Transcript: WebAssembly and Kubernetes, Provider Supervision & wash 0.38
wasmCloud Weekly Community Call — Wed, Jan 29, 2025 · 93 minutes
Transcript
Brooks Townsend 04:09
Hey everyone, welcome to wasmCloud Wednesday for Wednesday, January 29. We have got a pretty sweet agenda for today — a couple of demo and discussion items, and we've got a bunch of people here from the community, so thank you all for being here. The first thing, just to go ahead and jump right in, is a demo of something that came up on the open source side. Actually, Lucas is here — Lucas from Cosmonic filed this issue last week, where when a provider fails — let's say you try to start a capability provider and it's provisioning resources on the machine, like opening up a couple ports, and it's not able to open that port, so maybe that's a failure mode and the provider exits. When the provider process fails, or if you just kill -9 it, the wasmCloud host that's running that provider currently doesn't do anything with it. It reports that the provider exited, and then we're basically just sad about it until a higher-level orchestrator like wadm tells wasmCloud to stop and start that provider again, which isn't really a hook we have easily accessible.
So we talked a little bit about how to implement this, but I think this was pretty fairly filed as a bug. The reason is I see the wasmCloud host evolving more and more in this direction of being like an agent — people have described it as a daemon before. The wasmCloud host's job is to run components and run capability providers, and I think part of that is continuing to keep them running. So this may sound really obvious, but I think it's a property that will keep carrying forward in different things when we update the host.
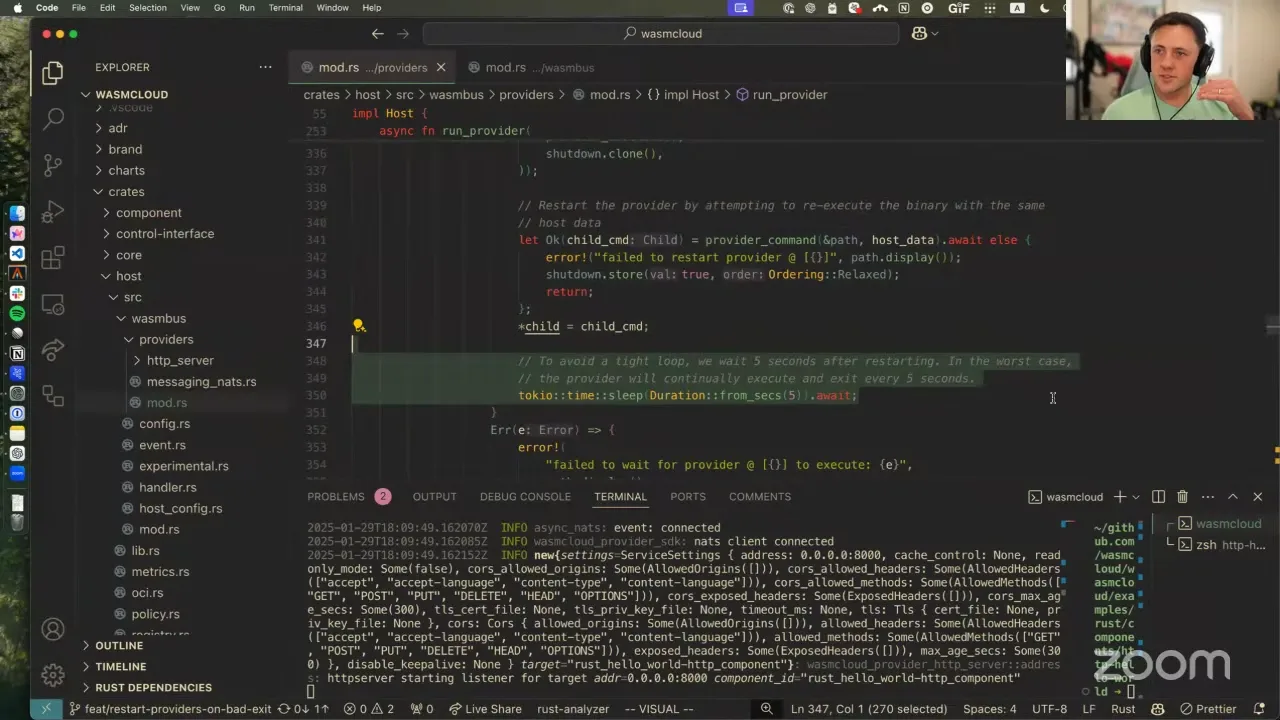
So I did put up a PR a little bit earlier — today was when I finalized the implementation. What this does is whenever a capability provider exits at runtime before the host has explicitly told it "hey, you should stop," we re-pull the configuration and set up a whole new provider process, then execute it. Let me show you it working, and then we can look at the code if people are interested. Commonly, the way I test things when I'm working locally is I use wash up to run NATS and wadm, and then I take a look at the host that wash started and stop it. So now I have NATS and wadm, and this gives me the freedom to run a wasmCloud host from my local Rust changes. I have my host running now, but pretty much the same as wash up, I can go to an example component — we can just do hello world to keep it nice and easy. This deploys two things: the component itself, my nice little business logic, and the HTTP capability provider that listens for HTTP and forwards onto the component. So if I do a nice curl localhost:8000, I see "hello from Rust" — great, basic example app.
Now, previously, if I were to find the HTTP server process locally on disk and kill -9 it, this would not be supervised by wasmCloud — you'd see a nice little error message like "oh no, it exited, that stinks," but nothing would happen. But now, if I do this, notice I can still curl, and this isn't just because there's something else running in the background.
Let's take a look at some of the logs. What happened? I sent the kill -9 to my provider. You can see we got a warning from the host — I put this at warning level, it feels pretty apt to say "hey, this is weird, but we're going to restart it" — saying it exited with wait status nine, so it was killed. And then pretty much right away the capability provider starts up again and logs "hey, I set up this listener for the component."
So what happens here — we can actually look at the code, it's very fun. There's this new provider module which contains all this implementation. When we execute the provider, we're left with this process child, a handle to the process on the local system so we could kill it at any time. Then we have a background task: one, responsible for watching for configuration changes, but two, it just waits until the provider exits — and this task will sit here doing nothing for the whole lifecycle of the provider in the normal case, as long as it's not actively shutting down. Then we'll output that warning message, go back through the provider initialization process — we fetch configuration, we fetch secrets, we reuse some of the exact same information like the X key and the ID so everything is stable. We're just restarting it, but making sure it has all the updated config. And then last but not least, we watch for new config changes and execute the new child process, the capability provider.
This is a choice I made — we could certainly use an exponential backoff mechanism here so that if we're running into a failure we don't continue over and over, but I opted for a pretty dumb sleep-for-five-seconds-try-again. Really all we want to prevent is hot loops where the provider just restarts over and over. When I was researching, it turns out the exponential backoff crate is written by Yosh — so thank you, Yosh, on the WASI side and everything. Okay, there are a couple other refactors in this PR to clean up some of the wasmCloud host code, but that's the core of the feature. Do folks have any questions about how this works? Does this line up with your expectation for a host keeping a capability provider running?
ossfellow 12:22
Hi, Brooks, two questions. One is, when we have resources that we register in the store, in the runtime — that's one thing, about the cleanup there. And the other one is when a component used set-link-name or whatever, to basically dynamically change the link — now when we reset the provider, how does the component know that the link has changed?
Brooks Townsend 13:08
Great question. So the first one, around if the component registers resources or is in the process of calling a capability provider when it's killed: unfortunately there's not a ton we can do on the provider side. When we tell it to shut down gracefully, we make the request and the provider can clean up its resources, but for an OS-level kill like this, this feature won't help that scenario — but it will make sure the provider is there for the next invocation. Is that where you were going with the first question?
ossfellow 13:56
It was just about leftovers, right, and what impact they might have on later operations. Imagine, let's say, key-value where we register that secret, store a reference to it, a handle to it in the runtime — and then it kind of remains there, right?
Brooks Townsend 14:23
Actually, after each invocation of a component, just like we clean up all of its existing linear memory, we also clean up all of its resources. Because each individual instantiation of a component has its own set of resources, so we don't keep anything around between invocations.
ossfellow 14:51
I see. Thank you.
Brooks Townsend 14:54
Great question. Your second question, around a component calling set-link-name so it can call a capability provider using a different set of config or a different target for the same interface — I think it's the same scenario. If the component was in the process of executing and reaches out to a provider that had panicked and exited, it would need to handle the error there. But once the provider is restarted, as soon as you go back through your component logic to execute your set-link-name call again, all of the same links and configuration will be present. The reason we go back and re-form that config and re-fetch secrets during the restart is that the information the provider had when it started has been updated over time — the host said "hey, you received a new link you should configure, your configuration got updated" — so we're just bringing the new provider up to speed with the one that just exited.
Great questions. In the ideal case this basically doesn't happen — it's uncommon. I don't believe any of our wasmCloud capability providers are designed to exit on a failure; if there was an issue defining a link to open a port, the provider would report a failure but not exit the entire binary. So this probably won't come up too often, but it might be really useful when developing new capability providers — we now have additional failure modes to play with, and it keeps wasmCloud a little more resilient. Same way we do with components: if a component panics during an invocation, we don't get rid of the whole thing, we just make sure everything is ready for a new invocation. This one should land in wasmCloud 1.6, the next minor version, since it's a new feature. You all probably won't even really notice it, but it's a good thing to have for resiliency in the background.
Yordis Prieto 18:12
Are you supposed to be sharing the screen?
Brooks Townsend 18:15
No, I don't think so — I just like stopping the shares so everybody can see everybody's face, but I'll share again since we're at the end of that one. So we actually have another demo for you today, on data aggregation for benchmarking. Last week Taylor came on and talked about the Helm chart for doing benchmarks in wasmCloud, and this is a continuing build-up on that work. Taylor, would you like to take it?
Liam Randall 19:31
Okay, so this is just a continuation, like Brooks said, of what happened last week. We added a few extra features we figured would be handy. I already did the install steps so we didn't have to wait for that this time. We have a new version that's cut — it's 0.20 of the chart, I just cut it this morning. It still behaves the same, but you'll notice new text here, the most important thing being that now I put a little command in there to wait for the test to be complete based on what test it runs. Obviously this is going to finish immediately because it already ran a little while ago. And then it also has the ability to get the results from ConfigMaps. So now the test by default writes all of its summary results out as JSON into the ConfigMaps.
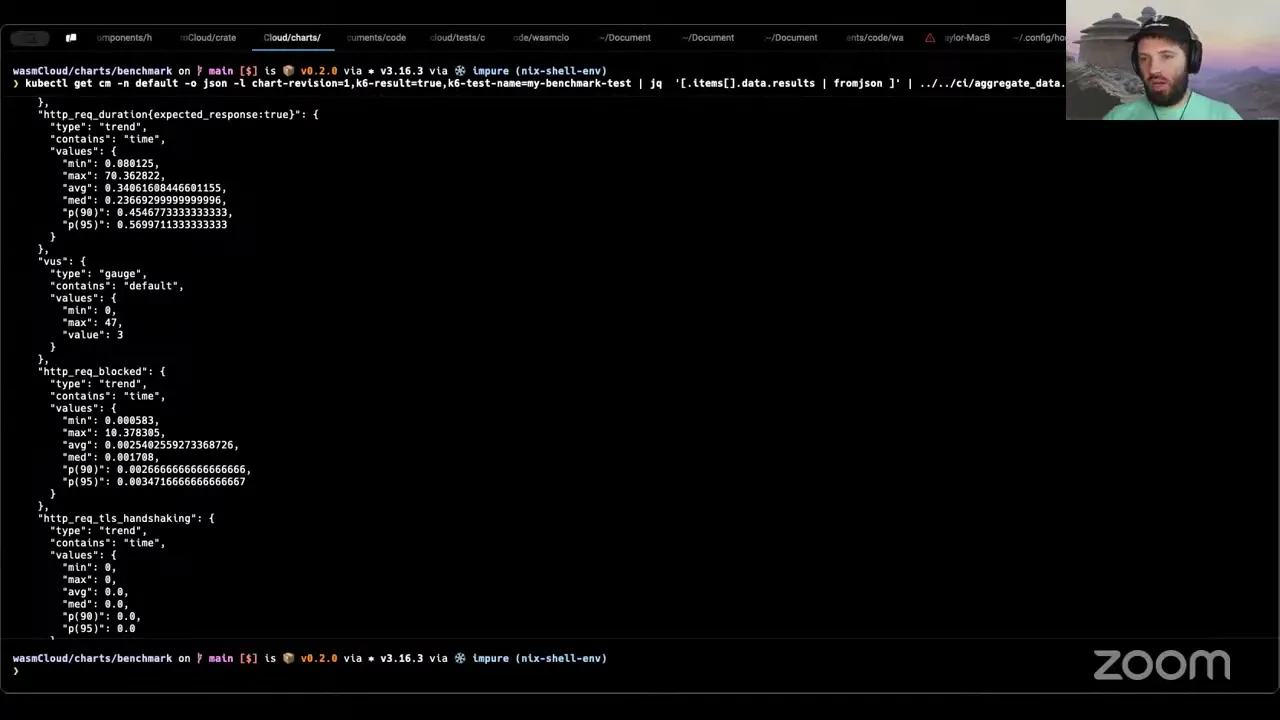
So if I do kubectl get cm, you'll see I actually have some from my previous test — there's one for each of the tests I ran, labeled so that each time you run it, if you run it multiple times before you uninstall the release, it'll do it. What it lets you do is — there's this nice little command with JQ that takes these and prints them out, and aggregates them into a JSON array of all the different results from k6. The reason I did it this way is people are going to want to do different things with these. If they use this chart, they might want to split them up and store them in an S3 somewhere — there's a whole bunch of things they could want to do. So the whole idea was just letting people do whatever they want by putting these results out there. There's an example, slightly hacky but it does its job because it's a Python script in the repo that aggregates all the results.
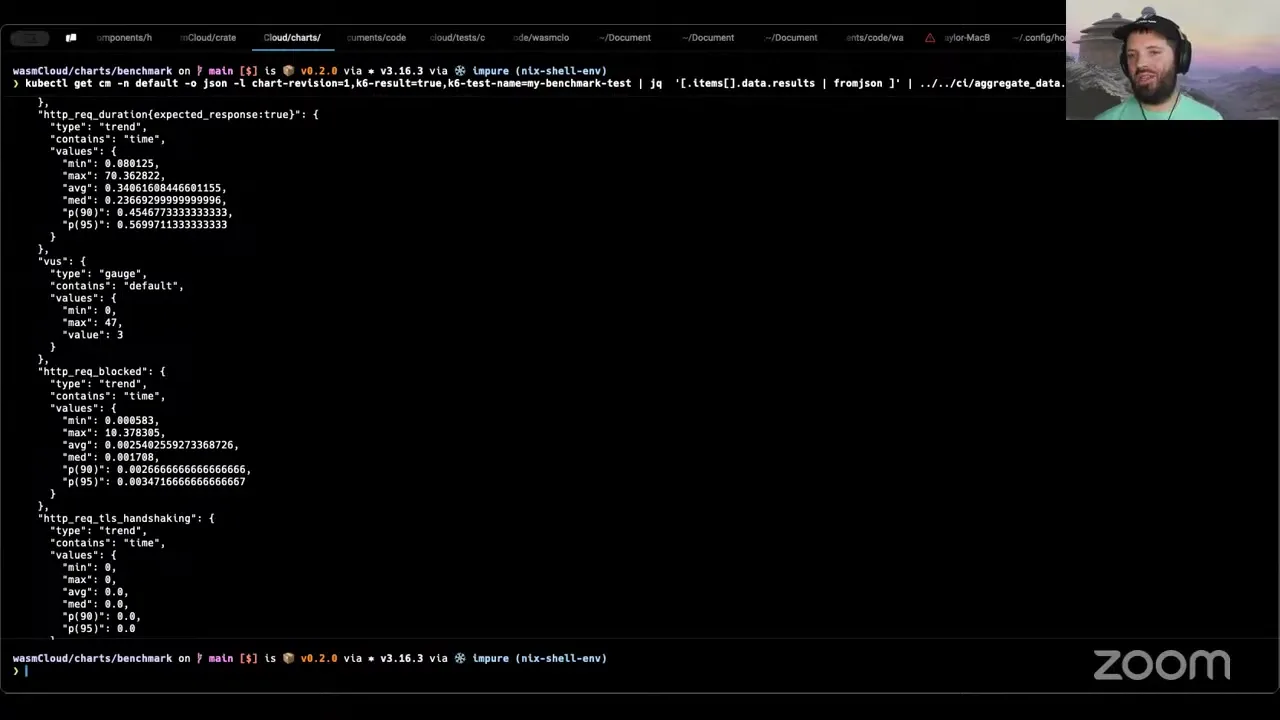
We're going to be using this for a pipeline that will run against testing infrastructure once we have it from the CNCF, to run benchmarks and collect this data. This thing takes the results from standard in and aggregates them all into a single JSON blob — so you have all the counters put together, total requests per second, all those kinds of things. You can do whatever you want with the data. The whole point of showing this is that now it's automatic — it puts the data into a place where you can consume it from, and you're able to take that data and do whatever you want with it. Any questions?
Brooks Townsend 22:37
Yes — hey, Taylor, so I think you said the next step is we're looking for testing infrastructure from the CNCF, a place to run this. What do you see as how we integrate this into our repo? Is it like we'll run a benchmark every certain time, or every PR release? How will people see the results of this?
Liam Randall 23:16
Yeah, it's going to go in stages. Lucas demoed about a month and a half ago an example of running these benchmarks, and these are based off of that. Essentially we're going to have a CI pipeline that's scheduled weekly — Justin's like "Kubernetes cron job," well, we could do that, but we're going to have this inside the wasmCloud pipeline. It'll either spin up the infrastructure or use a Kubernetes cluster that scales to zero — if we can get the control plane to be free, it'll spin up the infrastructure there and run a fairly large test. This is supposed to be running at production-level requests per second, just to show what that looks like.
The MVP is getting the pipeline out, having it run weekly or against specific branches a maintainer can trigger — so when some of the Preview 3 stuff starts landing, we'll do that. My first thing is just going to be that it spits out the JSON in a step in the pipeline, and there you go. We can then start storing this in a specific location and maintaining historical graphs and all that. Even just having the build results stick around will be good enough to start, and we can improve from there. It gets all this groundwork in for people to take on good first issues, like "hey, we want to store this somewhere" or "we want to visualize this in a certain way." That's why there's that new CI directory at the top level of the wasmCloud repo right now — it's basically that script and a Dockerfile for the k6 runner. We changed to our own custom builds so we can do the Kubernetes things inside of it, which is pretty standard practice in k6.
Brooks Townsend 25:41
I have a dumb question — anyone else, please feel free to raise your hand and cut me off as the question person. Why are we looking for special infrastructure for this benchmark test? We have a lot of things in pipelines.
Liam Randall 25:59
Because it's big and chunky. That's what it comes down to — we want to make sure we're running it against something that looks like production. The reason we're using Kubernetes is we're using it for what it's good at: spin up the infrastructure. It'll spin up NATS, spin up the wasmCloud cluster, have multiple hosts that are all part of the same lattice, schedule an application across all of them, pin it to one per node, and then hit it really hard. We'll see what we get from the CNCF — I don't know if we'll do the same 100,000 requests per second we were doing — but we'll get a good result from it. We need the micro-benchmarks that happen too, the things that tell us "okay, what's one host look like with this running," because we can tell a lot from there and that's a lot cheaper and easier to run. And then this is for the bigger checks. Bailey brought up the last point in chat: we need stable, completely isolated infrastructure outside of the build pipeline, dedicated for this test, so you can have that good benchmark value no matter how you run these. That's always one of the problems of benchmarks — you have to make sure it's in a clean environment that nothing else is affecting. So all those things are going to be done running inside Kubernetes. Gotta start somewhere, and this is that somewhere.
Brooks Townsend 27:54
Cool, yeah, makes sense. Justin had a question.
Liam Randall 27:56
It's tangential but related — I'll say it after, in case there are other questions related to this. For those who might not be in the Zoom meeting or on YouTube: it's NATS for wasmCloud, making good use of Cilium on the network. You put everything behind NATS. Over at Cosmonic, for some of our network isolation we use Cilium internally, wrapping over the top of wasmCloud. Cilium has never been used directly inside wasmCloud — everything is still NATS, especially for the control plane layer. We've started adding other additions: there are certain core things like the HTTP server that can run as a plugin via a provider, or as a built-in — that's an experimental feature. And then there's stuff Colin has been working on around connecting other things in. So there are multiple options here, and as we evolve — now that we've gotten to a point of stability and people are using wasmCloud for real things — we're addressing those use cases to make sure this is as pluggable and extendable as possible.
Justin 29:43
Back to you, Brooks.
Brooks Townsend 29:45
Alrighty, awesome. Thank you, Taylor, for coming on and talking about it. Everybody should feel free to just throw demos and things on the community agenda — they're always welcome. I think we're good on demos for today, but we do have a couple of discussions. The first is that wash 0.38 is now released — feel free to take a look at the release notes. We also released the new version of wasmCloud, 1.5, but I think we talked about that already. wash is generally the delivery mechanism most people get the latest and greatest things from. It was a little long coming to get from 0.37 to 0.38, but there's a bunch of fixes in here for wash dev fetching WIT with wackage, smaller things like colorizing text, and a PR that outputs version information as JSON — wash --version -o json.
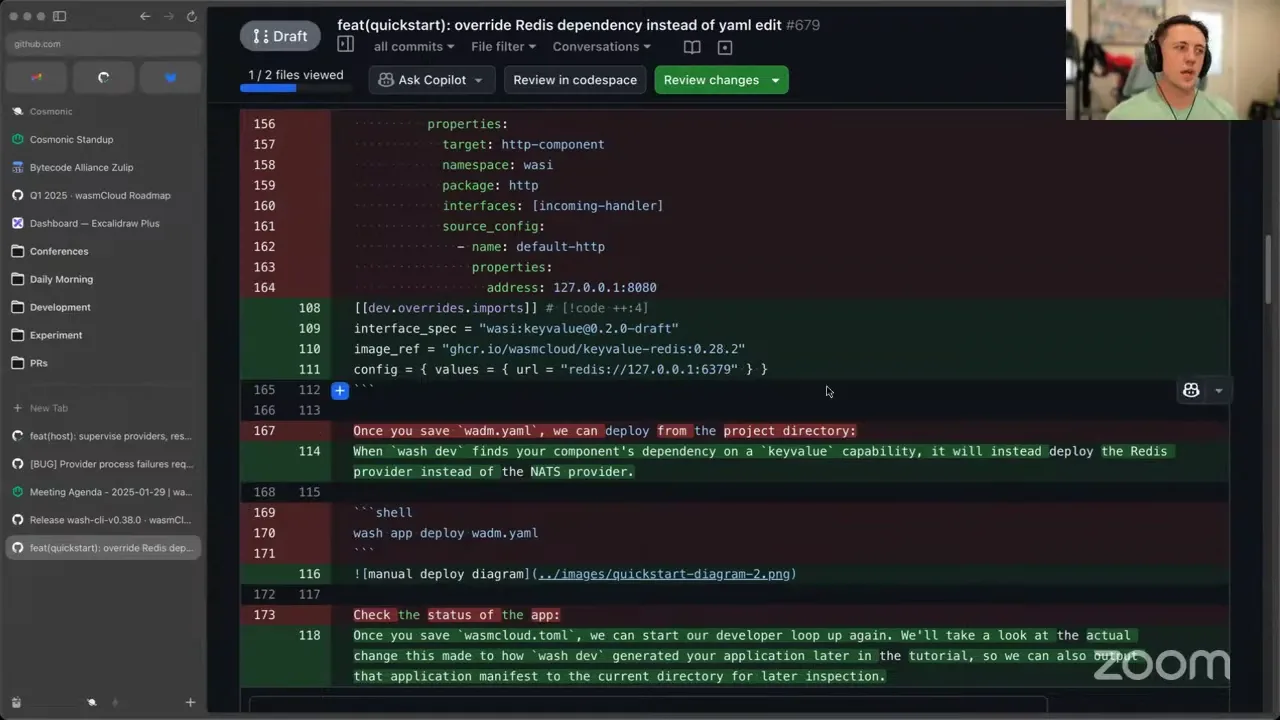
Notable new features over the last month: one is extended registry overrides, which is huge for overriding the WIT dependencies and where you pull them from. This is a new format in wasmcloud.toml that lets you easily specify where you want to pull a WebAssembly or WIT dependency from. For wasmCloud bus you can pull from a custom GitHub repo; for this interface you could pull from a local file on disk; for that interface you could pull over HTTP from a zipped-up tar.gz, which is kind of how WIT deps worked before. This should prove a whole lot nicer for folks operating wasmCloud and the developer tooling behind proxies or pull-through cache registries — if you need to point at an Amazon registry or an Artifactory registry instead of GitHub or GHCR, this should be a whole lot easier, because it takes effect during build time. It's all nicely documented on our site. I think Victor implemented it and also did the documentation — so thank you, Victor, for all the things.
Other things coming in: there's now support for interface wildcard overrides in wasmcloud.toml. In the TOML we have support, when you run wash dev, for using a custom interface or a custom implementation of a provider that isn't our built-ins like the filesystem or NATS. You can now specify an overridden capability provider, say for your imports — anytime you call a function for wasi:keyvalue with version 0.2.0-draft, whether it's atomics or store or batch, we're going to send all those invocations to the provider found here. So Redis instead of NATS, and you can also pass configuration. The PR you're looking at here is the integration of this into our wasmCloud quickstart, which should help streamline the initial development process and override some of those dependencies when wash generates the declarative application for you.
Liam Randall 34:25
I have a question about this. We've talked a long time about a world where I just take a standard component and give it to wasmCloud and it just runs. Is this a step in that direction? What's your thinking as you collect all this experience across the ecosystem — what direction is this headed? More declarative, or less, or optionally both depending on which path you take?
Brooks Townsend 35:03
More — and/or less — declarative. The thing I love about wash dev is that as a developer you just write code, wash dev builds the component, and then we inspect the component for all of its runtime dependencies. We talk about them as capabilities — if you need HTTP, a key-value store, a blob store, these are all capabilities that wasmCloud understands. We have implementations of these capabilities and we know how to create a declarative manifest for you. If you use a custom interface in your component — one you've created, or one that's not a WebAssembly standard, so we don't know about it — then our best guess is "hey, this is a custom interface," so we put a placeholder in your declarative manifest and you have to go fill it out. What this feature does is let you, because you the developer know the custom interfaces you're using, give wash dev the information it needs to build the full declarative manifest for you. So this is really useful as soon as you get past the initial development process, or when you step outside the bounds of just using WASI interfaces — you can still take advantage of the same hot-reload loop and declarative development process, but give the wasmCloud tooling enough information to manage that for you.
Liam Randall 36:47
Do you think you'd have the ability to override default capabilities — like if you wanted to use a different KV store?
Brooks Townsend 36:57
Yeah, absolutely. That's exactly what we'll do during the quickstart — we'll override the NATS key-value store with Redis, to show an example of overriding the default implementation and connecting to a Redis key-value store, which you may be more used to interacting with in your developer flow.
Liam Randall 37:36
I think people laugh because we work together and obviously talk all the time, but I generally am curious, so I wait and ask the question now for a bunch of reasons. One, I want to share your response with the community, and two, I want to hear everyone else's reaction. This is really material, and ultimately it's a direction we've been excited to go for a long time. You think about having to declare everything years ago, and now we're at the point where "just give me your component and I'll do everything I can to get it going" — that's the first great developer experience. But we have two customers here: we also have platform engineers, who want to be able to write that output, commit it to a repo, and have a historical record of what capabilities were being used at any given time. So we have those two different experiences to offer. I love the direction we're headed in, which enables both workflows — when we don't have information, we do as much as we can to make the experience feel magic and "just work," and we still empower users who have a reason to be incredibly declarative. Great job to you and the whole team, including all the new leaders in the community.
Brooks Townsend 39:46
Great work, everybody. What were we talking about? Yes, release notes. Let's keep cranking. So that was one of the big features. The other one, which is awesome and I got to use for the first time today, is that when there's a new patch version of wadm or wasmCloud, wash up will actually go and download the latest patch version. We have our own rigor around adhering to SemVer, but a big problem before was you'd have to do a whole new wash release just for patching the smallest wasmCloud thing, to update the included version. This really helps us roll out new versions to people running wasmCloud locally. When you run wash up, it goes and checks GitHub — which can fail, and it's not really worried about it, it'll just use the one it currently has on disk. I wanted to thank Mark especially for putting in the work for this feature, and thank all the contributors who put in things related to wash since the last release.
So, speaking of wash — and we're moving on to the roadmap next — there is one thing on the maintainer side. We had a maintainer, Ahmed, who I don't think is on the call, but Ahmed, thank you so much for stepping up and expressing interest in consolidating wash CLI and wash lib. To set the stage: we have a crate for the wash binary and a crate for the wash library, our whole goal being to make it easy to import the library functions and reuse them in your own Rust application. But we started this project a while ago, we've gotten more advanced in our Rust usage, and one thing that commonly happens is when you contribute a new feature to wash you add it to the library and then add the usage to the binary — that's an extra step we don't really need. The proposal is to combine this into just the wash crate. Thank you to the original owner of wash, who registered it quite a while ago and transferred it over to us, so we own the wash crate now. You can run cargo install wash.
Combining two crates is quite a big refactor. We could do it quickly in a medium-to-low-effort way, but then it'd be a weird jumbled release, so we want to work through it. For folks considering taking on some of the bigger issues around wash CLI and wash lib, you may want to run it by the maintainer team or leave a comment on the GitHub issue — because while we're migrating, we're going to create a separate wash crate, deprecate wash CLI and wash lib, and I don't want a really big feature or refactor to go in after we've started and then need to port all of it over. So this hasn't started yet. We'll do our best to keep the API similar, because we don't need to change functionality — the first bit will probably just be straight up merging the two crates and then de-duping. It should result in smoother releases for us and easier parsing of the repo for you. Do folks have any questions, either on the wash release or the combination of the wash crates?
Brooks Townsend 46:35
ossfellow, you pointed out in the Zoom chat that you're working through some things — writing workflows and everything, and you have wash CLI everywhere. So switching over for a new release would certainly require an update on your side. Do you have any concerns there, anything we could do to help?
ossfellow 46:53
Sorry, Brooks — I'm working through the provenance things in wasmCloud workflows, and that's where I'm saying it's being referenced in a lot of places. So as part of the cleanup there will be a need to also clean up the jobs.
Brooks Townsend 47:14
Okay, that's a great call-out. So you're calling attention to the fact that on our side we have wash CLI in a bunch of places. Just to make sure — is any part of the provenance pieces happening in wash CLI or wash lib?
ossfellow 47:44
No, all of it, this first phase, is just in the workflows. And I'm going to stand up a demo — not a community demo, but the demo site — so you can see the outcome of the actions and understand what's going to happen once we commit the changes.
Brooks Townsend 48:08
Awesome, thank you. Feel free to upgrade that to a community-side demo when you get it ready. Of course, we're going to keep you all updated — once we start working on the crate merge, I'll bring it up in the community call to say "hey, really, officially, just hold off for a week while we do the migration." I think a lot of the features on the roadmap — look at that, it's time for the roadmap check-in — are on the wasmCloud side, the protocol side.
So the last thing on the agenda, just a roadmap check-in. We might have been doing these every week since we created the roadmap — we probably don't need to do them every week, but there's been some movement in the last couple of days. As mentioned, the Helm chart for benchmarking wasmCloud is complete, so great job, Taylor. We've got a couple more things in progress now: Roman has been doing a lot of awesome work on the GitHub Actions and Nix side to rework the way we build providers in our workspace and build binaries using our Nix flake. The output of all this is a faster CI, because we're only building what needs to be built, and it'll make releases quicker. If you're using Nix locally, you'll have an easier time building an individual binary. I marked consolidating wash CLI and wash lib as in progress to help socialize it for folks watching the GitHub project.
The rest of the things here — there's a lot on the documentation and improvement side related to our protocols: defining things like Cloud events, the control interface, policy, those APIs in a language-agnostic IDL, or even just generating a JSON schema from it. These are things we haven't started work on yet, but we've started spiking on possible solutions. One example we already do is in wadm — for the application format, we take the Rust struct that we parse and generate a JSON schema from it, and you can even import that into VS Code for suggestions and type hints. We really want to propose some of those options, and it's probably best if we do the same thing everywhere.
We do have a good couple of ready-for-work options on the roadmap. Some are assigned out, but especially these in the improvement tab are great first issues for people getting started contributing to wasmCloud — high value, low effort, good first issue. So that was the roadmap check-in. I know we planned a lot of things on this roadmap, we were a little ambitious, but I believe in us. Looks like we're running up on time, so I'll open it up generally — is there anything people wanted to talk about on the wasmCloud side, the broader WebAssembly ecosystem, your favorite sandwich, anything like that? Liam.
Liam Randall 55:41
Awkward Liam again — maybe just one call to action. I would remind everybody in the community that anybody can demonstrate at the top of the hour. Don't get me wrong, I love a good Brooks demo as much as anybody else, but I know there are a lot of companies, individual developers, and tinkerers working on things. We'd love it if you reach out to Brooks on wasmCloud Slack and see if you have anything you want to share. Just a call to action — it's a community, and lots of folks are welcome to participate.
Brooks Townsend 56:36
Hi, folks — then I think that'll be it for today. Thank you everyone for coming to the community meeting. We don't have a special holiday next Wednesday or anything — I'm afraid of it now, we've had so many holidays on Wednesdays lately, but we're good. So I think we'll see you all in a week. Have a wasmCloud day, everyone.
Bailey Hayes 57:37
So there are a couple of different Golang meetings that go down. Masaka was here — he's the one that chairs those meetings now, and he takes really good notes, so I don't always go unless I get summoned. The progress being made is really good. And if you haven't tried out our Go SDK, it's also really, really good — you can create breakpoints and debug through your tests and everything. The type of Go code you write is no longer too strange; it looks basically like idiomatic Go code, which is nice. And in the rest of the upstream world, we're making WASI Preview 3 go vroom. It's very exciting, and we're trying to do it by the end of March.
What's coming in that pipeline is native async, which basically means I can compose components together via effectively structured concurrency, whether or not they're async or sync. If you're familiar with the function-coloring problem of async, this is the solution to that. If you've ever had the problem of composing multiple components together and it gets complicated because you're using pollables, that problem is gone with WASI Preview 3 — this is specifically to solve that. What you have in WASI Preview 2 will have a really easy adapter, just like from P1 to P2, so P2 will adapt straight to P3. I did change some of the APIs in WASI clocks, because I now have true async and don't have to wrap it with WASI I/O types — I have types that are part of the component model's ABI, so I can say "wait for" and it returns an async handler, versus what we had to do before, which returned a pollable, a callback-based API.
If you want to know exactly what it is and how it looks, Luke Wagner gave a talk a year ago, and we're basically implementing that — everything he predicted is pretty much spot on. We did make a decision today to have an annotation that says whether or not something is async, versus having everything be async by default.
Liam Randall 1:00:39
It seems like that was what we said a year ago — that everything wasn't going to be async by default.
Bailey Hayes 1:00:45
No, I think you assisted in that. Luke presented that change today in the component model bi-weekly. And I guess I'm not the only one hanging out in the upstream — Victor's doing this for JCO, basically working on the second reference implementation we have to have to be able to ship Preview 3, and Roman's working on the Wasmtime side. So a lot of wasmCloud folks making it land.
Yordis Prieto 1:03:06
Bailey, I talked to some person who is like a leader in the CNCF and DevOps space. He has a YouTube channel. I had a conversation with him about the WebAssembly stuff, because he keeps repeating — I feel he expressed multiple times — that it's like WebAssembly versus Kubernetes, which we know is not right. I don't know why that's a feeling outside this bubble. But second, his perspective: because he knows container-first and all the tooling is much further ahead, his curiosity is "how can I bring WebAssembly into my stuff? I don't want to care about the WebAssembly side." From my perspective, well, just put an HTTP there — any WebAssembly component, just an HTTP or RPC or whatever communication protocol you want. But I didn't know how to answer precisely. What is the elevator pitch for how you bring those people — who feel WebAssembly for now is secondary and has to be injected into the existing platform — out of that mindset that it's too complex, or that fear of the unknown?
Bailey Hayes 1:05:10
I've heard a lot of people take a stab at this in different ways. The one I usually say is: if you use wasmCloud, it deploys on Kubernetes. If you're using our operator, it's going to create all of the Kubernetes abstractions so the containers can talk to WebAssembly components and vice versa, and you as a platform operator can continue being a Kubernetes expert. So it's not an either/or choice. Kubernetes is wonderful at abstracting your infrastructure — it's not amazing at being your abstraction for applications, and that's the problem we're trying to solve with WebAssembly and wasmCloud. That's usually the takeaway. And then if they ask more about the networking side, there's always the case of — with wasmCloud you can pass in and create your own custom interfaces, so if there's something we don't have supported in WASI or by an underlying standard, you're not locked in: you can add it today and have something implemented tomorrow. That usually helps a lot of those folks. But hey, I'm glad to hear you're out there evangelizing for us — I appreciate it.
Yordis Prieto 1:06:31
I work in the dark, but trust me, I do a lot of work to support you to the best of my abilities. Justin, you mentioned container-to-Wasm — I don't have any experience with it, but if I see that word, the first thing that comes to mind is "why, what's the point?" Should that be the path forward, or should it be "no, don't fear too much, you don't need to worry about going from Wasm to container or vice versa"? Because there are some people taking WebAssembly and making a container, and you could see it as kind of pointless — you're jumping around just to end up back in the exact same spot.
Justin 1:07:26
I think it's one of those classic "it depends," right? If your existing infrastructure is all already over here, or you're going greenfield — you can cut it up a lot of different ways. The point Bailey made was that you have flexibility where you need it to do that.
Bailey Hayes 1:08:34
Usually somebody deeply invested in the Kubernetes ecosystem sees the approaches some folks take where they're trying to pave away the keyboard, and there are other approaches like taking over the whole node — Nvidia took that approach at one point. But now both seem to be landing on: if you just run your host in a container, you get all the benefits of what you've already built, whether that's your CNI or your storage layer or all these things you've set up. You can just keep using it, and it keeps working — and you get so much better resource density and solve the cold-start problem. I don't love it when I see folks treat individual applications as one container with WebAssembly — one host to one app — because you lose all the key benefits of having moved to WebAssembly. And let's be honest, it's not free to move to WebAssembly today, so you're just having pain, and then when you try to convince other people to do it that way you don't have a very strong argument, because you're not showing off the benefit.
I was in a somewhat similar debate earlier today — there's one camp that says no matter what you do, you're always going to bring in the whole POSIX world. If you're building with Go today, it requires the WASI CLI; out comes a component, and whether or not you're using a socket it imports that API. There are lots of solutions in play that people are working on, but the reality of the guest toolchains is that basically everybody wrote their standard language libraries assuming POSIX, and now we're going back and retrofitting those to be more capability-driven — to be totally aware of when you're doing things like ambient authority — to push the ecosystem toward something safer, more secure, with tighter controls. I get why people want to do the container-to-Wasm thing, but it's like "I'm going to take the whole world and shove it into the Wasm world," and you run into that problem. I think working with the upstream toolchain authors, we'll get to the place where what gets produced is exactly what you use, and that'll be amazing. Where we are right now is really just a stopgap. And I love what Lucas just said: with container-to-Wasm you maybe now have two problems — some of the challenges of WebAssembly, plus all the same issues we have with containers.
Yordis Prieto 1:12:09
One request — I don't feel qualified to do it, but if wasmCloud could have one blog post, maybe it already exists, just to point those curious people to — the ones who have the stance that it's additive and has to be integrated into my platform. What you just said, "don't go with the whole node, this is an anti-pattern," is much easier for me to link to than doing a bad job explaining it myself.
Bailey Hayes 1:13:21
Yeah, so I linked a blog post that's largely based off a talk Lucas gave — I'm curious if that one satisfies what you're looking for, or if there's more we should add. At the end of the day you can't just have one blog post to rule them all; you've got to keep releasing them, keep beating the drum, so it stays fresh. I do have one from two years ago that's what you're looking for — it's on InfoWorld, but it's a little too verbose and not direct to just the Kubernetes story. So I hope it's this newer one, and we can refresh it.
Well, I'll try to give a more formal WebAssembly update — maybe not the next community meeting, because we're still in the woods right now, but maybe in two weeks. We could draw a picture of "okay, this is where we are, this is how you can try things out." If you're ready to join the fray, it's the bleeding edge — emphasis on bleeding — and then a little better fidelity on when we think these things will land and what they'll look like, like us waffling between "is everything async, or do you opt into it" — those are key design decisions that have to be completely locked in, otherwise you might be wasting your time.
Yordis Prieto 1:18:40
You know one thing I'm now facing issues with, from the semantic-meaning perspective — and I don't think you'll have this problem — but in Protobuf it's driving me nuts that I cannot define the error that I have in the services. I'm going into this deep rabbit hole where everything is a message, and in Protobuf when it comes to errors, you don't say what errors you get back. Now my clients have to ask "what error do you get back?" and I'm like, "I don't know." From the specification perspective, I know you have the result type and that affects it already. I appreciate that you didn't make that mistake.
Bailey Hayes 1:19:24
One thing about proto that would be really cool to start building out in our ecosystem — especially if you're doing this, maybe you can come help us get it done — is we really want to have proto map to basically wRPC.
Yordis Prieto 1:19:42
I mean, that already — but a few things are messy as it gets, also in terms of probably versioning.
Bailey Hayes 1:19:47
For sure. Alright, I'm going to slide my bowl of soup back over here.
Yordis Prieto 1:19:52
Justin and Lucas, both of you — I know your experience, so please give me feedback here, because in terms of errors I have an ADR open since 2022, and I was already doing it professionally for at least two years. So basically I'm five years trying to write an ADR that is truly valuable, professionally speaking. This is one of those where I'm passionate. With Protobuf, you have the result type, you can encode the messages of the error itself into it. And in gRPC, Google — you're going to have some level of structure, but then they have this field called "details," which is an array of Any. What do you think is going to happen? Most of the domain errors are encoded into this type that's "oh, whatever you want" — and I need to understand the domain errors, those are the ones I care about most. You get the HTTP 200, great, but what happened? Array of anything, and now you don't know how to discriminate, like pattern matching on a union type, so you guess it at runtime. I just feel that Protobuf is not superior — for a specification perspective it's just limited. At some point I just want to go from WIT to Protobuf instead of the other way around.
Lucas Fontes 1:21:40
It's open — it's just whatever you want. Oh, you want to represent errors? Create a message that is an error and use that everywhere, and that becomes the standard. So I do agree — I feel like with WIT we have the option to make that story way better. It comes down to defining the proper error type and making sure that, the same way we have result as a keyword, we have error as a keyword.
Yordis Prieto 1:22:13
Yep. Justin, about that ADR — I'm one of those who, before I put something into practice professionally, I do my homework, the same with even event sourcing: I took three years just reading and making sure I understood. With that ADR, the research happened back when Stripe was trying to normalize APIs, and I did reverse engineering of absolutely every major API out there — Google, Stripe, Amazon, all of them. Okay, what are you trying to do here with the error type? Some people do it this way, Twilio, some people do it that way. I took it all the way from infrastructure, platform engineer, product engineer, customer support, internal tooling, and clients. Five years of asking every single engineer like you, "give me strong opinions, I want you to destroy this." And every person who comes across it always says the same: "yeah, I already thought about this, here's the answer." So I've been committed to this error problem for a long time, primarily because I think I found something that could be "do this, without the 95% — do this unless you have a strong reason not to, for the next 10 years."
Lucas Fontes 1:24:57
One thing I noticed here is that you're really talking about how to signify errors, and not stack traces.
Yordis Prieto 1:25:07
Exactly, yeah.
Lucas Fontes 1:25:09
I feel like there's a bit of a convolution happening in WIT in terms of what is an error and what is a stack trace. I haven't checked the latest on where we landed with this, Bailey, but I really want to make sure we don't conflate those two things.
Bailey Hayes 1:25:29
We do have a concrete error type, and then we have an error context. The error context is where, if you wanted to add a stack trace, you could.
Yordis Prieto 1:25:37
Yeah, in the spec — Lucas, by the way, the write-up, the extra text, is broken. I put at the top "focus on the scheme itself, not too much on the writing," because I made a mistake in the spec on stack traces. Look, man, it's an array of strings — I don't want to touch it. I don't know your language, I don't know the syntax, I don't know the format. It's literally an array of strings. If it's one string, your problem; if it's multiple, your problem. That's all I did, because I'm focusing on the actual error, not the exception. And yeah, I think going from WIT to Protobuf will probably be a much better strategy than the other way around by now. That's just my opinion.
Bailey Hayes 1:26:30
I don't know — it seems like WIT is, in some cases, a superset of Protobuf. So it's usually easier to go from the common denominator to the more complex case than the other direction, is my guess.
Lucas Fontes 1:26:49
There's also the "haters gonna hate" — does it matter? We're putting this back, we're not going to cover the case of a Raspberry Pi trying to send something and now they want to send some extra context for the error. So I'm kind of with Justin here — I think you did the research, you actually considered a lot, so just bang the gavel.
Lucas Fontes 1:28:09
One thing I find myself doing quite frequently is going back to JNI, CORBA, and RMI from Java in the late '90s, because a lot of those problems surfaced at that point and they did have some pretty interesting solutions. The whole ecosystem died — it didn't move too much — but they had these problems there, so looking at what was done sometimes shines a light on what we should not do.
Bailey Hayes 1:28:44
Well, and knowing why they died, right? They died for reliability reasons and security reasons, and that's fundamentally why we'll replace Java ecosystems — but their other choices are solid.
Yordis Prieto 1:29:00
Yeah. Talking about security recently, Bailey — that's why I care so much about how somebody will use this. I have a really good friend of mine, all he cares about is "I want more secure software." My point with the discriminated union and the layering — I thought about all the problems that happen in production just because of that. I want to start with security first, then domain. Where do I put the information, where do I tag it, how are you going to be able to decode it from the bottom up? So I started with the security model. I love it. Thank you, guys — this is one of those where I'm passionate, and I don't get to talk with many people about it, so the fact that you stick around to listen to me rambling means a lot.
Bailey Hayes 1:29:54
That's great. We need to verify our errors are correct for WIT — we have the same window where we can make some key design changes before it gets really costly, so we definitely want to make sure this stuff is right. And I really enjoy when people dive deep on any given problem they're working on.