Transcript: wasmCloud Q1 2025 Roadmap Planning on Kubernetes
wasmCloud Weekly Community Call — Wed, Jan 15, 2025 · 103 minutes
Transcript
Liam Randall 03:20
All right, hello everyone. Welcome to wasmCloud Wednesday for January 15. It's good to be back. I think we've had a pretty good set of community meetings so far this year, but this one is especially special — say that five times — it's our quarter one roadmap planning. So for everybody tuning in, this is the session where essentially we just go through the suggestions from the GitHub discussion for this roadmap. The whole point is for us to come out of this community meeting with a set of high-level issues, some high-level initiatives, things that we want to focus on as a project and as a community over the first quarter of 2025. And I will of course acknowledge that we are already two weeks into our first quarter of 2025. But that's okay. Time is a human construct, and we're all going to be all right if we start a little bit late.
Before we get started, I do want to say one quick thing that's not related to roadmap, which is there have been a couple of nominations for additional wasmCloud maintainers — people who have been showing up really well in the community, contributing over quite a long time. To be honest, it's a little overdue. I'm really excited about rewarding people for being a part of this community, because everybody who's on this call has been here for quite a long time. So we're going to be reaching out to some folks over the next couple of days, just to ask if you're interested in being recognized as a contributor and being somebody who's more involved in the project. I think in our next community meeting we'll recognize everybody and go forward from there.
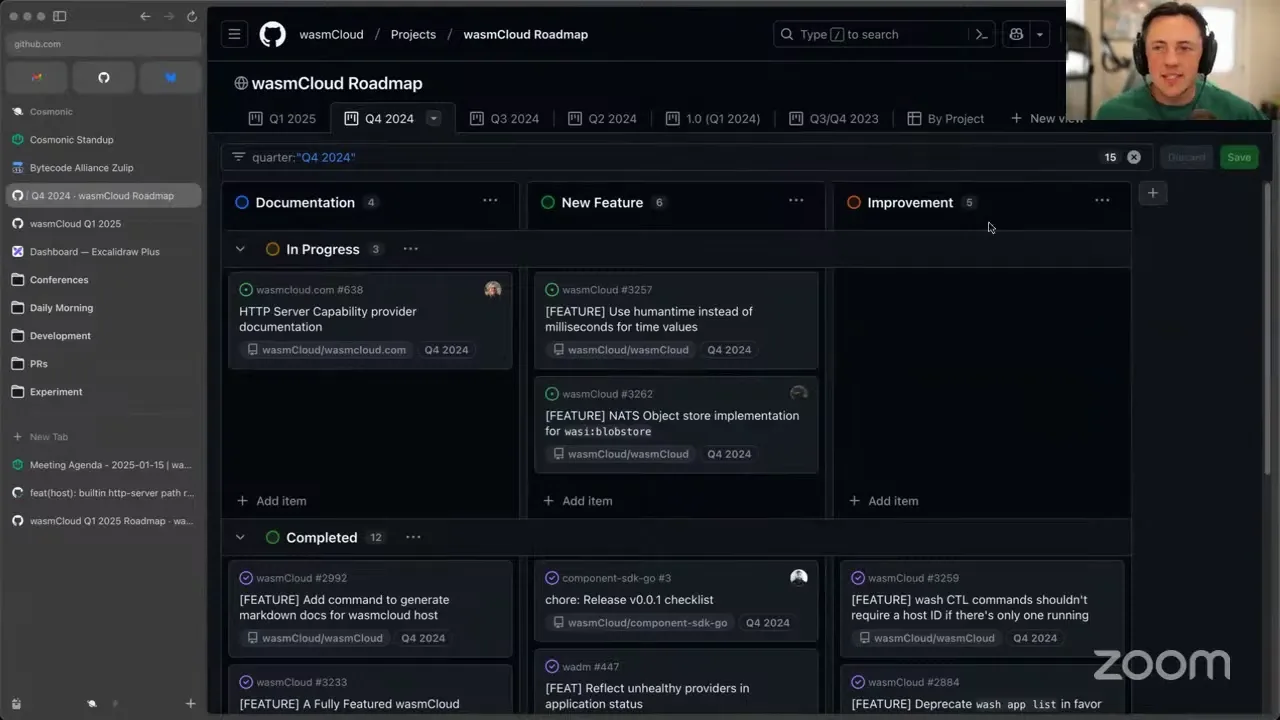
So, on to quarter one roadmap planning. I think it would be best for us to start by taking a look back at the quarter four 2024 roadmap, just to see what we set out to do and what's left, if anything. We've done pretty regular check-ins on this roadmap. We did a ton of what we set out to do in the benchmarking suite and testing, and some smaller issues that were great for people to get involved with. The things that are remaining: the NATS object store implementation — the WASI Blobstore is actually feature-complete, tested, and in a PR, this is just something we have on our maintainer backlog to review and get in. Masood, feel free to complain at this point if you'd like, for us being bad PR reviewers. Using human time instead of milliseconds is something that actually has a PR open; I think we're just waiting on someone to respond from the community. And then HTTP server provider docs — Eric, sorry to put you on the spot, is this already completed? We can't call it quite completed yet, so we might want to push that one forward, but it's pretty close.
That's few enough features on the previous roadmap, which really just focused on the project as we went to the incubating stage. We can leave these here and wrap them up as we go to the start of the year. So I did start on our roadmap project, which I'll go ahead and get linked out to folks. I followed the roadmapping process that's documented in our wasmCloud repo — it's a test for making sure that we can do this in a repeatable way, and anybody could lead one of these roadmapping sessions. I came through and created this board. The primary feedback mechanism I used to create the tickets are either things that have been on our issue backlog for a while, things that are requests from people running wasmCloud in various stages of development from QA to production, and from this GitHub discussion.
I really want to thank everyone here who contributes in different ways, and I really want to thank Masood, Florian, Mark, and Aditya for leaving comments here. There's a lot of effort to think around what you want to see come out of the project and leave these comments, so thank you so much for the feedback. I think the best way to run through the roadmap is to talk through the individual issues that have come out of this discussion thread, and then talk about what has actually landed on the project board. From there it's really an open discussion, so please, at any point, feel free to raise your hand and add some context. I'll leave a little bit of time at the end too for any additional feature requests. Do folks have any questions, comments, or concerns about just going through the roadmap?
Masood 10:25
I had an issue that we added to the roadmap in the previous quarter. It was about having an example that was evolving to documenting it — I was happy to have just an example of a custom provider that uses resources. That issue got closed because of inactivity, which is fine. My comment in general is that for items that are on the roadmap, shouldn't they get closed intentionally, rather than going stale and being closed?
Liam Randall 11:15
Yes, they certainly should be. I think this is maybe an oversight here. For any of these issues that are on the roadmap — and Lachlan, I see you have your hand up — we do have a roadmap label that will prevent it from being closed for being stale.
Lachlan 11:47
Recently the stalebot is actually deprecated, so I migrated it over to the stale-bot action. One of the things it does is it can look at labels, but it also looks at milestones. So if it's attached to a milestone, it won't mark it as stale. Just putting it on the project board doesn't prevent it, but if it's attached to a milestone, then it will. We are going to be in the process of removing stalebot from the org, but I wanted to make sure that everything gets moved across from anything that's got the stalebot configuration in there. So I'll add those as issues and we can tackle those too.
Liam Randall 12:59
Yeah, and it's a great question. The stale default configuration is either 60 or 90 days, but it shouldn't be staling out if we talked about it on the roadmap and then just didn't get to it until the end of the quarter. Okay, well, let's do the community feedback first and foremost. Masood, I think you were the first person to comment. Thank you so much for the compliments and comments at the top. There are a couple of things you mentioned that I wanted to make sure we had captured on the roadmap. The first, which you just commented on — document handling of custom WIT resources — we just got that one reopened. It looks like it was part of this roadmap, so I think it can just roll over onto quarter one. I also took your additional feedback around fixing and improving the testing framework. I interpreted this as our provider SDK testing framework — so tell me if I'm wrong there. But I know you worked with this pretty extensively with the NATS Blobstore implementation. Is that right?
Masood 14:47
Right. And there seems to be some issues within the framework. Again, considering the recent conversation we had, which was about making sure everything would have integration tests, I think a foundational part of that would be to make sure the framework itself is functional, and then asking for providers and those sort of use cases to also have an integration test as part of the delivery.
Liam Randall 15:31
Yes, completely agree. I do have this as a draft issue on the roadmap right now, just because I wanted to talk about it here. I know we talked about an issue with locking in tests that run in parallel. I really like the idea of having a standard list of tests, the set of things that we make sure we are testing — because even if we start with a baseline interface like Blobstore or key-value, we should be able to do the same tests for different vendors, whether it's an Azure Blob Store or NATS Blob Store. Run through that in each provider, and our provider SDK testing framework should make that really easy. On my side personally, it's been a little while since I've written a provider integration test, so I think it's worth a revisit from the wasmCloud maintainers. Let's drop back into the provider projects and write more integration tests.
Masood 16:39
Sorry to interrupt, Brooks. Whenever you get time — I know you've been very busy with holidays — to go back to that NATS Blobstore provider, I have a complete set of integration tests, so that will be a use case to identify some of the issues we have in terms of integration tests that we do for providers.
Liam Randall 17:16
Great. That sounds like a great way to feed two birds with one scone: do a PR review and check out those integration tests. This is something we've needed for quite a while. We put a lot of focus on the component development experience and testing piece, because that is what the majority of people do — but writing the providers is equally important, so getting back and giving them a little love and care would be great. So this one made it directly onto the roadmap. I think it's going to be well worth our time. Doing that across languages is something we'll also have to consider. The suggestions you had for improving the handling of the two edge cases for copy and move object for the different blob stores — I didn't bring this onto the quarter one roadmap just because I thought they were really specific and can get done at any time. The same thing with the watcher interface for a NATS key-value store. Does anyone have any objections to me not bringing those onto the roadmap? I didn't exclude them because I don't think we'll do them during quarter one; I just thought they were specific enough to be easy tickets once we get the provider testing framework in a better place.
Masood 19:17
You mean the watcher? Sure. The only reason for the other ones — I agree, and I've also mentioned it doesn't need to be there. But for that one, because it's a feature enhancement, we kind of classify it that way. Through regular issues, sure, that will be done.
Liam Randall 19:52
Okay, sounds great. Moving on, the only other one I saw was the implementation of wasi-nn. Masood, my ask here is — I know what the wasi-nn proposal is and what the interface is like — can I ask you to put together an RFC, similar to your attestations one, that goes through some of your thoughts around what you want wasi-nn to look like? I don't want to make too many assumptions about what you want to do for this one.
Masood 20:42
Yeah, awesome. So it was a provider for wasi-nn, but I'm okay to write up an RFC. Just to not take too much time — I want to bring a new provider as part of the WASI interfaces, at least one provider per quarter. I picked that because I might need to use it, but I'm also okay to swap it. For example, if something is more important — like wasi-messaging, that might have more broader appeal than something like this. So I'm totally open to what is more useful to the community.
Liam Randall 21:45
Okay, let's start a discussion — it can be a GitHub discussion or even in Slack. We've been moving a lot on the wasmCloud messaging side lately, so I think that's a good thing to tease out, but it kind of solidifies that maybe we don't need to bring it onto the roadmap yet. All right, moving forward. Florian, your suggestion here for an already-started implementation around the wash app and wash control subcommands to do tab autocomplete — please, I will buy you a coffee or anything to get this one done. This would make it so much nicer to work with the CLI. So this one has already started, and the original contributor of the PR did say they could really use some help getting it across the line. These next two items, you may be delighted to know that we actually do support now — you can do a wash app deploy with the application YAML, and it'll go look for the name in that YAML. What you're alluding to is exactly where we want to be: reusing the muscle memory of developers who have already used kubectl or Nomad. Let's just make it work the same way you would expect.
I also brought the RFC for provenance and attestation onto the quarter one roadmap. Masood, after scanning this morning, I think phases one, two, and three are probably in scope for this first quarter. I think we can start creating sub-issues to tackle them individually. Actually getting into phase two would be really useful for people who are trying to generate their own SBOMs for wasmCloud applications, and then the external integration — some folks in the community are also really passionate about this.
Masood 24:55
If at least phase one is endorsed, then I'm open to having an issue and implementing that, because I have done my pipelines too.
Liam Randall 25:10
Yeah, let's start with phase one — phase one is certainly in scope. It'd be great for folks who are interested in learning more about provenance and attestation security to get involved. And one more: Florian, you had a specific ask around these link traits, which was great. That one is now reflected on the roadmap under an issue in the wasmcloud.com repository. Just generally, as wasmCloud has matured as a project, we have APIs, CLI contracts, and interfaces, and we should really be holding ourselves to a high bar in terms of not breaking them. Some of those have made it onto the roadmap as more specific issues, like auto-generating wasmCloud and wash CLI documentation on release. We already have a process for generating docs for the CLI, but doing it so that we release a new version of wasmCloud and then a workflow auto-generates the documentation and updates it will really help us not have out-of-date documentation. I didn't create an issue for discussing a formal process for communicating breaking changes, but I think this would be a great community meeting topic — how can we better use the conventional commit style that we enforce in the wasmCloud repo to mark what has changed? We can do that really well programmatically. Florian, did I capture your suggestions pretty well?
Florian 28:35
Yeah, completely. So many things.
Liam Randall 28:37
Awesome. Moving right along — Mark, I really loved the suggestion to get back to the multi-tenancy support. That was another RFC that got staled out. I think it was a really interesting proposal, but ultimately we didn't have enough evidence around the way we wanted the feature to work, so it felt like a lot to bring on when we didn't know. I've left that one out of this roadmap; feel free to object. I think we'd love to come back to it as soon as we know how we want a multi-tenant host to look. But your other one — a built-in scheduler provider, the cron job provider — I think is a great suggestion. We had an example for this maybe quite a long time ago, and this is something people have been asking for a little while. It's a pretty common use case. Thank you, Patrick, for filing this issue. This would be a great issue to take on, a great example provider to have, and a great first issue too — it could be done in Rust or in Go fairly well. Aditya, I love that you're interested in taking this one right off the bat. I'm happy to assign this one to you, or, depending on your bandwidth, if you wanted to get started on it, just let me know.
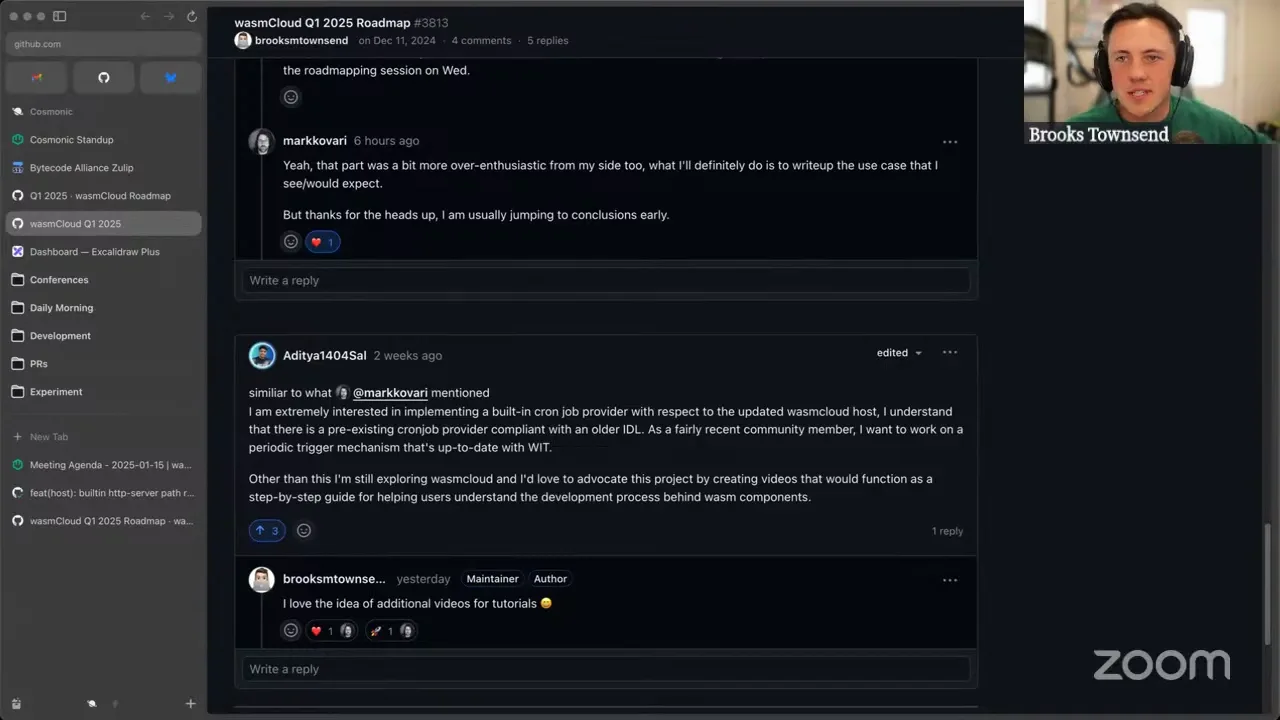
And then the other one, which I struggled a little to define in a ticket, because some of these are creative work — I love the idea of seeing videos for wasmCloud. I'm not sure if you were asking us to create videos, or if you were suggesting you were going to. Did you want to talk about that at all?
Aditya 31:38
I meant I would be making those videos.
Liam Randall 31:43
That would be awesome. I would love to see that, so happy to reflect that in an issue. But don't let that stop you. If we did a code-development livestream video or something, I think that would be awesome.
Aditya 32:09
I just got done with making a list of all the potential videos I could make. So if you're down for it, I'd be happy to share those ideas.
Liam Randall 32:24
Yeah, that would be awesome. Thanks. Looking forward to that, Aditya — we'll talk offline, but feel free to share that wherever you would like. So that is going through the discussion feedback on GitHub. I'd like to be a little more proactive about quarter two of 2025 after we get done with this roadmapping session — I'll open up the discussion for quarter two so we can start collecting ideas. Other than that, there's a good bit of other features, improvements, and documentation that made it onto the roadmap, and I want to talk about the background behind those issues and the criteria I used to put these together along with some of the other wasmCloud maintainers. Do folks have any other comments, questions, or concerns from the discussion?
Masood 33:48
Going back to the provider case again — I'm not talking about wasi-nn, but two quarters ago we agreed it's a good idea to have providers on the roadmap, provider development. I'm just reminding, and I think new providers warrant being on the roadmap, rather than not.
Liam Randall 34:27
Yeah, I agree. Do you mean the new provider that you'd like to develop in wasi-nn or messaging?
Masood 34:41
I created a discussion, and once it's concluded, I'm just saying that at a later date we should add that to the roadmap.
Liam Randall 34:55
I'm good with that. I don't feel married to the idea that what we get off this call is the final roadmap and we can't add anything else. Does anyone have any objections to bringing that one on after?
Bailey Hayes 35:17
No objections from me. I'm just posting a little update that we had in regards to wasi-nn, since it came up here. There are tons of different providers we could have, so it would be really helpful to help prioritize which ones folks are most excited about. Obviously, doing it via discussions and GitHub issues is probably the best way.
Liam Randall 35:48
Yeah, that sounds great. Thank you, Bailey. Masood, we'll keep an eye out for that, or let me know if you want to collaborate on that issue, but we can bring it on after the fact. We talked about the provenance and attestation RFC. It's worth talking through the structure of the roadmap: there aren't any specific dates or timelines or prerequisites on here. The standalone issues fall under three categories — documentation, new features and functionality, and improvements over existing functionality. All of these I try to organize loosely into different stages of work: "triage" means we have a little more information to gather before somebody should take it; "ready for work" means anybody should feel free to take it — especially anything marked good first issue is awesome to take off the roadmap; and "in progress" indicates someone's working on it, so go check first to avoid duplicate work.
Liam Randall 37:20
I'm just going to run top to bottom. We talked provenance and attestation. This draft — ingress for minimal footprint deployment — Colin, this is your RFC that you're putting together now, right?
Colin 37:40
Yes, thanks for pulling me back in. This is something I've been playing around with. I think it's really important that we get wasmCloud running in various lots of small places — like a CDN compute kind of platform. The open-source CDN compute platform is what I really think it has a chance to be, and that means we can't really just rely on Kubernetes to do network ingress. I really want to see what's the minimum we need to have in order to get a Kubernetes-like experience with just Envoy and wasmCloud, and take advantage of the universal control plane distributed computing we have with wasmCloud. So I played around with Envoy filters for the past few weeks. I actually got something somewhat working, but it's not very flexible, and it's very Envoy-specific.
Talking with Roman, if we just go with a really simple append-headers action from the reverse proxy and had wasmCloud be able to handle that, that would probably be the easiest, most performant, and most flexible way to do things. And if we decide it's not good enough, we can iterate on it rather than locking down into something like Envoy or nginx. It requires a few things: a different way of wasmCloud just listening for HTTP than it does currently. Ideally we no longer have an HTTP provider — wasmCloud would just listen on a port, register that with a reverse proxy, be part of an upstream pool, recognize the header we've designated, and then route to the incoming handler of the correct component. Nothing rocket science. The ultimate goal is that we don't want to be in the business of duplicating everything HTTP proxies and reverse proxies can do, because in the enterprise world especially, you're going to get very specific types of handling that all these reverse proxies and HTTP servers have been working on for who knows how long. So that's the proposal.
Liam Randall 44:02
Thank you, Colin. I love it. I really appreciate the way you laid out the MVP. We already have our wasmCloud built-in HTTP server, so we're getting closer and closer to this world where you can just have the host listen on a port and start to do that kind of routing. This looks a little bit more like header-based routing at the super-basic level. As long as we're doing this in a way that's not tightly tying wasmCloud to a specific reverse proxy, I'm all game for it. And Roman's actually really close to getting it working. When we're in the Kubernetes world, we're used to mapping a subdomain to, in an Istio-type world, a virtual service, which is all part of the Gateway API. So it's really a subdomain gets mapped to a header that gets mapped to a component. These host routes are meant to be dynamically durable in the proxy — this is how Kubernetes, Cilium, Istio, and the Gateway API work. So it's playing into the sweet spot of this stuff. I'm really excited to see how this looks, and I think this will speak really well to the folks who've been looking at wasmCloud for the more distributed edge scenario. Does anybody have any thoughts, questions, or concerns on this one?
Florian 45:38
Sorry for chiming in. Maybe one question — I didn't check it out, it's still on my to-do list, but there was also this RFC for shared components, and my first idea was to use maybe a shared HTTP provider as some sort of ingress controller. So the question is, what would be more preferable — the shared component, or this built-in host process doing it?
Liam Randall 46:07
So this is the same idea, trying to solve the same problem. My point is, the shared component might work for some basic cases, but then if you're not using Kubernetes — which usually has some Envoy in it anyway — you're going to be in this loop of chasing features. I kind of want to avoid that.
Florian 46:44
It's also because you mentioned Kubernetes — my to-do list is actually taking wasmCloud running in Kubernetes. So whatever solution we come up with, it should definitely work in Kubernetes as well. If you implement it in the host, and the host is running in Kubernetes, then most likely I have some sort of ingress controller or gateway in front of that. So I would have a gateway in front of a gateway.
Liam Randall 47:09
Yes, but it would work the same way. Any kind of rules you wrote for Istio or nginx in Kubernetes, they'd also be transferable to this. Bailey had a question, and I'll stop talking. If you don't mind, could we continue that discussion in the chat, because I know we have a lot of other issues to get through?
Liam Randall 47:54
Okay, one that I would like to propose again — I proposed this on the last roadmap and was shut down, sadly, but I really do think it's a great idea. Roman opened this quite a while ago: in the wash CLI, I think we should bundle wasmCloud and wadm as a library in the wash CLI, as long as it doesn't make the binary size prohibitively large. That's part of the spike reasoning. I think it would lead to a lot more consistent local developer experiences, because we're not downloading two separate binaries from GitHub to actually run wadm and wasmCloud. We're just embedding those Rust libraries in the wash CLI and running them in the same process. I think this would give us a lot more control over the process lifecycle. As per our previous discussions, wash is very much a developer tool, a local workstation tool, not for standing up production deployments. We can retain the ability to download separate binaries for different versions, but the primary mode — when you just run wash up or wash dev — would be this nice single binary that runs everything.
There was a question in the chat about embedding NATS too. That one's a little harder, but I think we can include the NATS binary and basically exec that at runtime. We have precedent for doing this. That would make wash, albeit a little larger, a kind of all-in-one single binary over a bunch of separate ones. Do folks have reservations about this one?
Bailey Hayes 50:35
I think there's a question around what it would look like to have two builds — what if there's one that includes wash, and through maybe Rust features or something you can turn off the embedded stuff?
Liam Randall 50:54
I think that makes sense. The concern around the size and operational footprint of the CLI makes a ton of sense. So my proposal for this feature is that during this quarter we do the spike to figure out how big this makes the binary size, does it bloat it, does it work better, does it actually improve the developer experience. And if so, then we can get the work done for it.
Mark 51:38
Yeah, Brooks, the only thing I would appreciate is that you have a scapegoat in hand — a toggle to remove everything and we go back to where it was. Other than that, let's do it and test it and see what impact. A simple toggle, a feature, an environment variable, whatever — I really don't care how to disable it, just in case.
Liam Randall 52:06
I like that idea. Okay, let's keep moving. Next on the feature work — we should move this one into "in progress." This one is an epic; thank you, Bailey, for adding additional information here. The WASI proposals and WASI standards are a huge part of wasmCloud, a huge part of the feature set we need to support. Especially with our addition of feature flags lately, we should be aiming to integrate with WASI Preview 3 as soon as we reasonably can, probably behind an experimental feature to make sure we don't hurt anybody on the developer experience side. Let's track the Bytecode Alliance project, and as we need to, let's make sub-issues on this epic for the tasks we need to do on the wasmCloud side. Bailey, Victor, I know you folks are working on some of the WASI Preview 3 efforts. Is there any more context we should add here?
Bailey Hayes 53:30
Well, I added it, so I'll tell you why I think it's important. I haven't made the sub-issues yet, but I want us to build out some workflow so that we can do some integration without rolling it out, right? Because it's not going to be stable for maybe at least another two months, and us integrating the changes that happen — making sure I'm not seeing any breakage — is going to be really important. So having some issues to track that, having some documentation for the brave explorers that want to join the bleeding edge, will be really important. Having an epic-style tracking issue will help us keep it all together, because there's going to be a lot of little things that change in a world where everything is essentially async and supports streams and futures natively. I think we'll see lots of minor updates that aren't necessarily breaking changes, but they'll all roll up and be derived from this. And if you're interested in working upstream, please reach out to Victor and me. We just did an async standup in the Bytecode Alliance Zulip, and if you're looking for issues, I pointed out a few that would be good for anybody.
Liam Randall 55:11
Awesome, thank you. I think it belongs on here. Moving forward, the next one — and this goes back to some of Masood's feedback in the discussion — we've demonstrated this library called wash, the WebAssembly bridge testing framework for Go components. One piece of documentation and examples that I don't think we currently have is how to write components to mock WebAssembly interfaces. In this testing framework, you can run your Go component code as native Go code, so you can use debuggers and tests like you're normally used to for Go, but for components like HTTP, key-value, messaging, and unique custom interfaces, those you'll actually need to either compose away or mock. So I think a huge piece of documentation and enhancement would be how to write your own components for this. Let's just keep building on these testing frameworks. This should really help for any use cases where we're testing custom interfaces — your component depends on another component, and you need to get that tested. We're running a little low on time, so I'm not going to pause for every issue, but folks, please feel free to raise your hand if you had more you wanted to discuss.
Liam Randall 57:20
The next one I captured on the roadmap — I probably owe you all a little more detail here. People who are running wasmCloud in real environments today, moving from QA dev to production, generally come across wanting to constrain capability providers with resource limits. With components, there are all kinds of controls within Wasmtime where we can say no component can take up more than this much memory, you can only run two at a time, the component can't be more than 50 megabytes. But we don't have the same restriction around capability providers — they are native binaries that execute on the machine. So what I think we need to address this quarter, as soon as we can, is support for externalizing those providers from the wasmCloud host. What I mean is essentially them operating in the same mode they are today, but for people running capability providers on their own machine or in Kubernetes, it would be really powerful to run a capability provider in a separate Kubernetes container or Docker container and then constrain the CPU and memory from there. This is worth an RFC, since it's an additional mode to run providers in. I'm fine with pulling this one off until we can add a little more detail and triage. The other big story for providers, with the advancement of WASI Preview 3 and a native async model, is that we have more leverage to try capability providers as WebAssembly components — long-running, stateful WebAssembly components — where again you can constrain the resources with Wasmtime, with the sandbox. The way we get around this now is, if you're running in these environments, you run a wasmCloud host and then run that provider in that container so you can constrain the resources. We have workarounds for it now, but a more native solution is the idea.
Liam Randall 1:01:01
Okay, maybe we can bring this one up in a future community meeting, in the same vein as bundling wasmCloud in wash. Simplifying the default wasmCloud platform deployment — this is our Helm chart that we have in the wasmCloud repo. The thing that causes a bit of friction is how we subsume a bunch of Helm charts as part of our platform Helm chart. There's not really anything wrong with that, but I think it would be really beneficial — and Bailey, you opened this one — to essentially hide the NATS requirement where possible from people who are deploying in Kubernetes environments. When you're deploying the wasmCloud Helm chart, it would be really nice for people to be able to focus on deploying wasmCloud and not deploying this other service we depend on with NATS. When we're running NATS for wasmCloud, we know some of the parameters, so we can essentially embed this NATS piece into what we deploy, with the caveat that you can always turn that off if you have your own existing NATS deployment. Jochen, I know you have your own NATS deployment already and you hook wasmCloud into that, right? We don't want to over-prescribe here.
Jochen 1:02:41
We had just the fact that people then have very complex NATS setups — they have different JetStream domains and so on — which might cause trouble because the wasmCloud operator in particular makes some assumptions about those. If it's deployed in parallel, that's kind of working out of the box, that's fine. But as soon as it comes to it, it also needs to recognize that there are more complex NATS setups.
Liam Randall 1:03:55
Yeah, absolutely. I think this would be the default, but purely a side option, because wasmCloud needs a couple of KV buckets and streams, a JetStream domain, and for its leaf domain to be different. So making sure all that can be configurable and slot into a more complex NATS deployment. When we're proposing this, I may reach out to you to make sure that in that kind of testing, it works for your NATS deployment. I know we have some folks like Dwayne who comes in every so often who has a complex NATS deployment.
Masood 1:04:55
I just wanted to do a bit of a reminder, or maybe a check, with due respect to Bailey. Originally when this was proposed — which I proposed — it was because we already have multiple Helm charts. The idea was having a Helm chart that allows the operator to create a bespoke configuration and then deploy the entire platform. That's why I called it the wasmCloud platform chart — the entire platform with all of its dependencies and the configuration they need. The moment we say we want to simplify it, we kind of lose that. So I'm just reminding that that was the original intent of having everything included.
Bailey Hayes 1:06:05
I think this is taking exactly what you did and just continuing to extend that effort. It really helped to have a single way to install the wasmCloud platform. Where people are having trouble right now, at least what I've observed, is that the NATS chart specifically has so many different knobs to configure. When people are running that kind of stuff in production and they're already familiar with NATS, they have a totally different setup. They don't use that chart.
Masood 1:06:53
What I have observed, Bailey, is the fact that — and history is history, we can't do anything about it — but the fact that we have a chart that is called wasmCloud host, and the host is called wasmCloud host, so when they read documentation, that's where some of these improvements could be applied, because they mix up these things. I have seen multiple users coming back saying, do I need to deploy wasmCloud host or don't I need to deploy wasmCloud host? Mostly they get confused there. But you're speaking to customers, so you might have a lot more interactions.
Bailey Hayes 1:07:37
Yeah, I think there are different personas here — folks kicking the tires for the first time in an open-source environment versus a more enterprise-y world. But you're spot on; I think that's another source of confusion. I will say that having it where you can choose to deploy the host versus the operator is a really important feature we provide, because there are a lot of places that, when they're getting started, cannot use custom resources or CRDs or install an operator. When they just want to load the Hello World, all they really want is a host. So if we change what we embed, then we can simplify what we have to install. That's the motivation — continuing down that path of having that all-in-one kind of experience.
Yordis 1:09:28
Two things. One, I noticed the Grafana Helm and the Prometheus Helm also have this — do I deploy Grafana with it or not? It's common for these bundles to say, hey, I can deploy this for you and it's going to work. So if you want to deploy and have the opportunity to have any default, I think it would be prudent to have that instead of being bound to the NATS Helm chart directly. Two, every environment is different. Although I understand the problem, how did we collect the use cases and what people are complaining about? Bailey, this is why a long time ago I suggested always having tools that automatically sync every question and complaint people ask into a blob of "here is the context," because I'm failing to understand what for NATS is actually a problem. Is it networking? For me, using NATS, I don't know what I'm doing most of the time because it's so complex, especially in enterprise where you have to deal with different authorization and stuff that's just over my head. That's what I'm trying to figure out, because otherwise we'll go into "what will be the optimization, what will be the changes" if we don't know what the pain points are today precisely. And maybe some of those pain points is actually documentation — people need to understand that, because it's just core to the system.
Bailey Hayes 1:11:28
I would argue for wasmCloud that NATS is a key part of the platform — it is the platform — but there isn't necessarily a huge reason for the person building on top of wasmCloud to need to know all of those details, if we do the right things and have the right documentation. At least that's where I'd like to go. It's like in Kubernetes when you do an install using something like kops — you don't typically read the documentation for the first roll, but then when you're rolling out in production, that's when you get into doing that next level. So what I'm asking if we could consider is bringing out that initial thing you have to read and get expert at, making the default very simple — it just works for wasmCloud. It's not trying to solve your entire NATS data plane for everything at your company, just what wasmCloud needs, and then making it so the more advanced users continue down the path they're basically on.
Yordis 1:12:41
Yeah, this was literally related to the same documentation conversation, Bailey, about some of the stuff for NATS — either you take ownership of it or you don't, that's up to you. But it seems that we, more and more over time, need to take ownership of documenting for NATS' sake. Because at that point we lose control over the experience, and in the worst case, we lose the opportunity to see what people are actually having trouble with.
Liam Randall 1:13:37
Okay, I think it's probably worth a little bit more evidence, if we can gather it for that issue, to say here's where people are running into trouble, and then get that fixed.
Liam Randall 1:13:59
All right. The next three on the improvements side — I filed each of these, but each came from talking with other contributors on the wasmCloud side. I talked with Lucas, who's been in the community call quite a bit doing the demos for the benchmarking tests and some of the wasmCloud Go work. A lot of what these three improvement tickets center around is the formalization and stabilization of our APIs. There are a couple of places where we were a little inconsistent with our protocols and our CloudEvents. This is such a small thing, but it adds up over time. With our CloudEvents, there are places where we include the host ID as host_id, places where we include it as id, and places where we don't include it at all and leave it on the source field from the CloudEvent itself. I think it should be on the source field — there's a whole philosophy around CloudEvents of who is the source. But calling attention to where we specify a host ID versus an ID is this first one.
This next one is probably worth more discussion: defining structures in a language-agnostic codegen format — a language-agnostic IDL. This could be WIT — I don't have any opposition there — or it could just be a JSON schema. I don't really mind what it is, but now that we have the set of tooling in Rust and Go, coming soon in TypeScript, it would be awesome to define our event structures in an IDL, then codegen those structures in specific languages and have our documentation update automatically. The next one is a small one too: we have control interface operations and events where we note provider_ref, image_ref, component_ref, image reference. We should just standardize on this, because some of these event structures were originally created before you had to have an image reference — you could just load it from bytes — but that's not the case anymore. So for all of these, it's just formalizing our types and structures just like we did for the control interface API as we were leading up to 1.0. These improvements are going to make it easier for us to write additional tools, do testing, and have understandable APIs. As we're solidly approaching a year of being on 1.0, I'd really like to re-examine some of these structures and lean into where the project is now — a pretty mid-level maturity. Please feel free to file issues if you notice these kinds of protocol inconsistencies.
Yordis 1:18:52
I was about to say — pat yourself on the back. You mean the CNCF? You moved to a different stage. That speaks to the outcome of it. Don't be shy about it; you earned it.
Liam Randall 1:19:09
Big shoes to fill, all right. That sounds good. Moving right along, some other feedback we've gotten — Lars, did you file this issue? Producing the secrets NATS KV image. The Docker build is an image that's in the wasmCloud repository, which is something we've needed for a little while. The secrets NATS KV backend is probably the easiest one to run out of the box, so it would be a really beneficial binary to run in a container. We have a Docker container, and Lars has put in a couple of contributions to make sure it has CA certificates and things like that. But we don't actually produce this container — we have the Dockerfile, but we don't build and publish the container. I think we should just do this one; it's an artifact that we have, so we should publish it.
Liam Randall 1:20:34
Moving on — feature requests for this one, which is why I added this issue, to support a built-in HTTP client capability provider. The same way that we have the built-in HTTP server, which supports all the same configuration options as the binary provider and you can hot-swap them, having an off-by-default but toggleable HTTP client would be really nice — especially with this idea of all these components that are essentially HTTP proxies, being triggered by HTTP and making their own requests. This would make our wash dev experience easier too, because we have yet another built-in to lean on. So this would be an in-process one in the host, similar to the server.
Masood 1:21:48
Just to be efficient — knowing that basically the next revision of HTTP is coming up and simplifies the interface, shouldn't we defer this and implement it then, rather than doing it now and then redoing the work?
Liam Randall 1:22:16
It's a good question. After looking at the HTTP server built-in, it is largely the same code we use for the provider, so I don't feel strongly either way. There will certainly be a lot of work that comes with supporting WASI Preview 3 initially, maybe alongside Preview 2. It's probably worth considering the new HTTP interface and how different it would be. I don't think we have to block on it. Bailey, do you have any thoughts? I know the new HTTP interface is super nice. Should we hold on this one for a little while? How close is Preview 3 for us to do it?
Bailey Hayes 1:23:30
We have an aggressive target of Q1, but I would say that's a very good target. I think we learned a lot last time. There are several unknown unknowns, essentially, in the integration with the guest toolchains. So we'll know more once we get a little further with that — hopefully that type of integration starts in about two weeks. Right now I don't have great fidelity on when WASI Preview 3 lands until we start getting feedback from folks like the Go Gophers, .NET, and the Python folks. For this specific issue, it's definitely true that instead of having an incoming and outgoing handler, now you just have a handler with bidirectional streams. But I would say I wouldn't wait, because the code we write to make that real is going to be the same code, basically with a different interface once we put it on Preview 3 — so it'll just get prettier over time and hopefully not duplicate work.
Liam Randall 1:25:09
Thank you for asking the question, Masood, and thank you, Bailey, for the context. I still kind of don't feel strongly either way. I saw your thumbs up, so I'm taking that as all good.
Masood 1:25:25
I just commented because, again, if you have limited time between all of us, then maybe we should spend it somewhere else. But Bailey saying that most of the code base is going to be the same, so it's not going to be much of an effort to port it — that's great news.
Liam Randall 1:26:00
Okay. The other one we've had on the backlog for quite a bit is a big old refactor: consolidating wash CLI and wash lib. Originally we split these up for reusability, but there's no real reason for these to be separate. We actually have the wash crate now, and we should probably be using that to do the separation. It would be really nice, especially on the maintainer side for releasing, to not have to release a library crate and then a CLI crate just to put out a new feature in wash. This one certainly has the potential to be a rage-coding project — somebody gets too tired of it and combines them. The ask is that if someone takes this, let's create a new crates/wash directory where we combine these, do a little set of testing for a while, and update our pipelines while maintaining the old versions individually. This is a big task, and we'll want to talk about it again in a community meeting before we take it on, so we can feature-freeze wash for a week or two. The other improvements are smaller pieces of work — replacing the --rpc and --ctl flags with --nats for wash up and wash dev, which will cut down the CLI flags and environment variables we have to handle. There's a good old bug report for wash hanging if you run wash down in a different terminal window. And avoiding building all of the providers on CI — we have a recent PR, thank you Roman, to rework the crate features in the wasmCloud project so you can build individually just one provider from the top level, or just wasmCloud, or specifically exclude them. So if you only make a change in the NATS object store provider, then wasmCloud shouldn't rebuild — just the NATS object store provider. These are all great first issues in the "ready for work" improvement tab. This last one — emitting an error when the logging buffer is full — is actually something I haven't reproduced, but it's certainly a concern for folks running wasmCloud at scale.