yeah, awesome. I really look forward to this — and don't let me cut anybody off who has questions, feel free to jump in. But I'm looking forward to seeing this working and what it looks like from the beginning. So this is great. Thank you, Joonas, for coming on and doing the educational pre-work for workload identity. It's a huge help to have it presented in this way, in the wasmCloud lens. Colin, looking forward to both of you doing the talk. Okay, moving on to the next item on our agenda — a text-based demo and discussion on wash plugins, and some of the galaxy-brain things we've been thinking about for a little bit. Taylor, would you like to talk more?
Liam Randall 27:21
I can talk more. Okay, I'm linking the issue I'm going to pull up here just for everybody to see. Like I said, this is just text-based. This is an RFC I've been working on for a little while, and I've been talking to various maintainers about it. One of the things we've talked about for a long time is that Wasm is great and should be — if it evolves the way we've wanted it to — the last plugin system you'll ever need. So we've talked for a long time about plugin-ifying wash, and that means turning large chunks of the functionality of wash into plugins that can be updated independently as needed.
The main motivation is the obvious thing: we want to dog-food this. We want to be using components, see where things are at, try them out, find the rough edges. But also, we have lots of people starting to productionize wasmCloud, and there's a certain amount of flexibility needed here — things like auth plugins, hooking into whatever system you're working with for your developers, custom extensions people want to add for their internal platform. So this serves the dual purpose of breaking up wash into smaller pieces that can be integrated independently, plus those flexibility use cases. This is an RFC proposing that, and it goes into great detail.
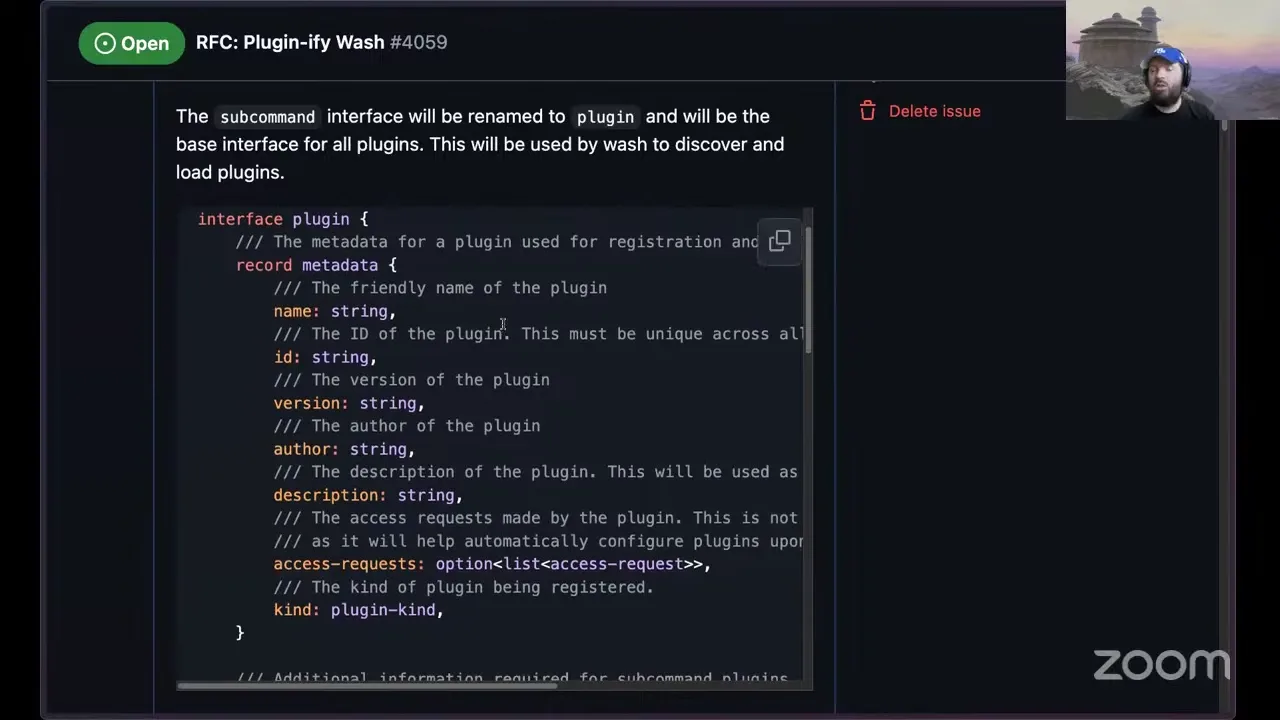
What this boils down to is a few required changes, and the biggest is around the interfaces — what wash is providing to plugins. We're going to rename the subcommand interface to plugin.
Brooks Townsend 30:01
I just wanted to ask if you could zoom in just a little bit.
Liam Randall 30:04
Oh, right. Hold on — enhance. Sidebar, you should be gone.
Brooks Townsend 30:19
Okay, it was just a little hard to read the WIT.
Liam Randall 30:21
Bigger WIT. So this is now the plugin interface, and it supports both kinds of plugins: the standard plugin, which was a subcommand plugin before, and also an auth plugin. This has the ability to return metadata — it's how a plugin tells wash what it does and what it registers. The big change here is that before, we tried to be helpful — you could say, here are my flags and arguments that can be passed to this. But for maximum flexibility, that doesn't really scale. So all argument parsing is now delegated to plugins. It gives more flexibility — a little bit less nice of an experience when you're listing the help commands from the top level, but that's the trade-off.
The big thing is this new auth interface. Auth plugins are in charge of two things. First, they allow you to perform login flows, abstracted behind a single authenticate method, and it returns back two types of credentials. One is a NATS credential, which is a seed and a JWT — most people in the Wasm space are familiar with that. The token is optional, because you can do auth callouts via NATS, which is a common integration pattern, especially if people have existing authentication systems. There's also an optional token used in those flows; we've always talked about having HTTP shims, so I'm keeping it in there for future evolution where you might have HTTP-based authentication and need just the bearer token.
Related to that, because many of these plugins will have to do an OIDC flow — and OIDC flows are going to be a little janky to start with, because you have to do the request and then spin up an HTTP server that listens for the callback URL — what we're doing is abstracting that behind an interface provided by wash. It's OIDC-specific for now; if people need OAuth, we can add an OAuth-specific one. You configure it, and wash takes care of sending out that flow, spinning up a localhost listener, inserting the response, and then returns the tokens you expect.
Another thing we'll need for normal plugins is the ability to push and pull from OCI. All of these interfaces, by the way, are not set in stone — I've written them out in a WIT directory ready to go, but they might change as we start implementing. The easiest way to see the big high-level changes: we'll have the subcommand world, which is your main plugin world, where we import registry and export plugin, and then export the WASI CLI run just like before. The auth one is a little different in that we don't include all the WASI CLI imports — we include things like the environment, outgoing handler, random, filesystem, and clocks for stuff we need, and then OIDC, and a new thing called context.
The wash context we're going to update to include two new things: one field describing the auth plugin used for that context, and a map of string-to-string for additional data that can be passed to those auth plugins — account names, IDs, anything like that. Any auth plugin where the current context uses that plugin will get it passed via the interface, so you can fetch it using get-context.
To support plugins and things like sandboxing, we'll introduce a new wash config file. The good thing is, most people shouldn't have to edit their config file by default. There are a couple of things, like the default auth plugin, which will just be the same file-based auth we have now. Essentially you have a set of allowed paths that are allowed globally, access to specific environment variables, and then plugin config for each thing — the plugin ID, allowed env vars, allowed paths, and the additional config passed into the plugin. During wash plugin install, you saw those access requests above in the plugin metadata — a plugin can hint and say, "I would like access to these resources." So it becomes more like a standard experience on a lot of machines nowadays, where it says "this app would like to have access to your microphone." That will be interactive by default; if you want non-interactive, we'll have flags to accept or deny those things, or you can configure them yourself.
We're going to make sure this is backwards compatible — still support the old version of the plugin interface. As far as we know, not a lot of people have written wash plugins; if you've built something big and depend on it, please let us know so we can make sure we adjust. We'll probably support it for two additional versions before completely removing the old 0.1.0 version and moving on to the 0.2.0 version.
The big thing to note: I tried to break down the initial things and built these in such a way that we can prove out the work. wash drain and wash keys are pretty standalone — they don't require a lot of additional effort, so replacing those shows the basic thing works. Then when we do wash context and an auth plugin, we test the other things, and then functionality like wash pull and wash push lets us test the registry interfaces. We're not trying to replace everything in one go. As for distribution — our best option is for this to appear seamless to anyone downloading wash. By default, the default build of wash will have the plugins embedded inside it, so you don't have to install anything. As future work, we can have a clean/light build of wash where you assemble your own with whatever plugins you want. So that's the overview — text-based demo, nothing really exciting, but I'm really curious to get people's thoughts. Masood, you have a question?
ossfellow 39:22
Yeah, the idea is great. I've used the plugin framework, and it's kind of clunky. A limitation I faced was that I was trying to mimic some open-source commands, and some of them are multi-tier subcommands — you might have more than one subcommand. This was forcing me to have only one subcommand, and it ended up creating a situation of text parsing to try to mimic the behavior of the source command. So would there be more flexibility here in building the command structure?
Liam Randall 40:34
Yes, that's what's here — we've removed the arguments and flags field. The first draft was about making sure this was integrated pretty seamlessly, where you could literally see in the wash code it pulls it in and attaches it to the clap argument structs. In this case, the parsing is delegated entirely. The whole point of having it exposed in the world, the WASI CLI run, was that you could technically run this as a normal CLI. So what I'm proposing is that we move away from anything with the arguments — you get to parse all the arguments. That means you can have multiple nested subcommands and all the things you'd expect as if it were a normal CLI. That is the goal: to make it more flexible. Things like those first couple of commands I suggested — wash keys has multiple subcommands, so we'll be able to prove that out and make sure it isn't too clunky.
ossfellow 41:31
Can I ask for something else related? The auth plugin seems very useful, also for the host. I know there might be some overlap with that workload identity plugin, but imagine instances — if we consider providers today that want to talk to NATS, each of them should have that configuration defined for them, versus they could just ask, based on their ID, "give me the credentials for NATS," and they could connect to it — reducing the amount of boilerplate that needs to be built for each provider to authenticate.
Liam Randall 42:47
Yeah, those are definitely in the future. We've talked about wanting providers to be able to be Wasm as well, as Wasm matures — those are all kinds of things we could reuse. I will say right now it's very much targeted at the wash use case. But this will probably be prior art we can refactor into the next version, like a 0.3.0 of this interface that could be more reusable and modular. But yeah, this is something targeted mostly at wash right now. Brooks?
Brooks Townsend 43:35
Yeah, Taylor, I think that's pretty good context. Looking at the registry and auth and all these interfaces — it's all basically inspired by a subset of the capability that wash needs to work, the wash subcommands we have. I had a fun question. After this is all landed and it's beautiful and we have wash plugins, and I'm a wasmCloud developer who wants to add a new subcommand to wash — what do you think we'll want to encourage from a contributing perspective? Do we want to encourage that new subcommands come in as plugins if possible, or start them out in Rust as native code and then refactor to a plugin once we've used it for a little while?
Liam Randall 44:11
So, I personally would say that if this is successful, the thing we'd encourage people to do is, if you want to add a new subcommand to wash, you'd start it as a plugin. And if it becomes something common enough, it could become a community plugin. The thing I'm looking forward to: I greatly prefer writing CLIs in Go as opposed to Rust, but because of all the WebAssembly tooling that exists better in Rust, a lot of this has been in Rust. In the future, we could maybe write some of these things easier in something like Go, compile them down to the component we can use. For what it's worth, these first things we're going to keep in Rust, to keep them tiny and streamlined since they'll be embedded into the main wash binary. But the point is, it gives the flexibility of using whatever language the contributor is comfortable with to try out a plugin, and it lets us try out things without forcing us to rev wash. Right now the control interface is out of scope for this RFC, but imagine a future where we want to change that, or add support for a new experimental API — we can do that without revving all of wash. That's why I think pushing people toward plugins is the better option.
Brooks Townsend 45:14
Yeah, that was going to be my next question. Just recently, Luke on the wasmCloud maintainer side added support for embedding WIT into a provider archive, which is an awesome feature we've wanted for a while — thank you, Luke. That's a new feature. Feasibly, if we could do it all in a plugin, we could just update that one individual plugin. Is that what we'd encourage people to do — some kind of wash plugin update to pull down all the SemVer-compatible latest changes? Or would we still maybe just rev the CLI? What I'm getting at is, if it's all plugins, then we could probably get away with not doing a lot of core wash releases.
Liam Randall 46:56
That is a nice knock-on effect here — that was part of the secret plan. Let me check the current wash plugin command — it currently has install and uninstall, and the install can update. But it'd be good as we improve this to be able to do wash plugin update and have it look through all your plugins and fetch the latest version from OCI. That would obviously require people pushing these plugins into OCI to have SemVer-compatible tags. But yeah, I'd want that to be something where we can update those things a lot quicker and out of band. The reason this has been on our minds for a long time is the two big things: it shows off the power of Wasm really well, and as a Wasm project that's a good thing; and it gives us the flexibility to add extensions and experiment with things faster, rather than becoming the kitchen sink of tools — which is great, given its name of wash.
Brooks Townsend 48:01
Yeah, that makes sense. Which one did you say you would start with, just to prove it out?
Liam Randall 48:39
The two I'm starting with to prove it out are wash drain and wash keys, because I know the nkeys library can be embedded into a component, and drain is just accessing the file system, so it tests the access requests — it tests the ability to write out keys to a specific directory. Then after that, if we do wash context as a plugin and an auth plugin that replaces our current loading from wash contexts — that plugin will also accept the same wash env vars that currently exist. Then wash pull and wash push lets us test the registry interfaces to see if abstracting those things works okay. And we might just experiment for fun with an auth plugin using OIDC and see what happens. I want to make sure as we do it that we can back out if we find out it's terrible, and we can iterate over the interfaces. But I think we'll be able to do this fairly well, and then wash eventually becomes a customized Wasmtime host that runs the things and provides the basic functionality for all these plugins to use. That's obviously a long tail of stuff we have to do to get there.
Brooks Townsend 49:28
Yeah, that makes sense. Cool. Well, hey, we have just about five minutes left — that's enough time to run through some of the latest and greatest things we've done on the wasmCloud roadmap.
Brooks Townsend 51:40
Just a quick update here. As a reminder, everybody can see this roadmap that we planned on the wasmCloud organization — it should all be public. We've been moving things out of triage and into the ready-for-work stage really well — wrapping up some of the information-gathering and planning around the bigger tasks we know we want to fix but aren't sure exactly how. For all the folks looking to contribute to wasmCloud for the first time, or to get your feet wet with good issues, the ones in the ready-for-work tab under "improvement" are all pretty well scoped — low to medium level of effort, but high impact because they're on the roadmap.
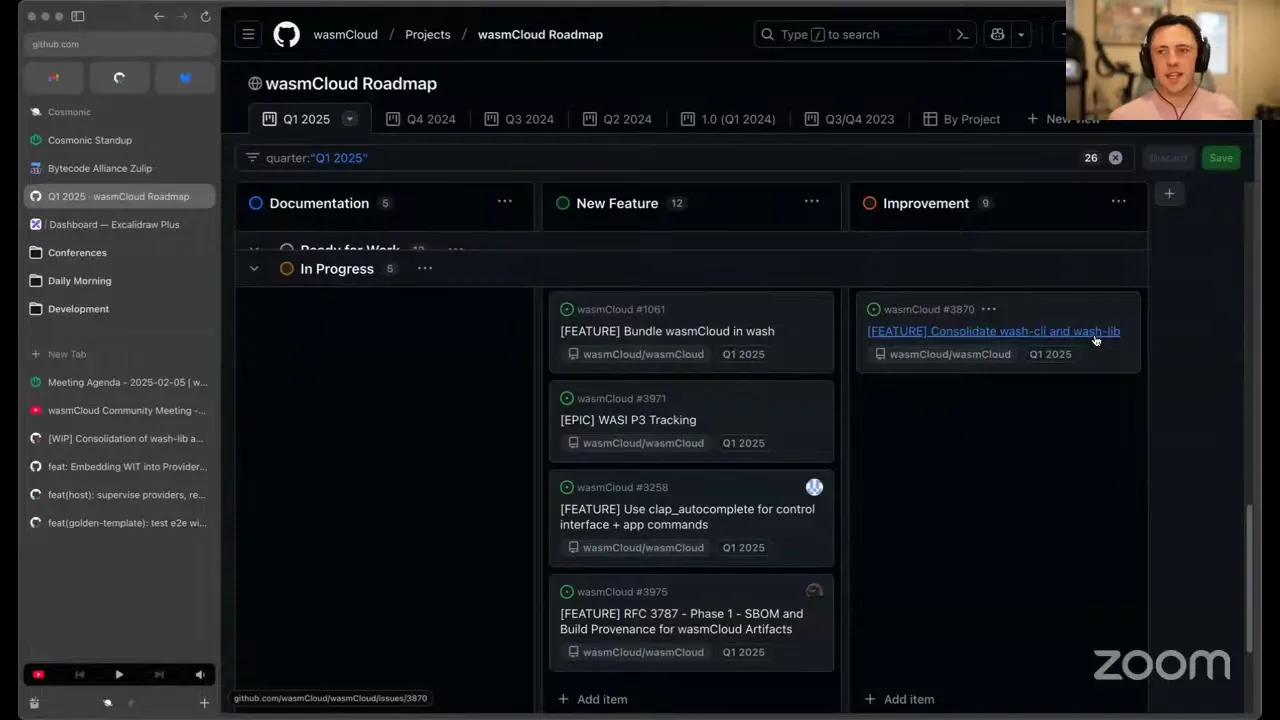
Some of these are getting taken by our awesome contributors and maintainers, like Aditya on the cron job provider — I saw you and Taylor talking about some design things in that issue. And Masood, or ossfellow, on the built-in HTTP client provider. We did talk last time about moving phase one of the SBOM and build provenance for wasmCloud artifacts feature over, which is a sub-issue of the broader RFC — thank you, Masood, the PR did come in. Ahmed went for consolidating wash CLI and wash lib; that's a work-in-progress draft, but it looks functionally pretty done — there are just going to be some workspace pains. So if you're looking at taking on any larger issues or fixes for wash or wash lib, feel free to get started, but just be prepared to help integrate that into the new wash crate maybe a little later this week. We did do the initial spike on bundling wasmCloud and wash; there hasn't been more movement there yet.
And under completed — this one may have slipped under the radar, but I want to thank Roman for doing a ton of work on the wasmCloud crate features, which essentially allows you to drop into our wasmCloud workspace, run a cargo build, and based on the features you provide, build different individual libraries in the workspace. If you wanted to build everything, you can enable all the features and it'll build all the providers — a super nice simplification. Or you can turn them all off and only enable wasmCloud to build just the wasmCloud binary. Integrating that with our Nix flake outputs, we can now use Nix and Nix-on-CI to only build specific binaries when we need to. Our CI has gotten quite a bit faster, broken out into individual binaries for builds — the matrix has gotten kind of hilarious if you look at it. This is all awesome, and not just for CI speed and organization, but also because the less compute we use, the greener we are in terms of ethically using CI pipelines.
That's a good summary of where we're at on the roadmap. We're about a month into the quarter, but we did this roadmap planning a few weeks ago, so we're making great progress. Great job, everybody who's coming in and contributing and getting these things across the line. Do folks have any other questions, comments, or concerns about the wasmCloud roadmap and where we're at?
Brooks Townsend 57:46
All right — everybody's favorite thing, CIs and roadmaps. Well, I think that just about does it for today. I can hang on for a little bit longer after the stream if folks have any other questions. But for now, thank you, and I hope everybody has a great wasmCloud day. See you next time, everyone. Thanks, everybody — we'll catch you either in Slack or next week.